Решения ANNS в области искусственного интеллекта
Практические решения и ценность
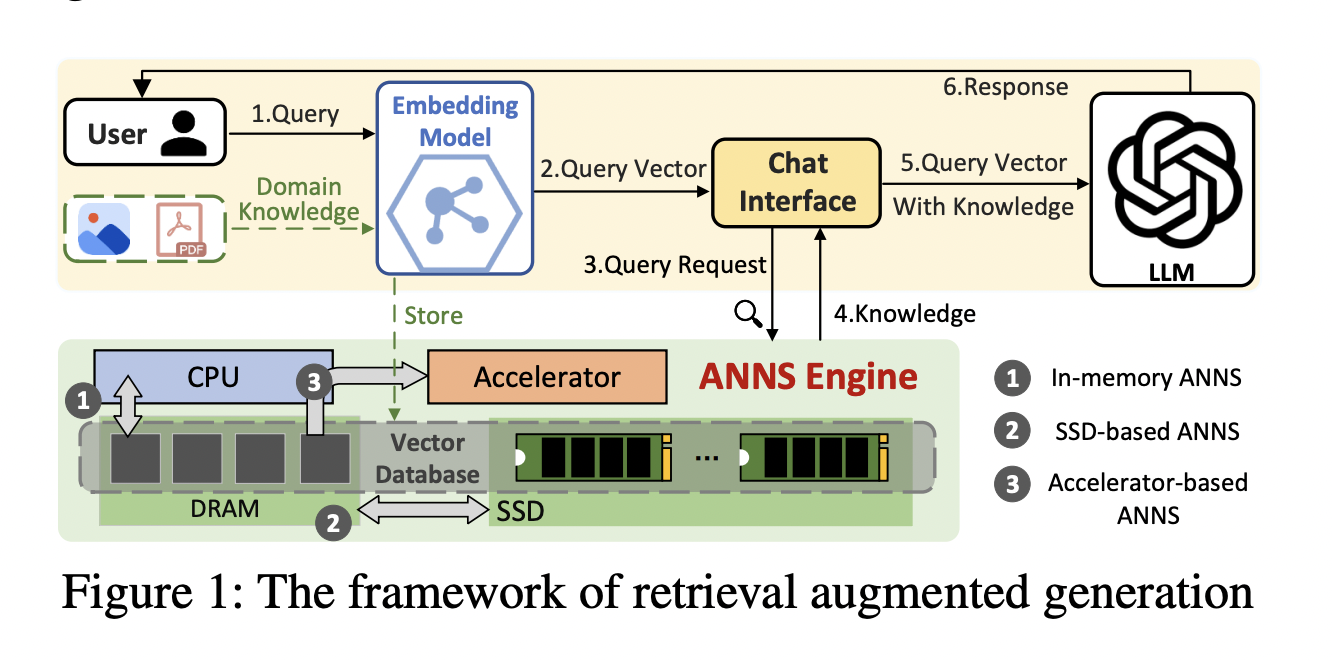
Поиск приближенных соседей (ANNS) является критической технологией, используемой в различных приложениях на основе искусственного интеллекта, таких как майнинг данных, поисковые системы и системы рекомендаций. Основная цель ANNS заключается в идентификации ближайших векторов к заданному запросу в пространствах высокой размерности. Этот процесс необходим в ситуациях, где быстрое нахождение похожих элементов критично, например, в распознавании изображений, обработке естественного языка и системах рекомендаций большого масштаба. Однако с увеличением размеров данных до миллиардов векторов системы ANNS сталкиваются с серьезными вызовами в плане производительности и масштабируемости. Эффективное управление этими наборами данных требует значительных вычислительных и памятных ресурсов, что делает процесс чрезвычайно сложным и дорогостоящим.
Основная проблема, над которой работает данное исследование, заключается в том, что существующим решениям ANNS часто требуется помощь для работы с огромным масштабом современных наборов данных при сохранении эффективности и точности. Традиционные подходы не подходят для данных масштабов в миллиарды, поскольку требуют большого объема памяти и вычислительной мощности. Техники, такие как инвертированный файл (IVF) и графовые методы индексации, были разработаны для преодоления этих ограничений. Однако часто они требуют использования памяти в терабайтах, что делает их дорогостоящими и требовательными к ресурсам. Более того, вычислительная сложность проведения массовых расчетов расстояний между высокоразмерными векторами в таких больших наборах данных является узким местом для текущих систем ANNS.
