«`html
Глубокие модели обучения, такие как сверточные нейронные сети (CNN) и Vision Transformers, достигли больших успехов во многих визуальных задачах, таких как классификация изображений, обнаружение объектов и семантическая сегментация. Однако их способность обрабатывать различные изменения в данных по-прежнему вызывает серьезные опасения, особенно при использовании в приложениях, где безопасность играет важную роль.
Робастность глубоких моделей обучения
Многие работы оценили устойчивость CNN и Transformers против общих искажений, сдвигов доменов, потери информации и атак. Они показывают, что конструкция модели влияет на ее способность управлять этими проблемами, и робастность варьируется в различных архитектурах. Одним из основных недостатков трансформеров является квадратичное вычислительное масштабирование с размером ввода, что делает их дорогими для выполнения сложных задач.
Анализ производительности VSSM, Vision Transformers и CNN
Исследователи из MBZUAI UAE, Университета Линчёпинг и АНУ Австралии представили комплексный анализ производительности VSSM, Vision Transformers и CNN. Этот анализ может управлять различными вызовами для задач классификации, обнаружения и сегментации, а также предоставлять ценные идеи о их устойчивости и пригодности для реальных приложений.
Ключевые выводы
На основе оценки всех трех разделов выявлены следующие ключевые результаты:
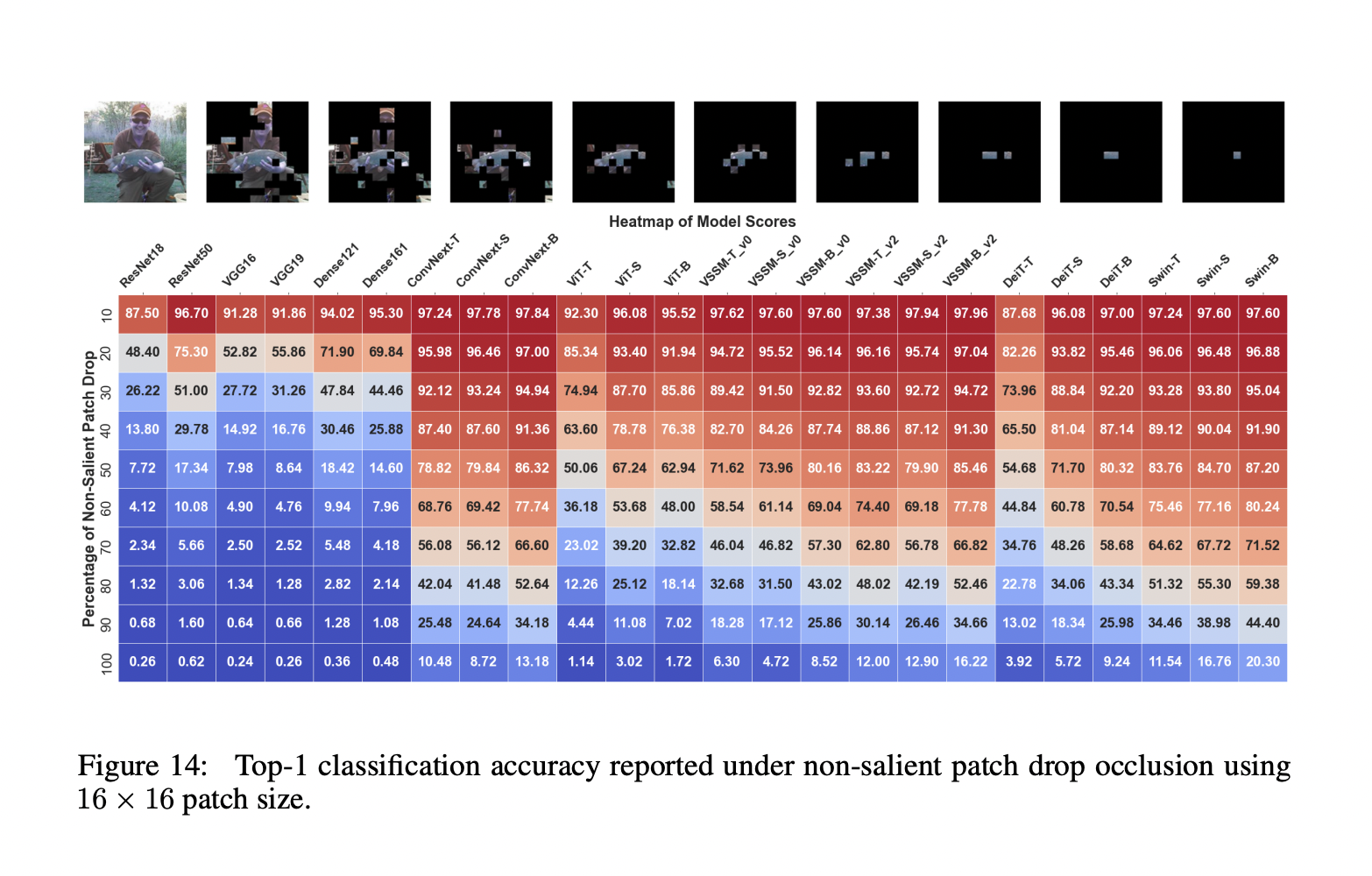
- Модели VSSM обладают наименьшим средним снижением производительности по сравнению с моделями Swin и ConvNext при глобальных искажениях. Для тонких искажений модели VSSM превосходят все варианты на основе трансформаторов.
- Меньшие модели VSSM проявляют большую устойчивость к белым атакам по сравнению с трансформаторами Swin. Модели VSSM сохраняют устойчивость более 90% к сильным низкочастотным возмущениям, но их производительность быстро снижается при атаках высокой частоты.
Заключение
Исследователи тщательно оценили устойчивость моделей Vision State-Space (VSSM) к различным естественным и адверсным воздействиям, показав их преимущества и недостатки по сравнению с трансформаторами и CNN. Эксперименты раскрывают возможности и ограничения VSSM в обработке заслонок, общих искажений и адверсных атак, а также их способность адаптироваться к изменениям состава объекта-фон в сложных визуальных сценах.
«`

























