«`html
Сравнительный анализ LLM и традиционного текстового увеличения: точность, эффективность и экономическая эффективность
Большие языковые модели (LLM) типа GPT-4, Gemini и Llama революционизировали увеличение текстовых наборов данных, открыв новые возможности для улучшения малых классификаторов. Однако этот подход сталкивается с серьезными проблемами. Основная проблема заключается в значительных вычислительных затратах на увеличение на основе LLM, что приводит к высокому энергопотреблению и выбросам CO2. Часто эти модели, содержащие десятки миллиардов параметров, требуют гораздо больше ресурсов, чем установленные методы увеличения, такие как обратный перевод или техники на основе BERT. Исследователям требуется помощь в балансировке улучшения производительности классификаторов с использованием LLM и их экологическими и экономическими издержками. Кроме того, противоречивые результаты существующих исследований создали неопределенность относительно сравнительной эффективности методов на основе LLM по сравнению с традиционными подходами, что подчеркивает необходимость более всесторонних исследований в этой области.
Практические решения и ценность
Исследователи изучили различные техники увеличения текста для улучшения производительности языковых моделей. Установленные методы включают увеличение на основе символов, обратный перевод и ранние языковые модели для перефразирования. Продвинутые подходы включают технику style transfer, контроль синтаксиса и мультиязычное перефразирование. С мощными LLM, такими как GPT-4 и Llama, методы увеличения были адаптированы для генерации высококачественных перефразов. Однако исследования, сравнивающие увеличение на основе LLM с установленными методами, дали разнонаправленные результаты. Некоторые исследования показывают улучшение точности классификаторов с использованием LLM для перефразирования, в то время как другие предполагают, что это может не существенно превосходить традиционные техники.
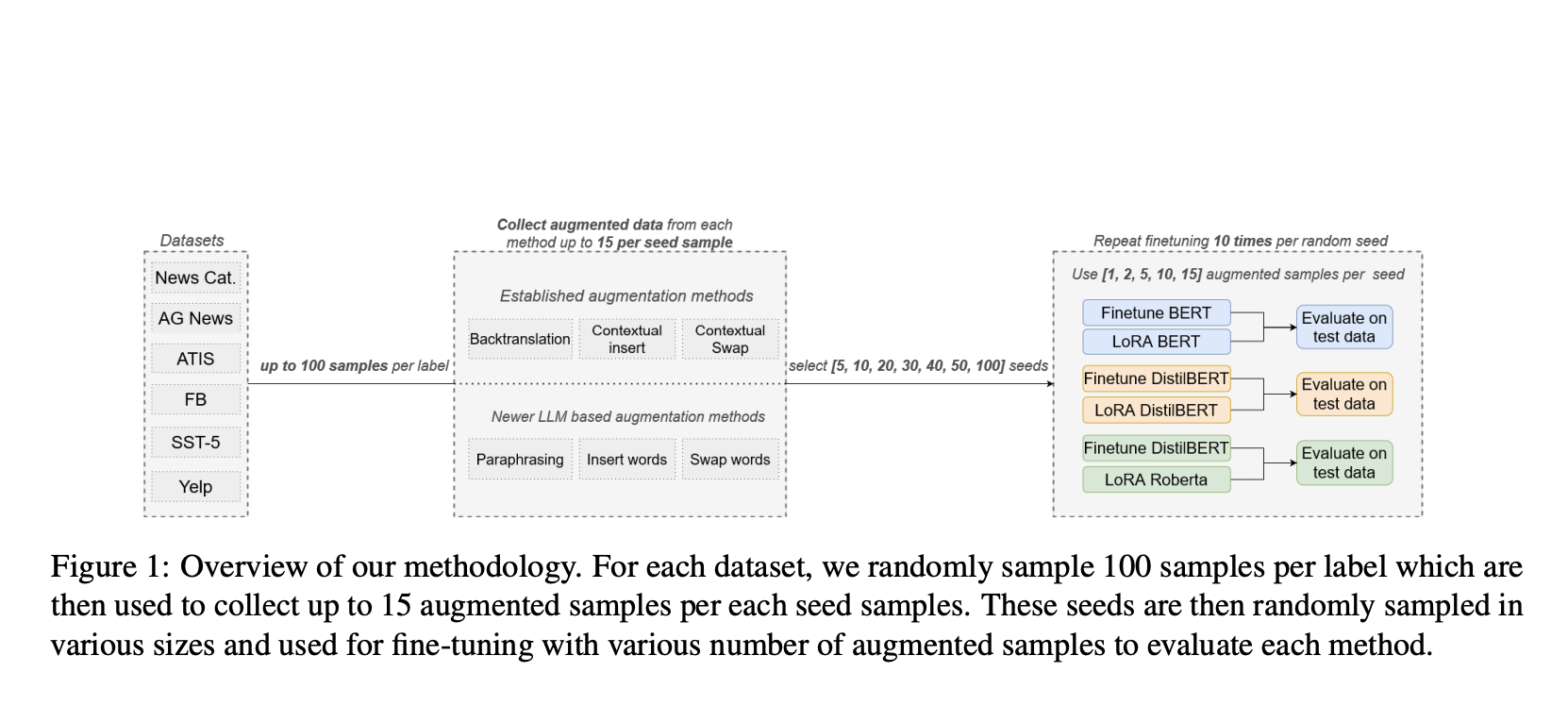
Исследование проведено с целью сравнения установленных методов увеличения текста с подходами на основе LLM, с акцентом на точность и анализ затрат. Оно исследует перефразирование, вставку слов и замену слов в традиционных и LLM-вариантах. Исследование использует шесть наборов данных по различным классификационным задачам, три модели классификаторов и два подхода к fein-tuning. Проведение 267 300 fine-tunings с различными размерами выборки позволяет выявить сценарии, в которых традиционные методы работают так же хорошо или лучше, чем подходы на основе LLM, и определить, когда затраты на увеличение с использованием LLM перевешивают его преимущества. Этот всесторонний анализ предоставляет представление о оптимальных стратегиях увеличения для различных случаев использования.
