«`html
GraphReader: ИИ-агент на основе графов для обработки длинных текстов
Большие языковые модели (LLM) сделали значительные успехи в понимании и генерации естественного языка. Однако они сталкиваются с критической проблемой при обработке длинных контекстов из-за ограничений размера окна контекста и использования памяти. Эта проблема затрудняет их способность эффективно обрабатывать и понимать обширные текстовые входы. По мере роста спроса на LLM для обработки все более сложных и длинных задач становится насущной проблемой для исследователей и разработчиков в области обработки естественного языка.
Практические решения и ценность
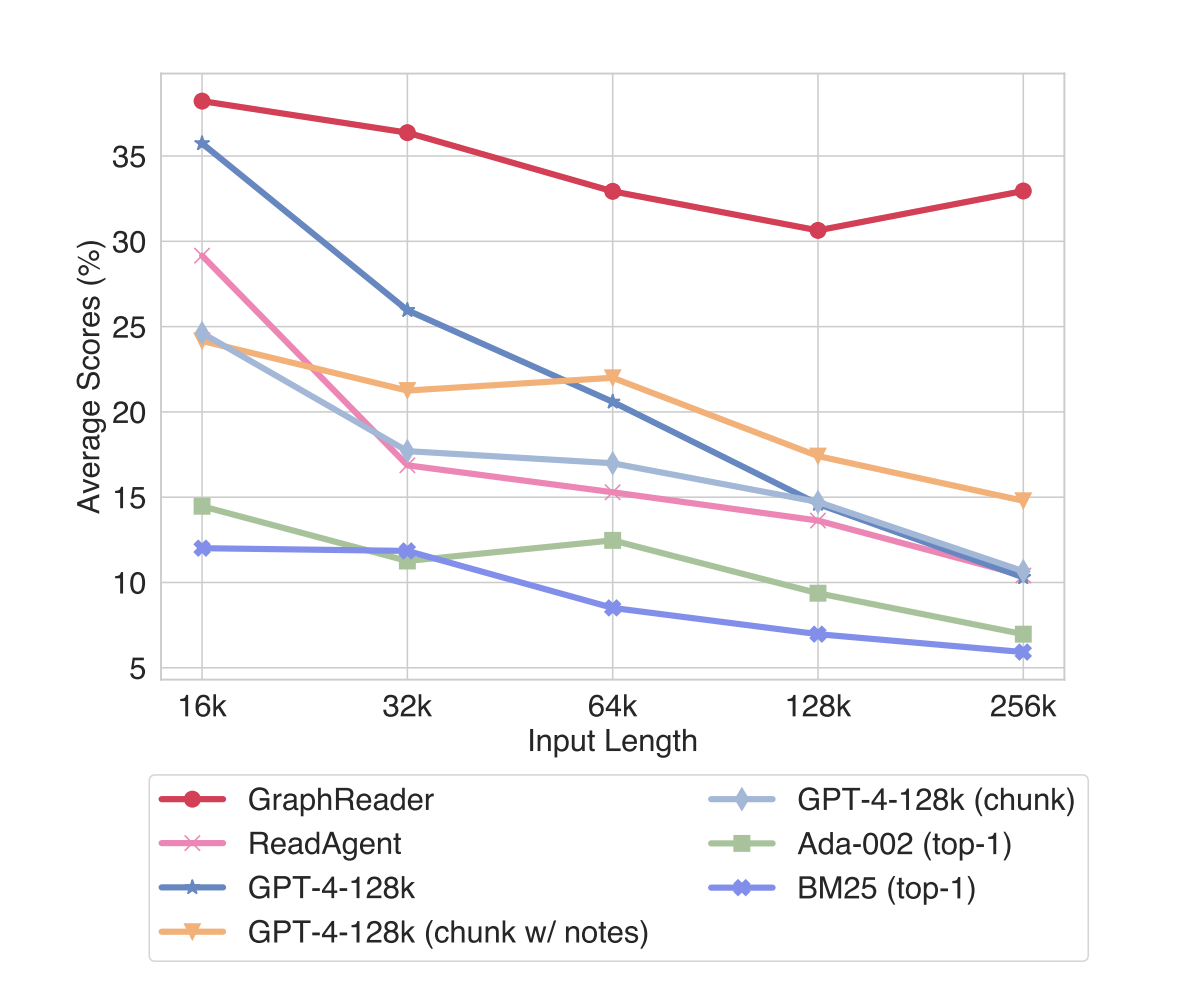
Исследователи из Alibaba Group, The Chinese University of Hong Kong, Shanghai AI Laboratory и University of Manchester представили GraphReader, надежную систему на основе графового агента для решения проблем обработки длинных контекстов в LLM. Этот инновационный подход разбивает длинные тексты на отдельные части, извлекая и сжимая важную информацию в ключевые элементы и атомарные факты. Эти компоненты затем используются для построения графовой структуры, которая эффективно улавливает долгосрочные зависимости и многопереходные отношения в тексте. Агент автономно исследует этот граф, используя заранее определенные функции и пошаговый рациональный план, постепенно получая информацию от грубых элементов до детальных исходных текстовых частей. Этот процесс включает в себя ведение заметок и размышлений до тех пор, пока не будет собрана достаточная информация для генерации ответа.
GraphReader представляет собой значительное достижение в решении проблем обработки длинных контекстов в больших языковых моделях. Путем организации обширных текстов в графовые структуры и использования автономного агента для исследования он эффективно улавливает долгосрочные зависимости в компактном окне контекста 4k. Его превосходная производительность, превосходящая GPT-4 с входной длиной 128k в различных задачах вопросно-ответной системы, демонстрирует его эффективность в решении сложных сценариев рассуждения. Этот прорыв открывает новые возможности для применения LLM в задачах, связанных с длинными документами и сложным многошаговым рассуждением, потенциально революционизируя области анализа документов и помощи в исследованиях. GraphReader устанавливает новый стандарт для обработки длинных контекстов, предвосхищая более продвинутые языковые модели.
«`

























