Оптимизация Q-функции: Преобразование ИИ для улучшения взаимодействия с пользователями
Оптимизация больших языковых моделей (LLMs) в соответствии с человеческими предпочтениями является важной задачей в области искусственного интеллекта. Однако существующие методы обучения с подкреплением сталкиваются с серьезными проблемами.
Проблемы существующих методов
Методы, такие как Proximal Policy Optimization (PPO), требуют большого объема онлайн-выборок, что приводит к высоким вычислительным затратам и нестабильности. В то же время, методы оффлайн-обучения, такие как Direct Preference Optimization (DPO), имеют трудности с задачами, требующими многопроцессного мышления, например, решением математических задач или генерацией сложного кода.
Решение: Оптимизация Q-функции
Исследователи из ByteDance и UCLA предложили Direct Q-function Optimization (DQO), чтобы преодолеть эти проблемы. DQO рассматривает процесс генерации ответов как Марковский процесс принятия решений (MDP) и использует Soft Actor-Critic (SAC) для более структурированного и пошагового обучения.
Преимущества DQO
Ключевая особенность DQO заключается в том, что он может выявлять и оптимизировать правильные шаги мышления даже в частично правильных ответах. Например, в решении математических задач DQO присваивает более высокую ценность точным шагам и штрафует за ошибки, что позволяет постепенно улучшать процесс мышления.
Техническая реализация и практические преимущества
DQO интегрирует функции политики и ценности, обновляя свою Q-функцию на основе Soft Bellman Equation. Это позволяет избежать необходимости в онлайн-выборках и снижает вычислительные затраты. DQO также может обучаться на несбалансированных и негативных выборках, что повышает его устойчивость.
Результаты и выводы
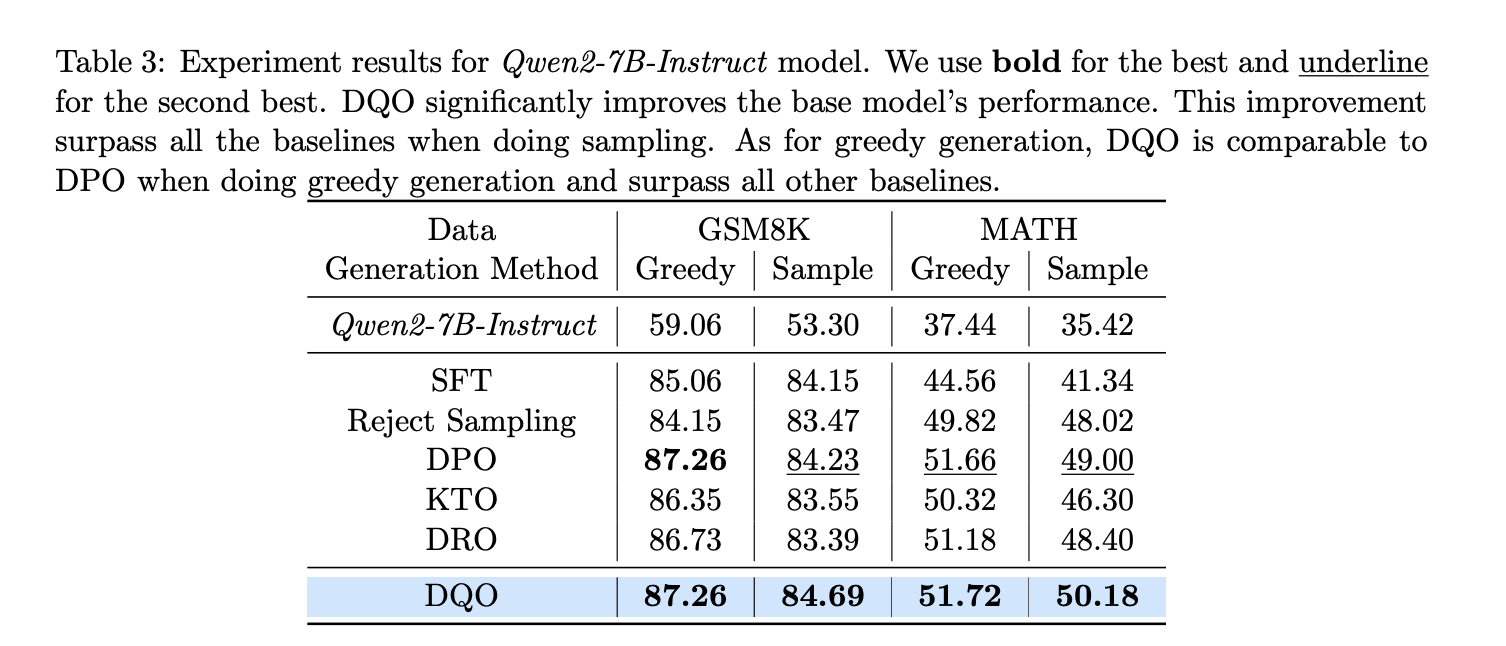
Эксперименты с DQO на математических наборах данных, таких как GSM8K и MATH, показали его эффективность. DQO значительно превзошел другие методы, улучшив результаты на 28% в GSM8K и на 1.18% в MATH.
Заключение
Оптимизация Q-функции (DQO) предлагает продуманный подход к обучению с подкреплением для согласования LLM. Его способность интегрировать процессные награды и стабилизировать обучение делает его практическим решением для задач, требующих многопроцессного мышления.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение из множества доступных вариантов ИИ.
- Внедряйте ИИ постепенно, начиная с малого проекта и анализируя результаты.
Получите помощь
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ-ассистента в продажах, который помогает отвечать на вопросы клиентов и снижает нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























