Революция в обработке естественного языка
Большие языковые модели (LLM) революционизировали обработку естественного языка, продемонстрировав исключительную производительность на различных бенчмарках и находя применение в реальном мире. Однако авторегрессионная парадигма обучения, лежащая в их основе, представляет существенные вызовы. В частности, последовательный характер генерации токенов авторегрессии приводит к медленным скоростям обработки, ограничивая эффективность моделей в условиях высокой производительности. Кроме того, данный подход может привести к воздействию экспозиции, что потенциально влияет на качество и целостность генерируемого текста. Эти ограничения побудили исследователей изучить альтернативные подходы, способные сохранить впечатляющие возможности LLM, устраняя их врожденные недостатки.
Практические решения и ценность
Исследователи разработали различные техники для преодоления вызовов выборки и улучшения скорости генерации в LLM. Были предложены эффективные реализации для оптимизации производительности модели, а методы вывода низкой точности направлены на снижение вычислительных требований. Новые архитектуры спроектированы для повышения эффективности обработки, а подходы с множественным предсказанием токенов стремятся генерировать несколько токенов одновременно. Одновременно предпринимаются усилия по адаптации моделей диффузии для генерации текста, предлагая альтернативу традиционным авторегрессивным методам.
Исследователи из CLAIRE изучают силу дискретной диффузии оценок энтропии (SEDD) и выявляют перспективные направления улучшения. SEDD выделяется как многообещающая альтернатива традиционной авторегрессивной генерации в языковых моделях. Этот подход предлагает ключевое преимущество в его способности гибко балансировать качество и вычислительную эффективность, что делает его особенно подходящим для применений, где доступен верификатор. Потенциал SEDD проявляется в сценариях, таких как решение сложных задач комбинаторики, где более быстрая выборка может компенсировать незначительное снижение качества.
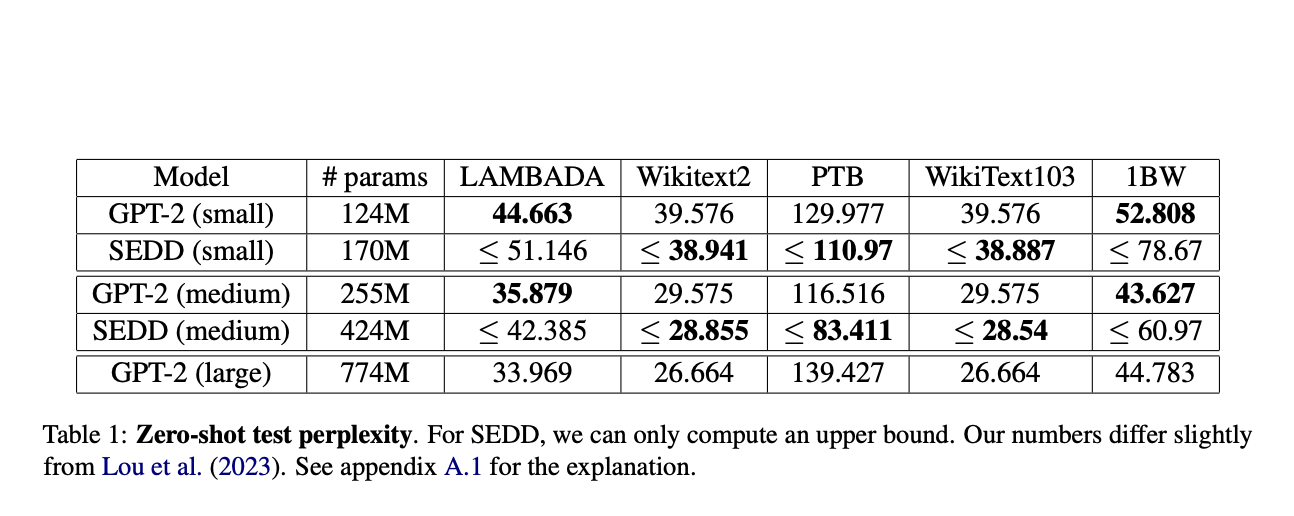
SEDD использует трансформаторный основной блок, аналогичный GPT-2, обученный на наборе данных OpenWebText. Сравнительные оценки показывают, что SEDD соответствует или превосходит вероятность GPT-2 на различных тестовых наборах данных, включая LAMBADA, Wikitext2, PTB, WikiText103 и 1BW. Процесс выборки SEDD предлагает гибкость, позволяя использовать меньшее количество шагов, чем длина последовательности, причем 32 шага выборки достигают лучшей перплексии, чем GPT-2 без отжига для последовательностей из 1024 токенов. Алгоритм выборки прост в использовании, что делает его доступным для дальнейших исследований. В отличие от авторегрессивных моделей, некаузальная генерация токенов SEDD и гибкое определение процесса вперед открывают возможности для задач, требующих рассмотрения длинных последовательностей. Знакомая архитектура позволяет потенциально интегрировать альтернативные последовательные модели, такие как модели пространства состояний, представляя возможности для дальнейшего архитектурного исследования и оптимизации.
Сравнительные оценки показывают, что SEDD соответствует или превосходит GPT-2 в качестве безусловной генерации, достигая более низкой перплексии без отжига и схожей вероятности с 1024 шагами выборки. В условной генерации SEDD показывает немного более низкие показатели по метрике MAUVE, но демонстрирует сопоставимую точность в задачах, зависящих от контекста. Оценки разнообразия показывают, что SEDD менее разнообразен, чем GPT-2, с неожиданным увеличением частоты повторений и уменьшением энтропии униграмм при увеличении шагов выборки. Для условной генерации с короткими подсказками SEDD оказывается немного слабее, чем GPT-2. Эти результаты указывают на то, что хотя SEDD предлагает конкурентоспособную производительность во многих областях, есть потенциал для улучшения разнообразия и условной генерации, особенно с более короткими подсказками.
В данном исследовании исследователи представляют свои убедительные аргументы в пользу моделей диффузии для генерации текста как релевантной альтернативы авторегрессивной генерации, на примере SEDD, которая выделяется как жизнеспособная альтернатива авторегрессивным моделям, предлагая сравнимое качество генерации с GPT-2 с увеличенной гибкостью выборки. Хотя SEDD демонстрирует многообещающие результаты, остаются вызовы, особенно в эффективности выборки. Для достижения безусловного качества текста, сопоставимого с GPT-2 с использованием выборки ядра, требуется значительно больше шагов, что приводит к медленной генерации по сравнению с GPT-2 с кэшированием KV.
Искусственный интеллект в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте The Rise of Diffusion-Based Language Models: Comparing SEDD and GPT-2.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























