Meta-Rewarding LLMs: новый метод улучшения возможности следовать инструкциям моделей LLM
Большие языковые модели (LLM) значительно продвинулись в выполнении инструкций и ответах на вопросы пользователей. Однако процесс настройки инструкций сталкивается с серьезными проблемами. Получение данных, сгенерированных людьми, для обучения этих моделей является дорогостоящим и затратным по времени. Кроме того, качество таких данных ограничено возможностями человека. Это ограничение особенно заметно при решении проблемы ‘Супер выравнивания’, которая направлена на контроль потенциально сверхинтеллектуальных ИИ, действия которых могут превышать понимание человека. Существует необходимость в поиске эффективных методов в области искусственного интеллекта для направления развития LLM за пределы уровня человека в связи с их постоянным развитием.
Метод Meta-Rewarding
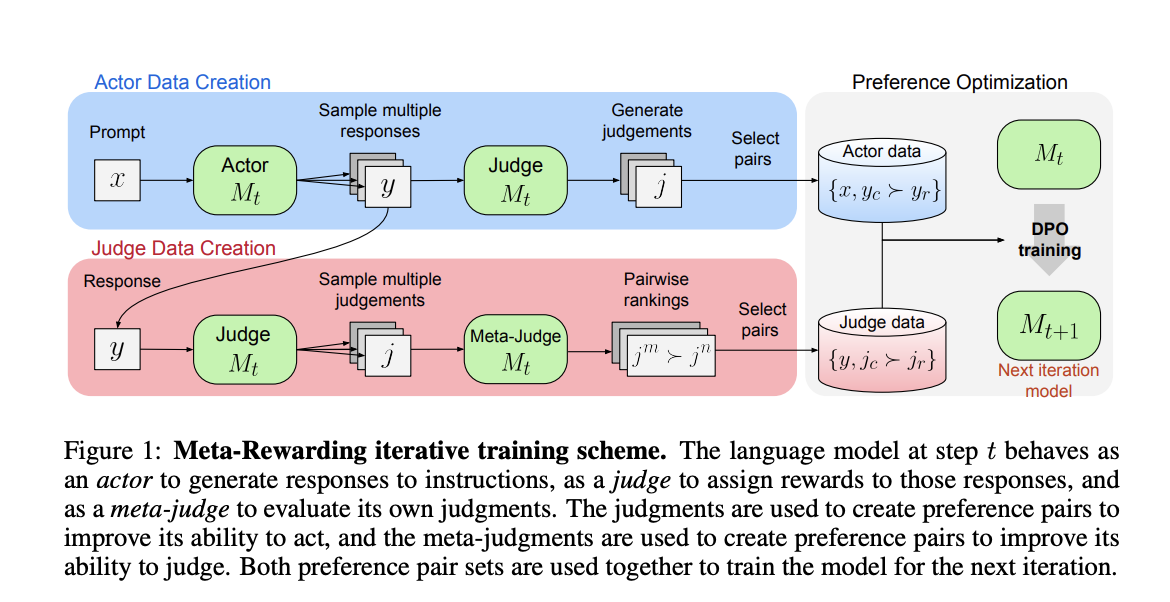
Исследователи из Meta FAIR, Университета Калифорнии в Беркли и Нью-Йоркского университета представили новый метод под названием Meta-Rewarding для улучшения способностей LLM следовать инструкциям. Данный метод добавляет третью роль – мета-судью, к существующим ролям актера и судьи. Мета-судья оценивает решения модели с использованием механизма, аналогичного LLM-as-a-Judge, называемого LLM-as-a-Meta-Judge. Этот процесс помогает генерировать данные для обучения с предпочтительными парами решений, в дополнение к стандартным предпочтениям между реакциями актера. Meta-Rewarding улучшает общую способность модели следовать инструкциям путем улучшения как актерских, так и судейских навыков.
Результаты и применение
Результаты показывают, что Meta-Rewarding повысил выигрышный процент с 22,9% до 39,4% на AlpacaEval, превзойдя даже GPT-4-0314. Этот метод также превысил улучшенное стандартное обучение Self-Rewarding, который имел выигрышный процент в 35,5%, подчеркивая важность мета-судьи. Такая же производительность наблюдается на бенчмарке Arena-Hard, который тестирует способность моделей обрабатывать сложные вопросы. После четырех итераций Meta-Rewarding последовательно улучшал результаты, достигнув увеличения на 8,5% по сравнению с исходной моделью. Эти результаты свидетельствуют о том, что Meta-Rewarding улучшает возможности LLM в следовании инструкциям и ответах на сложные вопросы.
В заключение, исследователи предложили Meta-Rewarding, новый метод улучшения способностей LLM следовать инструкциям. Этот метод использует мета-судью для оценки и выбора решений для оптимизации предпочтений, что устраняет ограничения предыдущих Self-Rewarding фреймворков путем прямого обучения судьи. Более того, он включает новую технику контроля длины для решения проблем взрыва длины во время обучения AI. Способности модели в оценке ближе соответствуют оценкам человека и продвинутым AI судьям, таким как GPT-4. Однако исследователи отмечают ограничение своей 5-балльной системы оценки, которое иногда приводит к ничьей из-за минимальных различий в качестве ответов.









