«`html
Эффективное выравнивание больших языковых моделей (LLM) с человеческими инструкциями
Выравнивание больших языковых моделей (LLM) с человеческими инструкциями представляет собой критическую задачу в области искусственного интеллекта. Текущие LLM часто испытывают трудности в генерации ответов, которые одновременно точны и контекстуально соответствуют инструкциям пользователя, особенно при использовании синтетических данных. Традиционные методы, такие как дистилляция моделей и человеко-аннотированные наборы данных, имеют свои ограничения, включая проблемы масштабируемости и отсутствие разнообразия данных.
Практические решения и ценность
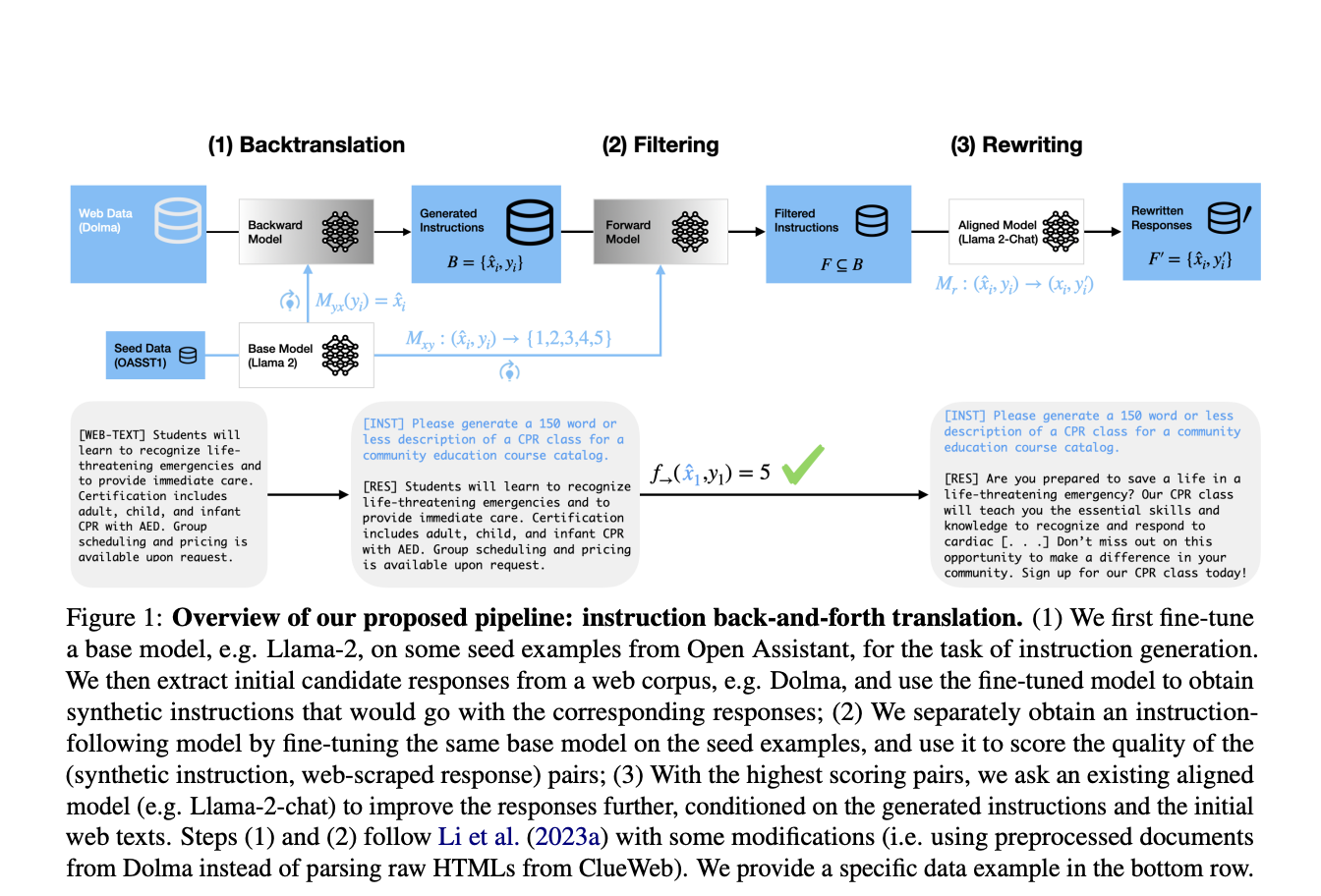
Новый метод «instruction back-and-forth translation» представляет собой значительное достижение в области выравнивания LLM с человеческими инструкциями. Путем объединения обратного перевода с переписыванием ответов исследователи разработали масштабируемый и эффективный подход, который улучшает производительность моделей, следующих за инструкциями. Это важное достижение для области искусственного интеллекта, предлагающее более эффективное и точное решение для выравнивания инструкций, что необходимо для применения LLM в практических приложениях.
Значимость нового метода
Новый метод достигает значительных улучшений в производительности моделей по различным бенчмаркам. Модели, настроенные с использованием набора данных Dolma + фильтрация + переписывание, достигают победного результата в 91,74% на бенчмарке AlpacaEval, превосходя модели, обученные на других распространенных наборах данных, таких как OpenOrca и ShareGPT. Кроме того, он превосходит предыдущие подходы, используя данные из ClueWeb, демонстрируя его эффективность в генерации высококачественных и разнообразных данных, следующих за инструкциями.
Заключение
Внедрение этого нового метода для генерации высококачественных синтетических данных является значительным прорывом в выравнивании LLM с человеческими инструкциями. Путем объединения обратного перевода с переписыванием ответов исследователи разработали масштабируемый и эффективный подход, который улучшает производительность моделей, следующих за инструкциями. Это важное достижение для области искусственного интеллекта, предлагающее более эффективное и точное решение для выравнивания инструкций, что необходимо для применения LLM в практических приложениях.
«`

























