ARCLE: Окружение обучения с подкреплением для абстрактных задач рассуждения
Reinforcement learning (RL) — это специализированное направление искусственного интеллекта, которое обучает агентов последовательно принимать решения, вознаграждая их за выполнение желательных действий. Эта техника широко применяется в робототехнике, играх и автономных системах, позволяя машинам развивать сложные поведенческие модели методом проб и ошибок. RL позволяет агентам учиться на основе их взаимодействия с окружающей средой, корректируя свои действия на основе обратной связи для максимизации накопленных вознаграждений со временем.
Решение:
Одним из значительных вызовов в RL является решение задач, требующих высокого уровня абстракции и рассуждения, таких как те, которые представлены корпусом Абстракции и Рассуждений (ARC). Для решения этих задач исследователи из Gwangju Institute of Science and Technology и Korea University представили ARCLE (ARC Learning Environment). ARCLE — это специализированная среда обучения с подкреплением, разработанная для исследований в области ARC. Она позволяет обучать агентов с использованием методов обучения с подкреплением, специально адаптированных для сложных задач, представленных в ARC.
Компоненты ARCLE:
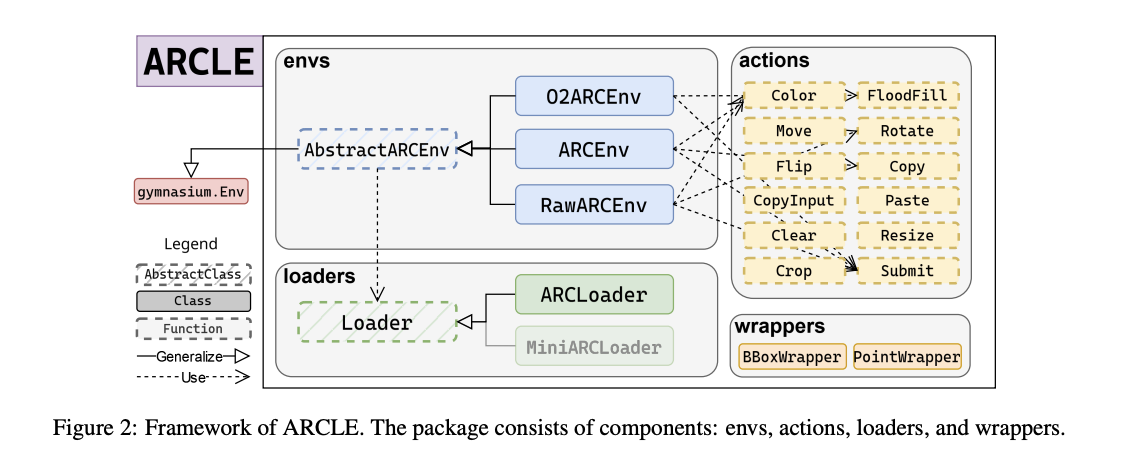
ARCLE включает несколько ключевых компонентов: окружения, загрузчики, действия и оболочки. Компонент окружения определяет структуру пространства действий и состояний, а также методы, которые могут быть определены пользователем. Загрузчики поставляют набор данных ARC в среды ARCLE, определяя, как должны быть разобраны и выбраны наборы данных. Действия в ARCLE определены для выполнения различных манипуляций с сеткой, таких как раскраска, перемещение и вращение пикселей. Оболочки модифицируют пространство действий или состояний среды, улучшая процесс обучения за счет предоставления дополнительных функций.
Результаты и выводы:
Исследование показало, что агенты, обученные в ARCLE с использованием оптимизации проксимальной политики (PPO), успешно учатся выполнять индивидуальные задачи. Внедрение вспомогательных потерь и нефакториальных политик существенно улучшило производительность. Агенты, обученные с использованием этих продвинутых техник, показали заметные улучшения в выполнении задач. Например, агенты, основанные на PPO, достигли высокой степени успеха в решении задач ARC, когда их обучали с использованием вспомогательных функций потерь, предсказывающих предыдущие вознаграждения, текущие вознаграждения и следующие состояния.
Выводы:
Для развития стратегий RL для абстрактных задач рассуждения ARCLE представляет значительный потенциал. Интеграция ARCLE в исследования по RL решает текущие проблемы ARC и способствует развитию искусственного интеллекта, способного эффективно учиться, рассуждать и абстрагироваться.
Если вы хотите использовать ARCLE и узнать больше об искусственном интеллекте, обращайтесь к нам по адресу https://t.me/flycodetelegram. Также вы можете опробовать ИИ-ассистента в продажах на странице https://flycode.ru/aisales/.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























