«`html
Исследователи из Колумбийского университета и Databricks провели сравнительное исследование LoRA и полного донастройки в больших моделях языка
Модели машинного обучения, содержащие миллиарды параметров, требуют сложных методов для эффективного настройки их производительности. Исследователи стремятся улучшить точность этих моделей, минимизируя при этом необходимые вычислительные ресурсы. Это улучшение критически важно для практических применений в различных областях, таких как обработка естественного языка и искусственный интеллект, где эффективное использование ресурсов может значительно влиять на общую производительность и осуществимость.
Проблема в донастройке LLM
Одной из значительных проблем в донастройке LLM является значительное требование памяти графического процессора (GPU), что делает процесс дорогостоящим и ресурсоемким. Основная сложность заключается в разработке эффективных методов донастройки без ущерба производительности модели. Это особенно важно, поскольку модели должны адаптироваться к новым задачам, сохраняя при этом свои ранее изученные возможности. Эффективные методы донастройки гарантируют, что большие модели могут использоваться в различных приложениях без запредельных затрат.
Сравнение методов донастройки
Исследователи из Колумбийского университета и Databricks Mosaic AI исследовали различные методы решения этой проблемы, включая полную донастройку и методы донастройки, эффективные по параметрам, такие как адаптация низкого ранга (LoRA). Полная донастройка включает в себя настройку всех параметров модели, что вычислительно затратно. В отличие от этого, LoRA направлена на экономию памяти путем модификации только небольшого подмножества параметров, тем самым уменьшая вычислительную нагрузку. Несмотря на свою популярность, эффективность LoRA по сравнению с полной донастройкой была предметом споров, особенно в сложных областях, таких как программирование и математика, где точные улучшения производительности являются критическими.
Результаты исследования
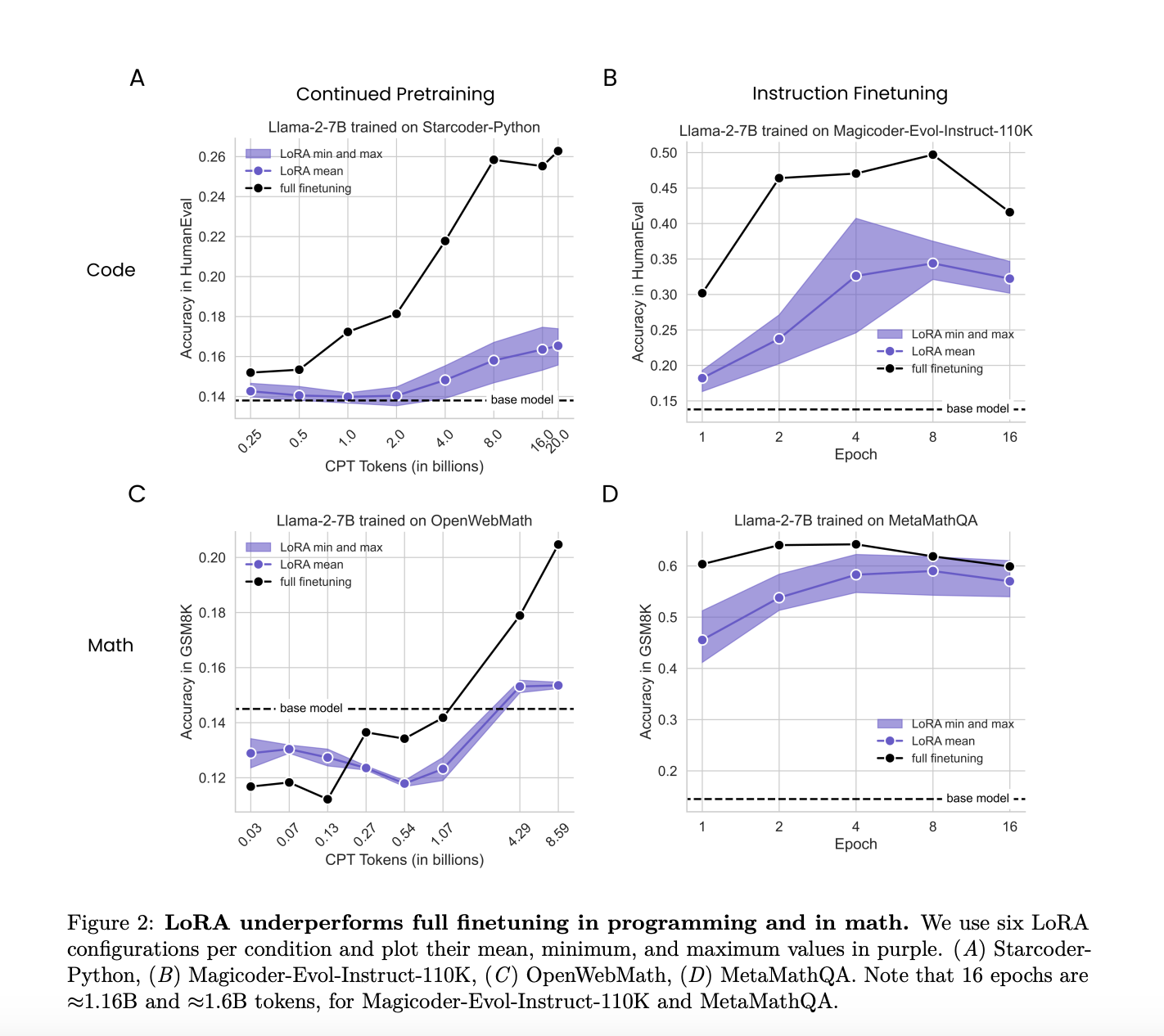
Исследование сравнило производительность LoRA и полной донастройки в двух целевых областях: программировании и математике. Была рассмотрена донастройка инструкций, включающая примерно 100 000 пар запрос-ответ, а также продолжение предварительной настройки с примерно 10 миллиардами неструктурированных токенов. Сравнение было направлено на оценку того, насколько хорошо LoRA и полная донастройка адаптируются к этим конкретным областям, учитывая различные режимы данных и сложность задач. Это всестороннее сравнение предоставило подробное понимание сильных и слабых сторон каждого метода в различных условиях.
