“`html
Agentless: Искусственный интеллект без агентов для автоматического решения проблем разработки программного обеспечения
Программная инженерия – это динамичная область, фокусирующаяся на систематическом проектировании, разработке, тестировании и поддержке программных систем. Недавние достижения в области больших языковых моделей (LLM) революционизировали эти процессы, позволяя более сложную автоматизацию задач разработки программного обеспечения. Увеличение возможностей LLM привело к их широкому применению в различных задачах программной инженерии, предлагая новые эффективности и возможности, ранее недостижимые с помощью традиционных методов.
Решение практических проблем
Однако возникла значительная проблема в контексте автоматизации задач программной инженерии. Сложность и стоимость использования автономных агентов на основе LLM для выполнения этих задач стали очевидными. Эти агенты предназначены для самостоятельного использования инструментов, выполнения команд и планирования действий на основе обратной связи от окружающей среды. Однако сложная природа использования инструментов и ограничения в принятии решений текущих LLM часто приводят к неэффективности в работе и увеличению операционных расходов. Решение этих проблем критично для продвижения области и сделает автоматизацию на основе LLM более практичной и доступной.
Практические решения
Текущие методы решения проблем программной инженерии в основном включают автономных агентов LLM. Эти агенты, оснащенные различными инструментами и возможностями, пытаются итеративно решать проблемы, выполняя действия, наблюдая за обратной связью и планируя последующие шаги. Хотя этот подход отражает итеративную природу человеческого решения проблем, он также наследует несколько ограничений. Необходимость сложного проектирования и использования инструментов может привести к ошибкам и неточным результатам. Более того, процесс принятия решений, делегированный этим агентам, может привести к неоптимальным действиям, особенно когда агенты должны фильтровать нерелевантную или вводящую в заблуждение информацию.
Инновационное решение
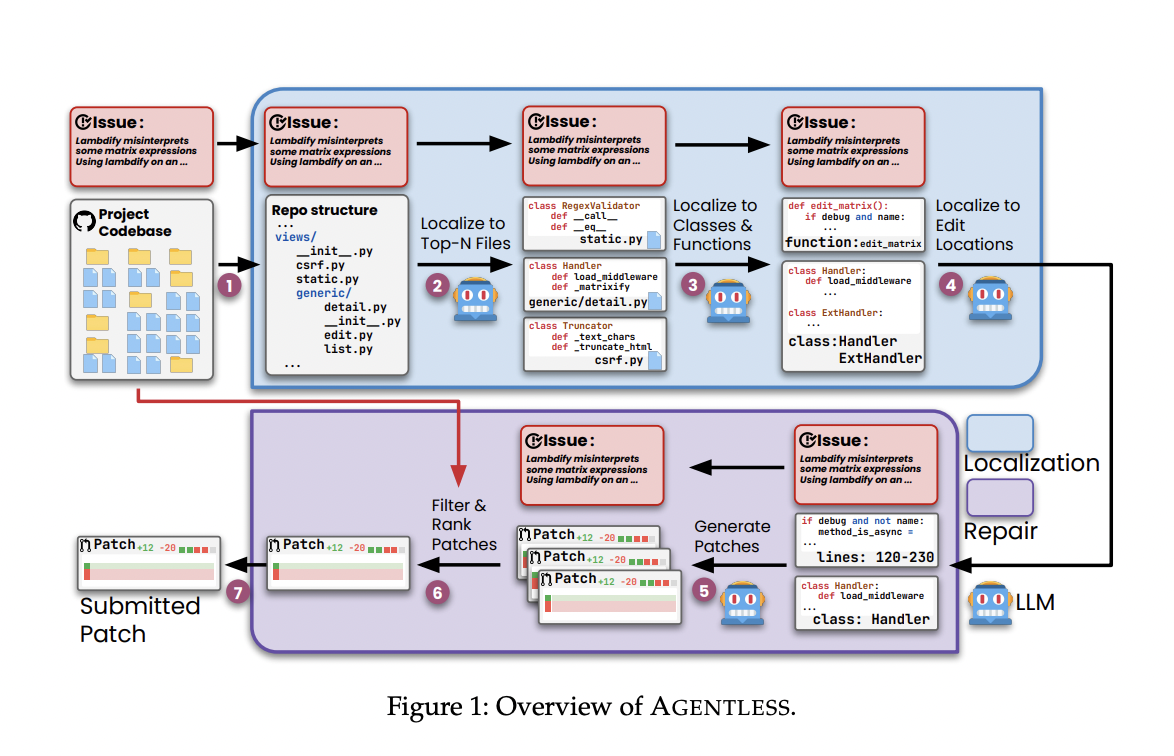
Для решения этих проблем исследователи из Университета Иллинойса в Урбане-Шампейне представили AGENTLESS – инновационный подход без агентов, направленный на упрощение решения проблем разработки программного обеспечения. AGENTLESS отходит от традиционной зависимости от автономных агентов, предпочитая упрощенный двухфазный процесс локализации и исправления. Этот метод устраняет необходимость в автономном принятии решений LLM или использовании сложных инструментов, сосредотачиваясь на более простом и интерпретируемом подходе.
