«`html
Как CodexGraph может улучшить ваш бизнес с помощью искусственного интеллекта
Крупные языковые модели (LLM) продемонстрировали исключительную производительность на изолированных задачах кода, таких как HumanEval и MBPP, но сталкиваются с серьезными трудностями при работе с целыми репозиториями кода. Основная сложность заключается в неспособности LLM управлять вводами с длинным контекстом и выполнять сложное рассуждение по сложным структурам кода в больших проектах. Эта проблема усугубляется необходимостью моделям понимать и навигировать зависимости и структуры проектов в кодовой базе. Решение этой проблемы является ключевым для развития автоматизированной разработки программного обеспечения, особенно в обеспечении возможности LLM обрабатывать задачи разработки программного обеспечения в реальном мире, требующие глубокого понимания крупных репозиториев.
Преимущества CodexGraph
Методы, направленные на улучшение взаимодействия LLM с репозиториями кода, обычно полагаются на поиск на основе сходства или ручные инструменты и API. Однако эти методы имеют ограничения, которые подчеркивают необходимость более продвинутых подходов, способных эффективно поддерживать LLM в навигации и понимании больших репозиториев кода.
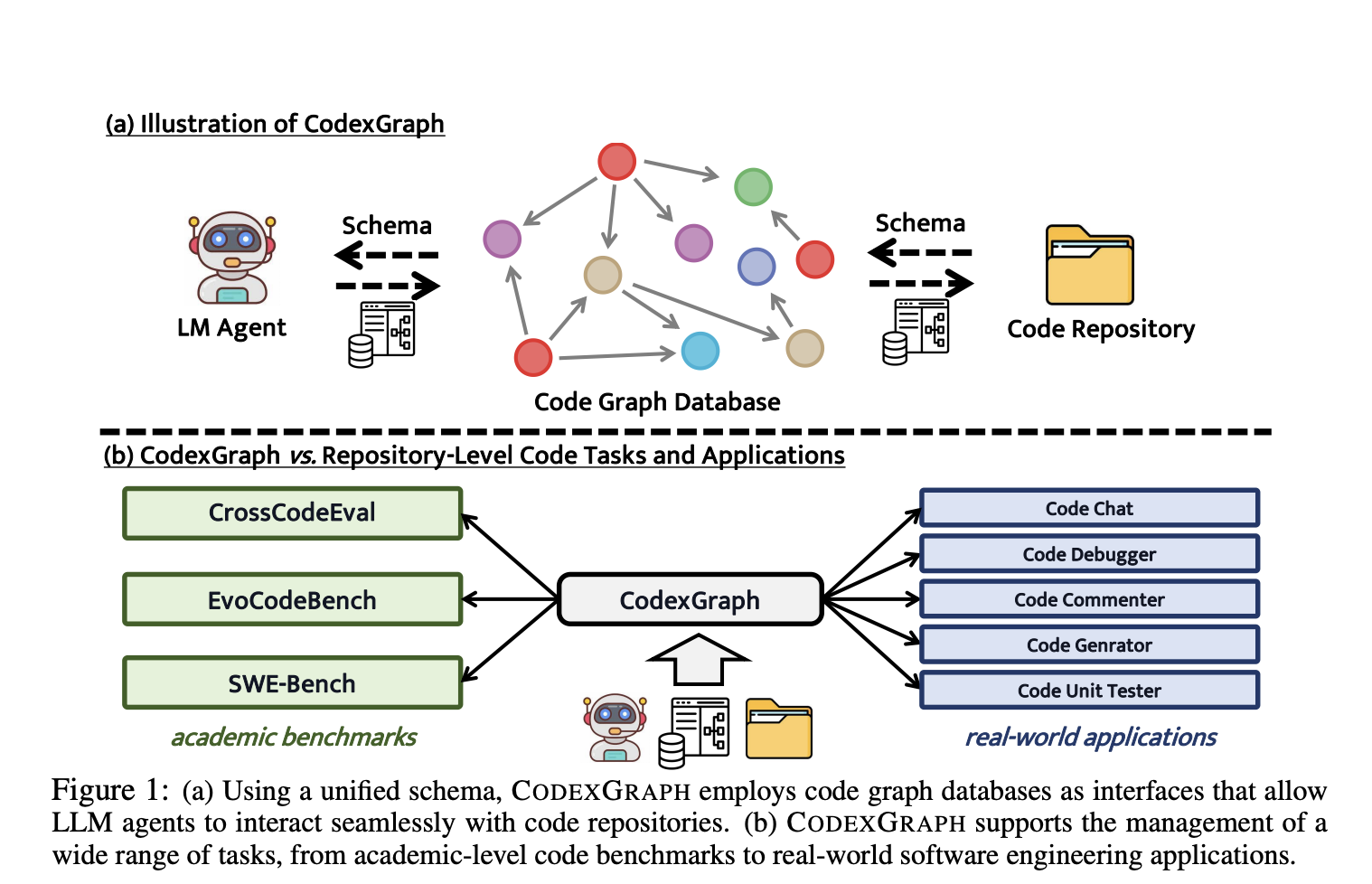
Команда исследователей из Национального университета Сингапура, Alibaba Group и Университета Сиань Цзяотун предлагает CODEXGRAPH, систему, которая интегрирует LLM с интерфейсами графовых баз данных, извлеченных из репозиториев кода. Этот подход использует структурные свойства графовых баз данных, в сочетании с гибкостью языков запросов к графам, чтобы обеспечить точный поиск контекста, связанного со структурой кода, и навигацию. CODEXGRAPH создает универсальный интерфейс, повышающий способность LLM эффективно извлекать соответствующую информацию из кодовой базы.
Оценка CODEXGRAPH
CODEXGRAPH был оценен на трех уровнях репозиториев: CrossCodeEval, SWE-bench и EvoCodeBench. Результаты демонстрируют, что этот подход достигает конкурентоспособной производительности на всех уровнях, особенно в сочетании с продвинутыми LLM, такими как GPT-4o, DeepSeek-Coder-V2 и Qwen2-72b-Instruct. Например, на наборе данных CrossCodeEval Lite (Python) с использованием GPT-4o, CODEXGRAPH достиг точного совпадения (EM) в 27,9%, превосходя другие методы. Результаты также показывают, что CODEXGRAPH особенно эффективен в сложных задачах, требующих глубокого рассуждения, демонстрируя свой потенциал в сценариях разработки программного обеспечения в реальном мире.
Заключение
CODEXGRAPH представляет собой передовой подход, который решает ограничения существующих методов Retrieval-Augmented Code Generation (RACG) путем интеграции LLM с интерфейсами графовых баз данных. Этот метод улучшает способность LLM навигировать и извлекать соответствующую информацию из больших репозиториев кода, значительно улучшая производительность в академических и практических задачах разработки программного обеспечения.
«`

























