Анализ временных рядов с помощью искусственного интеллекта
Анализ временных рядов – сложная и вызывающая трудности область в науке о данных из-за последовательной природы и временных зависимостей, присущих данным. Классификация шагов в этом контексте включает присвоение классов отдельным временным шагам, что является ключевым для понимания паттернов и прогнозирования.
Практические решения и ценность:
- Исследование Ready Tensor провело обширное бенчмаркинговое исследование для оценки производительности 25 моделей машинного обучения на пяти различных наборах данных с целью улучшения точности классификации шагов временных рядов.
- Исследование оценило каждую модель с использованием четырех основных метрик оценки – точность, полнота, recall и F1-мера – на различных наборах временных рядов.
- Результаты показали значительные различия в производительности моделей, выявив сильные и слабые стороны различных подходов к моделированию.
- Выбор правильной модели на основе характеристик набора данных и задачи классификации является критическим для достижения высокой производительности.
- Публикация представляет собой ценный ресурс для выбора моделей и способствует текущему дискурсу о методологических достижениях в анализе временных рядов.
Обзор наборов данных
Бенчмаркинговое исследование использовало пять различных наборов данных, выбранных для представления разнообразных задач классификации временных рядов. Наборы данных включали реальные и синтетические данные, охватывающие различные временные частоты и длины рядов.
Примеры наборов данных:
- HAR70Plus: Набор данных, происходящий из набора данных распознавания активности человека (HAR), состоящий из 18 рядов с семью классами и шестью признаками.
- HMM Continuous: Синтетический набор данных, включающий 500 рядов с четырьмя классами и тремя признаками.
- Multi-Frequency Sinusoidal: Еще один синтетический набор данных с 100 рядами, пятью классами и двумя признаками.
- Occupancy Detection: Реальный набор данных с одним рядом, двумя классами и пятью признаками.
- PAMAP2: Набор данных по активности человека, содержащий девять рядов, 12 классов и 31 признак, с длиной ряда от 64 до 2725 временных шагов.
Оцененные модели
Бенчмаркинговое исследование Ready Tensor разделило 25 оцененных моделей на три основных типа: модели машинного обучения, модели нейронных сетей и специальную категорию под названием модель Distance Profile.