Сравнительный анализ LLM и традиционных методов увеличения текста представляет тщательное сравнение через обширный экспериментальный дизайн. Он исследует три ключевые техники увеличения: перефразирование, контекстную вставку слов и замену слов. Эти методы реализованы с использованием как традиционных подходов, таких как обратный перевод и контекстные эмбеддинги на основе BERT, так и продвинутых методов на основе LLM с использованием GPT-3.5 и Llama-3-8B. Исследование охватывает шесть разнообразных наборов данных, включающих задачи анализа настроений, классификации намерений и категоризации новостей, чтобы обеспечить широкую применимость результатов. Путем использования трех современных моделей классификаторов (DistilBERT, RoBERTa, BERT) и двух различных подходов к fine-tuning (полное fine-tuning и QLoRA), исследование предоставляет многогранный анализ эффектов увеличения в различных сценариях. Этот всесторонний дизайн позволяет провести 37 125 увеличенных выборок и впечатляющие 267 300 fine-tuning, обеспечивая надежное и нюансное сравнение методов увеличения.
Процесс оценки включает выбор начальных выборок, применение методов увеличения и fine-tuning классификаторов с использованием как исходных, так и увеличенных данных. Исследование варьирует количество начальных выборок и собранных выборок на начальную выборку, чтобы предоставить нюансное понимание эффектов увеличения. Ручные проверки достоверности обеспечивают качество увеличенных выборок. Множественные запуски fine-tuning с разными случайными начальными значениями улучшают надежность результатов. Этот всесторонний подход позволяет провести всесторонний анализ точности и экономической эффективности методов увеличения, решая основные исследовательские вопросы на сравнительную производительность и анализ затрат установленных методов по сравнению с методами на основе LLM.
Исследование сравнило методы увеличения текста на основе LLM и установленные методы по различным параметрам, выявив тонкие результаты. Перефразирование на основе LLM превзошло другие методы на основе LLM в 56% случаев, в то время как контекстная вставка слов привела вперед среди установленных методов с таким же процентом. Для полного fine-tuning перефразирование на основе LLM последовательно превышало контекстную вставку. Однако fine-tuning QLoRA показал разнонаправленные результаты, с контекстной вставкой часто превосходящей перефразирование на основе LLM для RoBERTa. Методы на основе LLM проявили более высокую эффективность при меньшем количестве начальных выборок (5-20 на метку), показывая увеличение точности на 3-17% для QLoRA и на 2-11% для полного fine-tuning. По мере увеличения числа начальных выборок разрыв в производительности между LLM и установленными методами сужался. Особенно RoBERTa достигла наивысшей точности по всем наборам данных, что указывает на то, что более дешевые установленные методы могут быть конкурентоспособны с методами увеличения на основе LLM для высокопроизводительных классификаторов, за исключением случаев с малым количеством начальных выборок.
Исследование провело обширное сравнение между новыми методами увеличения на основе LLM и установленными методами увеличения текста, анализируя их влияние на точность классификаторов. Исследование охватило 6 наборов данных, 3 классификатора, 2 подхода к fine-tuning, 2 увеличивающие LLM и различное количество начальных выборок на метку и увеличенных выборок на начальную выборку, в результате проведения 267 300 fine-tunings. Среди методов на основе LLM перефразирование выделилось как наиболее эффективный, в то время как контекстная вставка превзошла установленные методы. Результаты показывают, что методы на основе LLM преимущественно полезны в условиях ограниченных ресурсов, особенно при 5-20 начальных выборок на метку, где они показали статистически значимые улучшения и более высокие относительные увеличения точности модели по сравнению с установленными методами. Однако по мере увеличения количества начальных выборок это преимущество уменьшалось, и установленные методы стали чаще демонстрировать превосходную производительность. Учитывая значительно большие затраты на новые методы LLM, их использование оправдано только в условиях ограниченных ресурсов, где разница в затратах менее заметна.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Comparative Analysis of LLM and Traditional Text Augmentation: Accuracy, Efficiency, and Cost-Effectiveness.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























