Интринсическая размерность и композициональность: связь скрытых состояний LLM с кодированием fMRI
Исследования когнитивной нейронауки изучают, как мозг обрабатывает сложную информацию, в частности, язык. Одна из важных областей этого исследования – сравнение механизмов обработки языка мозга с искусственными нейронными сетями, особенно с большими языковыми моделями (LLM). Путем изучения того, как LLM обрабатывают язык, исследователи стремятся раскрыть глубокие идеи о человеческом познании и системах машинного обучения, улучшая обе области.
Выявление сложности обработки языка
Одним из критических вызовов в этой области является понимание того, почему определенные слои LLM более эффективны в репликации активности мозга, чем другие. Хотя LLM в основном обучаются предсказывать текст, способность промежуточных слоев точно представлять понимание языка, подобного человеческому, стала увлекательной загадкой. Идет работа над выявлением того, почему эти промежуточные слои более тесно соотносятся с активностью мозга, чем выходные слои, предназначенные для задач предсказания.
Исследование новой методологии
Исследователи из Университата Помпеу Фабра и Колумбийского университета представили новую методологию для изучения этого явления. С использованием техник многообразий они выявили двухфазовый процесс абстракции в LLM. Во время обучения LLM сначала сжимают сложные языковые особенности в меньшее количество слоев, фаза, которую исследователи называют “композицией”. Вторая фаза, “предсказание”, сосредотачивается на задаче модели предсказать следующее слово. Согласно их результатам, этот процесс абстракции критичен для высокой схожести между мозгом и моделью, наблюдаемой в LLM, при этом фаза композиции оказывается более важной, чем ранее думалось. Исследование подчеркивает важность этого слоистого подхода к представлению языка в понимании LLM и функций мозга.
Значимость результатов исследования
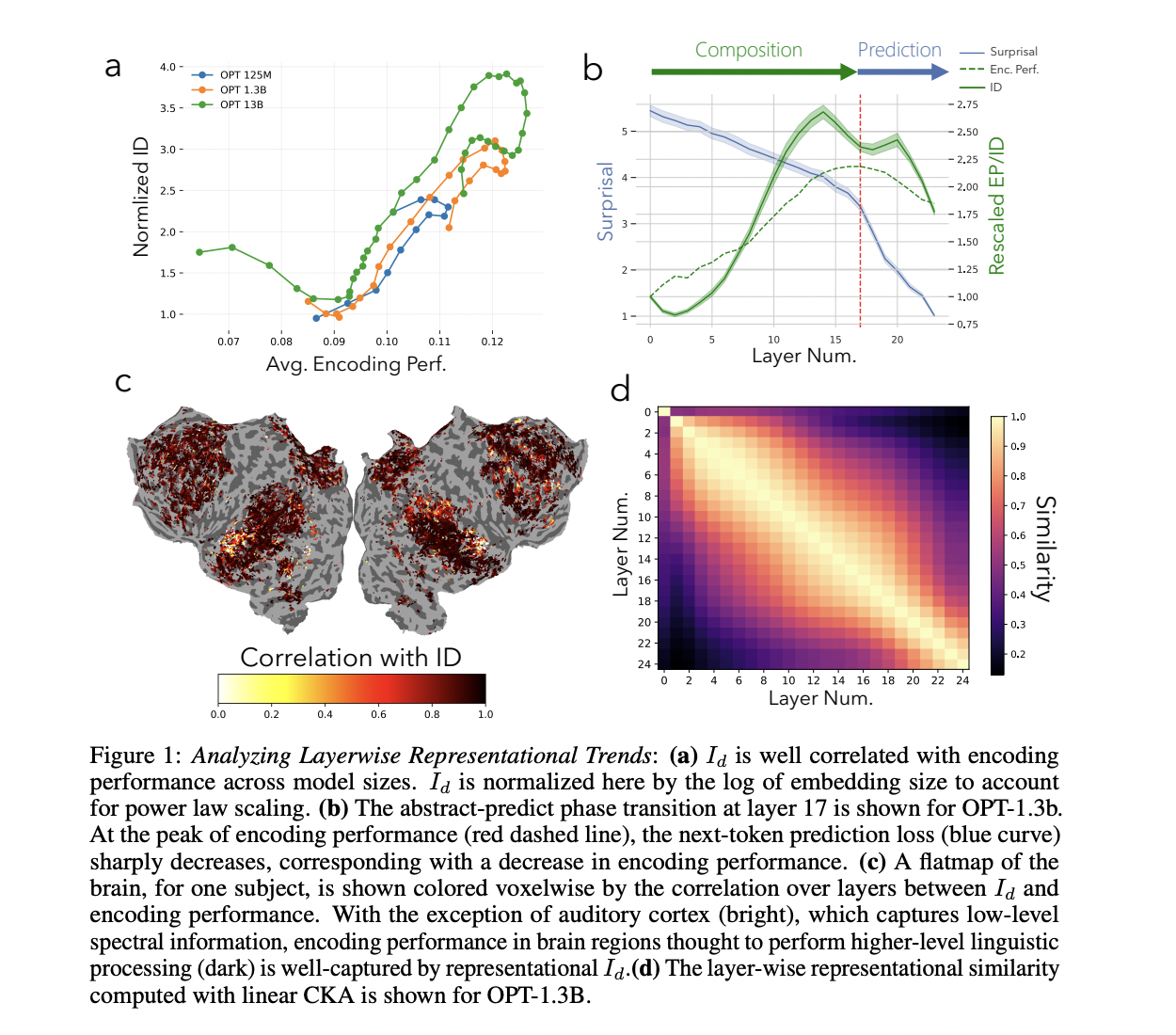
Исследователи обнаружили сильную корреляцию между промежуточными слоями и сходством между мозгом и моделью в своих экспериментах. Они выявили, что оптимальный слой для предсказания активности мозга достигает пика на 17 слое в модели OPT-1.3b, соответствуя наивысшей производительности кодирования. Исследователи использовали три размера LLM (125M, 1.3B и 13B) и измерили корреляцию между размерностью представления и производительностью кодирования по воксельной точке между ними. Для самой большой модели Pythia (6.9B параметров) исследователи подтвердили, что внутренняя размерность увеличивалась со временем, достигая пика в производительности кодирования и размерности на 13 слое. Эти результаты указывают на то, что первая фаза абстракции важнее для сходства между мозгом и моделью, чем фаза окончательного предсказания, оспаривая предыдущие предположения о роли задач предсказания в соответствии между мозгом и LLM.
Заключение и перспективы
Исследование предлагает понимание того, как LLM и мозг обрабатывают язык. Идентифицируя двухфазовый процесс абстракции в LLM, исследователи лучше поняли сходство между мозгом и моделью. Их результаты указывают на то, что фаза композиции, а не фаза предсказания, несет наибольшую ответственность за это сходство. Это исследование открывает двери для будущих исследований по оптимизации языковых моделей для задач машинного обучения и нейронауки.
























