«`html
Расширение возможностей мультимодального искусственного интеллекта с помощью CuMo
В настоящее время использование больших языковых моделей (LLM) таких, как GPT-4, вызывает волнение вокруг их улучшения с помощью мультимодальных возможностей для анализа визуальных данных в дополнение к тексту. Однако ранее создание мощных мультимодальных LLM сталкивалось с проблемами масштабирования и поддержания производительности. Для решения этих проблем исследователи черпали вдохновение из архитектуры «сети экспертов», широко используемой для масштабирования LLM путем замены плотных слоев модулями экспертов.
Решение через сеть экспертов
В подходе с использованием сети экспертов на входы не подается одна большая модель, а множество более мелких экспертных подмоделей, каждая из которых специализируется на подмножестве данных. Сетевой маршрутизатор определяет, какие эксперты должны обрабатывать каждый входной пример, что позволяет масштабировать общую емкость модели более эффективным способом.
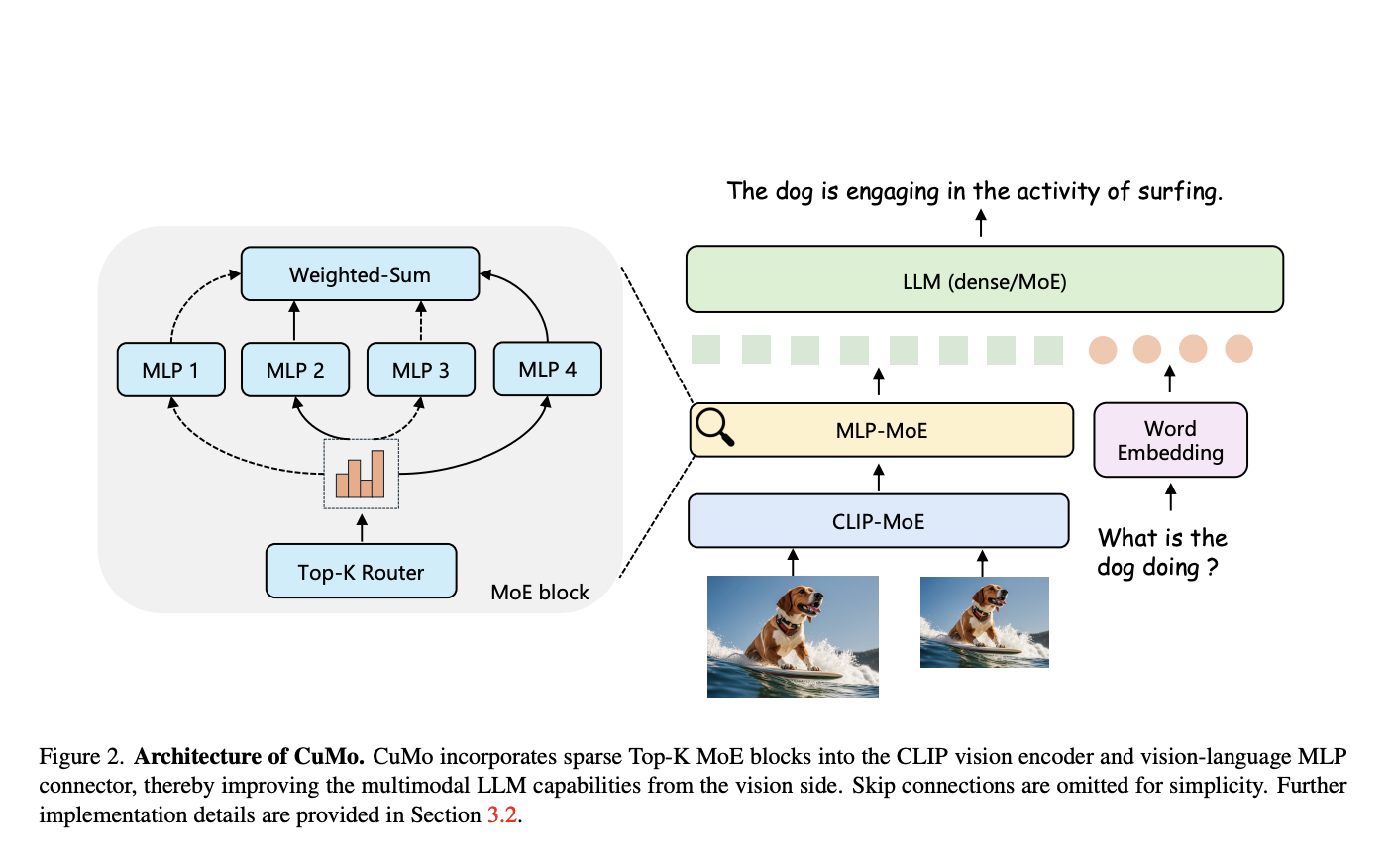
В их подходе исследователи интегрировали разреженные блоки экспертов визуального кодера и визуально-языкового соединителя мультимодального LLM. Это позволяет различным экспертным модулям параллельно обрабатывать разные части визуальных и текстовых входов, а не полагаться на монолитную модель для анализа всего.
Основная новация заключается в концепции «co-upcycling». Вместо того чтобы обучать разреженные модули экспертов с нуля, они инициализируются из предварительно обученной плотной модели перед доводкой. Это обеспечивает лучшую отправную точку для специализации экспертов во время обучения.
Ступенчатый процесс обучения
Для обучения CuMo использует три ступени:
- Предварительное обучение только визуально-языкового соединителя на данных изображений-текста, например, LLaVA, для выравнивания модальностей.
- Предварительная доводка всех параметров модели на данных описания из ALLaVA для предварительного прогрева всей системы.
- Наконец, доводка с визуальными инструкциями из наборов данных, таких как VQAv2, GQA и LLaVA-Wild, вводя разреженные блоки экспертов вместе с вспомогательными потерями для балансировки нагрузки экспертов и стабилизации обучения.
Этот всесторонний подход, интегрирующий разреженность сети экспертов в мультимодельные модели через co-upcycling и тщательное обучение, позволяет CuMo эффективно масштабироваться по сравнению с простым увеличением размера модели.
Исследователи оценили модели CuMo на ряде бенчмарков визуального вопросно-ответного тестирования, таких как VQAv2 и GQA, а также на вызовах мультимодального рассуждения, таких как MMMU и MathVista. Их модели, обученные исключительно на общедоступных наборах данных, превзошли другие передовые подходы в рамках тех же категорий размера модели.
Эти впечатляющие результаты подчеркивают потенциал разреженных архитектур экспертов в сочетании с co-upcycling в разработке более способных и эффективных мультимодальных ИИ-ассистентов. Поскольку исследователи опубликовали свою работу в открытом доступе, CuMo может проложить путь для нового поколения ИИ-систем, способных беспрепятственно понимать и рассуждать текст, изображения и не только.
Больше информации можно найти в документе и на GitHub.
«`

