Исследователи обнаружили, что LoRA в целом проигрывает по сравнению с полной донастройкой в задачах программирования и математики. Например, в области программирования полная донастройка достигла пика оценки HumanEval 0,263 на 20 миллиардах токенов, в то время как лучшая конфигурация LoRA достигла лишь 0,175 на 16 миллиардах токенов. Точно так же в области математики полная донастройка достигла пика оценки GSM8K 0,642 за 4 эпохи, в то время как лучшая конфигурация LoRA достигла 0,622 в той же точке. Несмотря на эту менее эффективную производительность, LoRA предоставляет полезную форму регуляризации, которая помогает сохранять производительность базовой модели в задачах за пределами целевой области. Этот регуляризационный эффект сильнее, чем у обычных техник, таких как уменьшение веса и отключение, что делает LoRA выгодным при сохранении производительности базовой модели, что критически важно.
Детальный анализ показал, что полная донастройка привела к весовым возмущениям, в 10-100 раз превосходящим те, которые обычно используются в конфигурациях LoRA. Например, для полной донастройки требовались ранги до 256, в то время как конфигурации LoRA обычно использовали ранги 16 или 256. Это значительное различие в ранге, вероятно, объясняет некоторые наблюдаемые различия в производительности. Исследование показало, что более низкие весовые возмущения LoRA способствовали поддержанию более разнообразных генераций выхода, чем полная донастройка, часто приводя к ограниченным решениям. Эта разнообразие в выходе полезно в приложениях, требующих разнообразных и креативных решений.
Заключение
Таким образом, хотя LoRA менее эффективен, чем полная донастройка по точности и эффективности выборки, он предлагает значительные преимущества в регуляризации и эффективности памяти. Исследование предлагает, что оптимизация гиперпараметров, таких как скорости обучения и целевых модулей, и понимание компромиссов между обучением и забыванием, могут улучшить применение LoRA к конкретным задачам. Исследование подчеркивает, что хотя полная донастройка в целом демонстрирует лучшую производительность, способность LoRA сохранять возможности базовой модели и генерировать разнообразные выходы делает его ценным в определенных контекстах. Это исследование предоставляет важные прозорливые взгляды на баланс производительности и вычислительной эффективности в донастройке LLM, предлагая путь к более устойчивому и универсальному развитию искусственного интеллекта.
Ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, группе в Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 42 тысячами участников.
Источник: MarkTechPost
«`

























