Практические решения и ценность исследования по Scaling Laws and Model Comparison в машинном обучении большого масштаба
Сдвиг парадигмы и вызовы
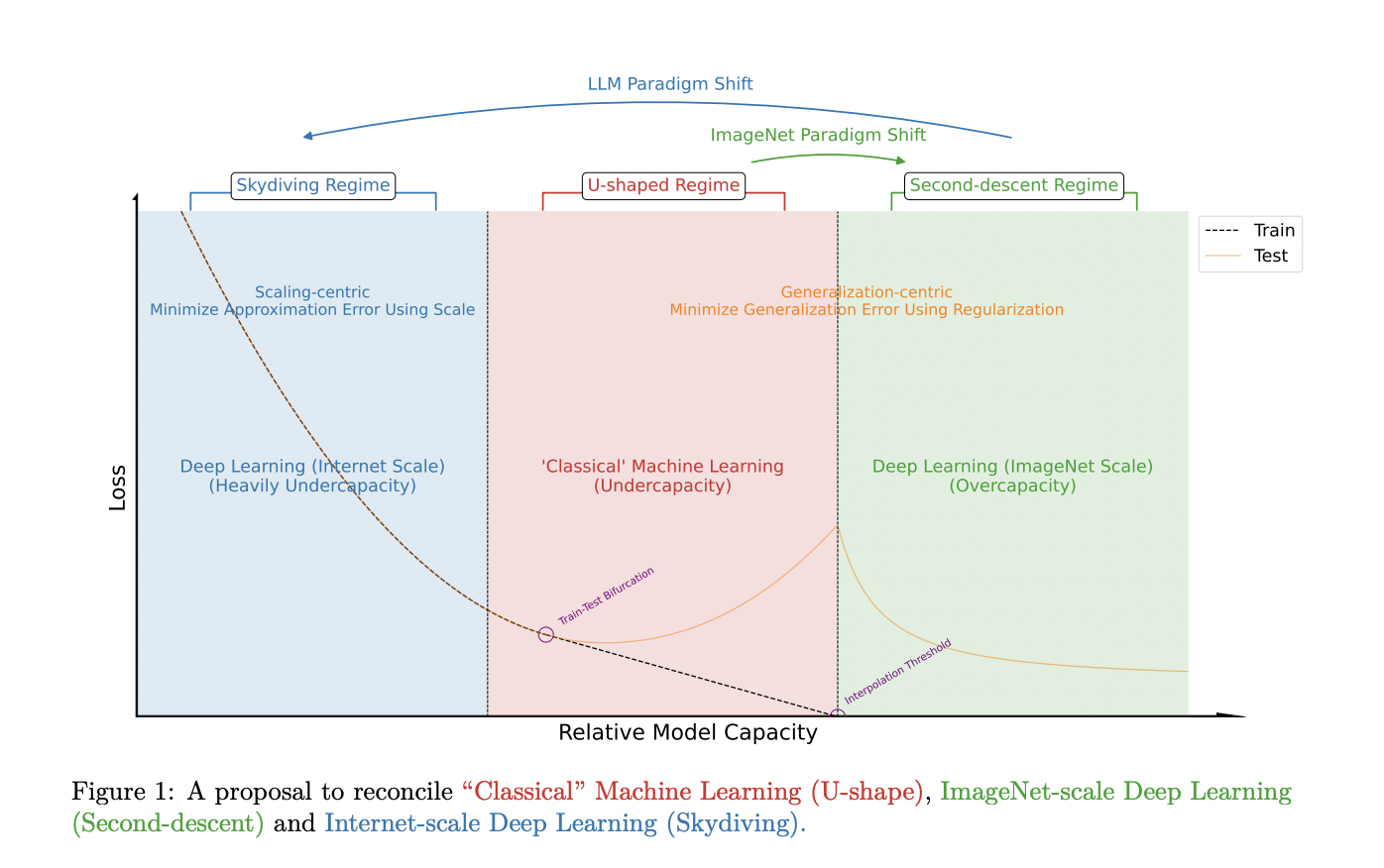
Большие языковые модели привлекли значительное внимание в машинном обучении, смещая фокус с оптимизации обобщения на малых наборах данных к снижению ошибки аппроксимации на огромных текстовых корпусах. Этот сдвиг представляет исследователям новые вызовы в разработке моделей и методологиях обучения. Основная цель эволюционировала от предотвращения переобучения через техники регуляризации к эффективному масштабированию моделей для обработки огромных объемов данных.
Методология масштабирования моделей
Для оптимизации производительности в парадигме масштабирования и оптимального сравнения моделей на невиданных масштабах разработан алгоритм с использованием декодерной архитектуры трансформера, обученной на наборе данных C4 с использованием кодовой базы NanoDO. Ключевые архитектурные особенности включают Ротационные Позиционные Эмбеддинги, QK-Norm для вычисления внимания, несвязанные веса головы и эмбеддингов. Модель использует активацию Gelu с F = 4D, где D — размер модели, а F — скрытое измерение MLP. Головы внимания настроены с измерением головы 64, а длина последовательности установлена на 512.
Переоценка регуляризации в масштабируемой парадигме
В парадигме масштабирования вопрос эффективности традиционных методов регуляризации поднимается на обсуждение. Техники регуляризации, эффективно применяемые для моделей меньшего масштаба, могут не оказывать оптимальных результатов для крупных языковых моделей. Это стимулирует исследователей разработать устойчивые методологии и принципы для развития и сравнения моделей в новой парадигме, где традиционные подходы уже могут быть неактуальны.
Для более глубокого понимания и внедрения искусственного интеллекта свяжитесь с нами по ссылке здесь.
Испытайте ИИ ассистента в продажах от Flycode.ru здесь. Этот ИИ инструмент поможет вам улучшить обслуживание клиентов и снизить нагрузку на вашу команду продаж.