«`html
Решение для эффективного обслуживания нескольких LLM одновременно
Большие языковые модели (LLM) приобрели значительную популярность в индустрии искусственного интеллекта, революционизируя различные приложения, такие как чаты, программирование и поиск. Однако эффективное обслуживание нескольких LLM стало критической проблемой для поставщиков конечных точек. Основная проблема заключается в значительных вычислительных требованиях этих моделей, например, для одной модели 175B LLM требуется восемь A100 (80GB) GPU для вывода.
Текущие методы и проблемы
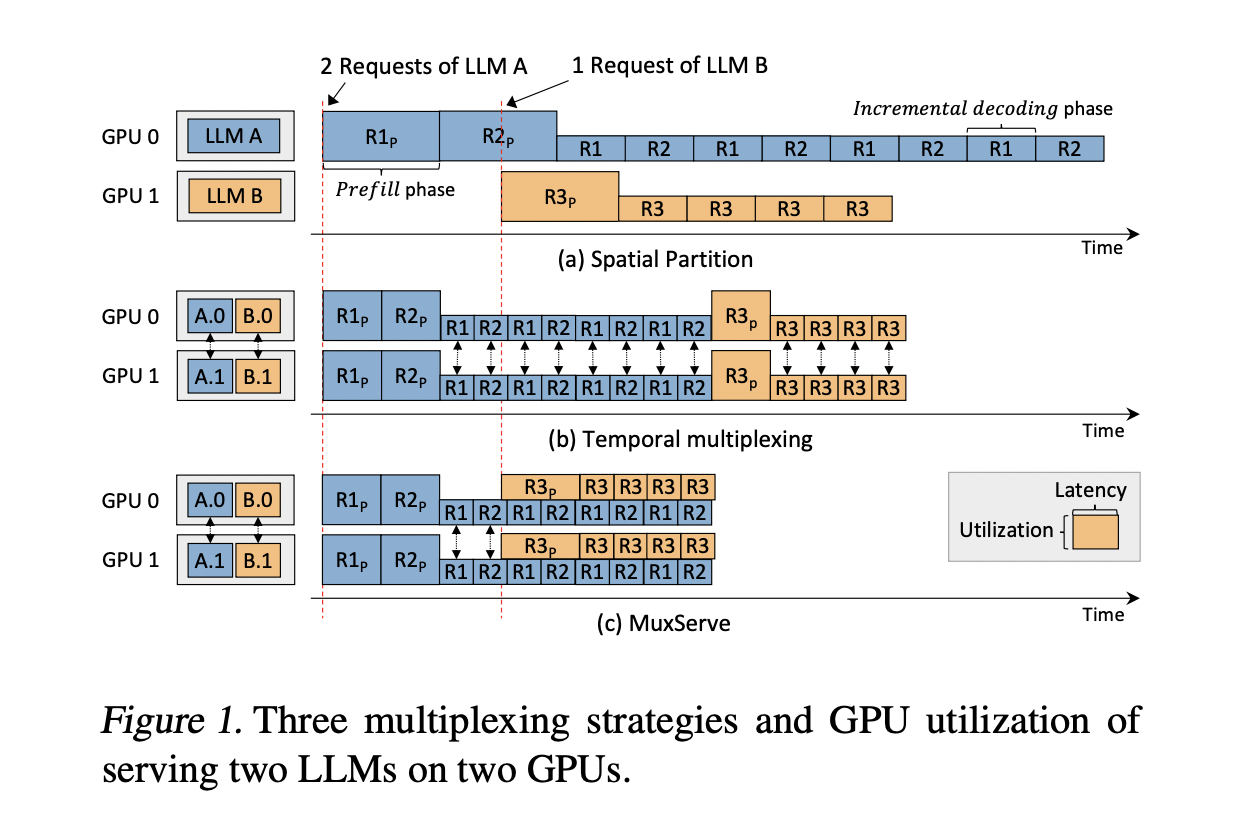
Текущие методы, в частности, пространственное разделение, требуют улучшения в использовании ресурсов. Этот подход выделяет отдельные группы GPU для каждого LLM, что приводит к недоиспользованию из-за различной популярности моделей и скорости запросов. Следовательно, менее популярные LLM приводят к простою GPU, в то время как популярные испытывают узкие места в производительности, что подчеркивает необходимость более эффективных стратегий обслуживания.
Решение MuxServe
Исследователи из нескольких университетов представляют MuxServe, гибкий пространственно-временной мультиплексный подход для обслуживания нескольких LLM, решающий проблемы использования GPU. Система использует жадный алгоритм размещения, адаптивное планирование партий и унифицированный менеджер ресурсов для максимизации эффективности. Путем разделения GPU SM с помощью CUDA MPS MuxServe достигает эффективного пространственно-временного разделения. Этот подход приводит к увеличению пропускной способности на 1,8 раза по сравнению с существующими системами, что является значительным прорывом в эффективном обслуживании нескольких LLM.
Преимущества и результаты
MuxServe демонстрирует превосходную производительность как в синтетических, так и в реальных рабочих нагрузках. В синтетических сценариях он достигает до 1,8 раза большей пропускной способности и обрабатывает до 2,9 раз больше запросов с достижением SLO в 99% по сравнению с базовыми системами. В реальных нагрузках MuxServe превосходит пространственное разделение и временной мультиплексинг на 1,38 и 1,46 раза соответственно, обеспечивая более высокое достижение SLO при различных скоростях запросов.
Заключение
Исследование представляет MuxServe как значительный прорыв в области обслуживания LLM. Его инновационный подход к мультиплексированию LLM на основе их популярности и разделение предварительной загрузки и декодирования приводит к улучшению использования GPU. Этот метод демонстрирует существенный прирост производительности по сравнению с существующими системами, достигая более высокой пропускной способности и лучшего достижения SLO при различных сценариях рабочей нагрузки. Возможность MuxServe адаптироваться к различным размерам LLM и шаблонам запросов делает его универсальным решением для растущих потребностей в развертывании LLM. MuxServe предоставляет многообещающую платформу для эффективного и масштабируемого обслуживания LLM в условиях постоянной эволюции индустрии искусственного интеллекта.
«`

