AGENTLESS работает через тщательный двухфазный процесс. Он идентифицирует конкретные файлы, классы, функции и строки кода, требующие модификации во время фазы локализации. Этот иерархический подход преобразует кодовую базу проекта в структуру, напоминающую дерево, чтобы выявить подозрительные файлы. Затем он сужается до соответствующих классов и функций в этих файлах, прежде чем окончательно определить конкретные места для редактирования. Этот метод значительно уменьшает сложность и объем кода, который необходимо проанализировать, что делает процесс более эффективным.
AGENTLESS генерирует несколько кандидатов на исправление для выявленных мест редактирования в фазе исправления. Используя простой формат diff, создаются правки поиска/замены для исправления проблемы. Эти патчи проходят фильтрацию для удаления тех, у которых есть синтаксические ошибки или не прошли регрессионные тесты. Оставшиеся патчи затем ранжируются с помощью большинственного голосования, и лучший патч выбирается для представления. Этот метод использует возможности LLM, не требуя от них автономного планирования будущих действий или использования сложных инструментов, сохраняя тем самым простоту и экономичность.
Производительность AGENTLESS была оценена с использованием стандартного бенчмарка SWE-bench Lite, широко признанного для тестирования способности решать реальные проблемы программной инженерии. AGENTLESS достиг впечатляющих результатов, решив 82 из 300 проблем, что составляет процент выполнения 27,33%. Он достиг этого с самой низкой средней стоимостью $0,34 на проблему, значительно ниже, чем у других методов. Эта производительность обусловлена способностью метода эффективно локализовывать места редактирования и генерировать эффективные патчи, избегая сложностей, связанных с автономными агентами.
Кроме того, AGENTLESS продемонстрировал свою способность решать уникальные проблемы, которые другие открытые агенты не могли решить. Он предоставил решения для 15 уникальных проблем, подчеркивая эффективность своего простого и интерпретируемого подхода. Даже при сравнении с высокопроизводительными коммерческими решениями AGENTLESS предложил уникальные исправления, демонстрируя свой потенциал в качестве дополнительного инструмента в области автоматизации разработки программного обеспечения.
В заключение, AGENTLESS представляет собой убедительную альтернативу сложным автономным агентам на основе LLM в программной инженерии. Сосредоточившись на упрощенном двухфазном процессе локализации и исправления, он решает врожденные проблемы использования инструментов и принятия решений в текущих методах. Исследование Университета Иллинойса в Урбане-Шампейне подчеркивает потенциал этого подхода для переустановки базового уровня и вдохновляет на будущую работу в важном направлении автономной разработки программного обеспечения. Эта инновация прокладывает путь для более доступных, эффективных и экономичных решений в развивающейся области программной инженерии.
“`

