В настоящем состоянии технологии ANNS методы, требующие много памяти, такие как IVF и графовые индексы, часто используются для структурирования пространства поиска. Хотя эти методы могут повысить производительность запросов, они также значительно увеличивают потребление памяти, особенно для больших наборов данных, содержащих миллиарды векторов. Иерархическая индексация (HI) и квантизация продукта (PQ) оптимизировали использование памяти за счет хранения индексов на твердотельных накопителях и использования сжатых представлений векторов. Однако эти решения могут вызвать серьезное снижение производительности из-за накладных расходов, введенных операциями сжатия и разжатия данных, что может привести к потере точности. Существующие системы, такие как SPANN и RUMMY, продемонстрировали разный уровень успеха, но остаются ограниченными из-за неспособности сбалансировать потребление памяти и вычислительную эффективность.
Исследователи из Университета науки и технологий Хуадзюн и Huawei Technologies Co., Ltd представили FusionANNS, новую архитектуру совместной обработки CPU/GPU, разработанную специально для наборов данных миллиардного масштаба для решения этих проблем. FusionANNS использует инновационную многоуровневую структуру индекса, которая использует преимущества как процессоров, так и графических ускорителей. Эта архитектура позволяет проводить высокопроизводительные и быстродействующие приближенные поиски ближайших соседей с использованием только одного графического ускорителя начального уровня, что делает ее экономически выгодным решением. Подход исследователей сосредоточен на трех основных инновациях: многоуровневой индексации, эвристическом переранжировании и дублировании ввода-вывода с учетом избыточности, которые минимизируют передачу данных между CPU, GPU и SSD, чтобы устранить узкие места в производительности.
Многоуровневая структура индексации FusionANNS позволяет совместную фильтрацию CPU/GPU, сохраняя исходные векторы на SSD, сжатые векторы в памяти высокой пропускной способности графического ускорителя (HBM) и идентификаторы векторов в памяти хоста. Эта структура предотвращает избыточный обмен данных между CPU и GPU, что значительно сокращает операции ввода-вывода. Эвристическое переранжирование дополнительно повышает точность запросов, разбивая процесс переранжирования на несколько мини-пакетов и используя механизм обратной связи для завершения ненужных вычислений заранее. Окончательный компонент — дублирование ввода-вывода с учетом избыточности — группирует векторы с высокой схожестью в оптимизированные структуры хранения, снижая количество запросов ввода-вывода в процессе переранжирования на 30% и устраняя избыточные операции ввода-вывода с помощью эффективных стратегий кэширования.
Экспериментальные результаты показывают, что FusionANNS превосходит современные системы, такие как SPANN и RUMMY, по различным метрикам. Система достигает до 13,1 раза более высокий QPS (запросов в секунду) и 8,8 раза более высокую эффективность по себестоимости по сравнению с SPANN, а также 2-4,9 раза более высокий QPS и 6,8 раза лучшую эффективность по себестоимости по сравнению с RUMMY. Для набора данных, содержащего один миллиард векторов, FusionANNS способен обрабатывать процесс запроса с QPS более 12 000, при этом сохраняя задержку на уровне 15 миллисекунд. Эти результаты демонстрируют, что FusionANNS является очень эффективным для управления наборами данных миллиардного масштаба без необходимости обширных памятных ресурсов.
Основные выводы из этого исследования включают в себя:
- Повышение производительности: FusionANNS достигает до 13,1 раза более высокий QPS и 8,8 раза лучшую эффективность по себестоимости, чем современная система на основе SSD SPANN.
- Повышение эффективности: Он обеспечивает 5,7-8,8 раза более высокую эффективность в обработке доступа к данным на SSD.
- Масштабируемость: FusionANNS способен управлять наборами данных миллиардного масштаба с использованием только одного графического ускорителя начального уровня и минимальных памятных ресурсов.
- Экономичность: Система показывает улучшение в 2-4,9 раза по себестоимости по сравнению с существующими решениями в памяти, такими как RUMMY.
- Снижение задержки: FusionANNS поддерживает задержку запроса 15 миллисекунд, что значительно ниже, чем у других решений на основе SSD и графически ускоренных решений.
- Инновации в дизайне: Использование многоуровневой индексации, эвристического переранжирования и дублирования ввода-вывода с учетом избыточности являются новаторскими вкладами, которые выделяют FusionANNS среди существующих методов.
В заключение, FusionANNS представляет собой прорыв в технологии ANNS, обеспечивая высокую пропускную способность, низкую задержку и превосходную экономичность. Новаторский подход исследователей к совместной работе CPU/GPU и многоуровневой индексации предлагает практическое решение для масштабирования ANNS для поддержки больших наборов данных. FusionANNS устанавливает новый стандарт для обработки высокоразмерных данных в реальных приложениях путем снижения объема памяти и исключения ненужных вычислений.