Примеры моделей:
- Модели машинного обучения: Включают 17 моделей, выбранных за их способность обрабатывать последовательные зависимости в данных временных рядов, такие как Random Forest, K-Nearest Neighbors (KNN) и Logistic Regression.
- Модели нейронных сетей: Семь моделей с продвинутыми архитектурами нейронных сетей, такие как Long-Short-Term Memory (LSTM) и Convolutional Neural Networks (CNN).
- Модель Distance Profile: Уникальный подход, основанный на вычислении расстояний между точками данных временных рядов, предоставляющий другую перспективу на классификацию временных рядов.
Результаты и выводы
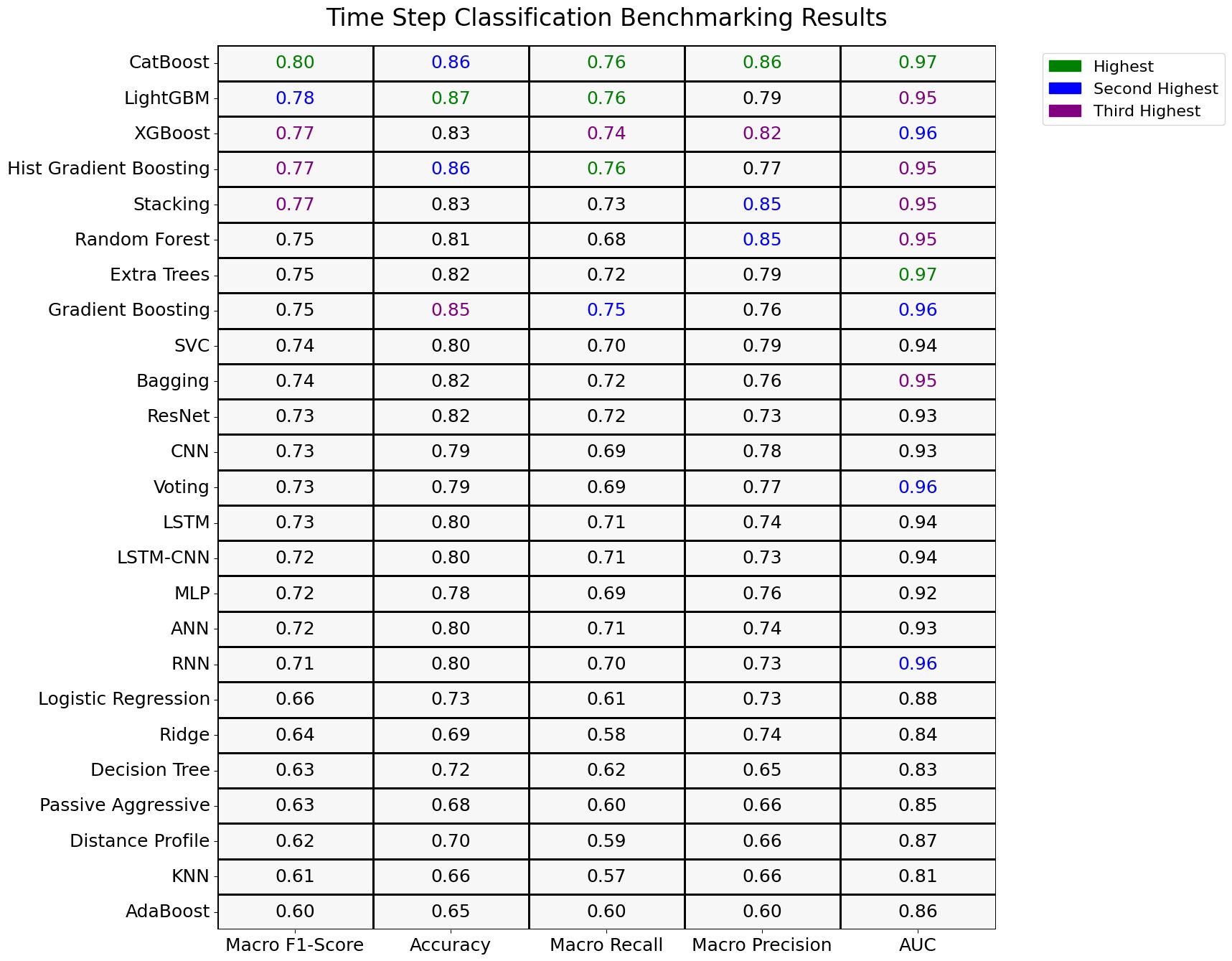
Исследование оценило каждую модель индивидуально на всех наборах данных, усреднив метрики производительности для получения общей оценки. Данные были представлены в виде тепловой карты, где модели перечислены по вертикали, а метрики – точность, полнота, recall и F1-мера – по горизонтали.
Лучшие модели:
- Boosting алгоритмы и продвинутые ансамблевые методы показали отличные результаты. CatBoost достиг F1-меры 0.80, за ним следуют LightGBM с 0.78, Hist Gradient Boosting с 0.77, а также XGBoost и Stacking с 0.77.
- Надежные выборы: Модели, такие как Gradient Boosting и Extra Trees, набрали 0.75, в то время как Random Forest продемонстрировал хорошую производительность на уровне 0.75.
- Модели с базовой производительностью: Модели, такие как Bagging и SVC, показали 0.74, а нейронные сети, такие как CNN, RNN и LSTM, – 0.73.
- Модели с ниже-средней производительностью: Модели, такие как Logistic Regression (0.66), Ridge (0.64) и Decision Tree (0.63), испытывали трудности с захватом сложных временных зависимостей.
Заключение
Бенчмаркинговое исследование Ready Tensor предлагает подробную оценку 25 моделей на пяти наборах данных для классификации шагов временных рядов. Результаты подчеркивают эффективность алгоритмов Boosting, таких как CatBoost, LightGBM и XGBoost, в управлении данными временных рядов. Тепловая карта исследования обеспечила всестороннее сравнение, выявляя сильные и слабые стороны различных подходов к моделированию. Эта публикация служит ценным руководством для исследователей и практиков, помогая выбирать подходящие модели для задач классификации шагов временных рядов и способствуя разработке более эффективных решений в этой развивающейся области.