«`html
Решения ИИ для обработки речи
Обработка речи направлена на разработку систем для анализа, интерпретации и генерации человеческой речи. Эти технологии охватывают широкий спектр приложений, таких как автоматическое распознавание речи (ASR), верификация диктора, перевод речи в текст и диаризация диктора. Поскольку все больше полагаются на виртуальных помощников, транскрипционные сервисы и многоязычные коммуникационные инструменты, эффективная и точная обработка речи становится необходима.
Проблемы и решения
Одной из основных проблем в этой области является вычислительная неэффективность существующих моделей самообучения. Многие из них, хотя и эффективны, требуют много ресурсов из-за использования таких техник, как кластеризация речи и ограниченное подвыборное сэмплирование. Решение этих проблем критично для создания более быстрых и масштабируемых систем, которые можно развернуть в различных практических сценариях.
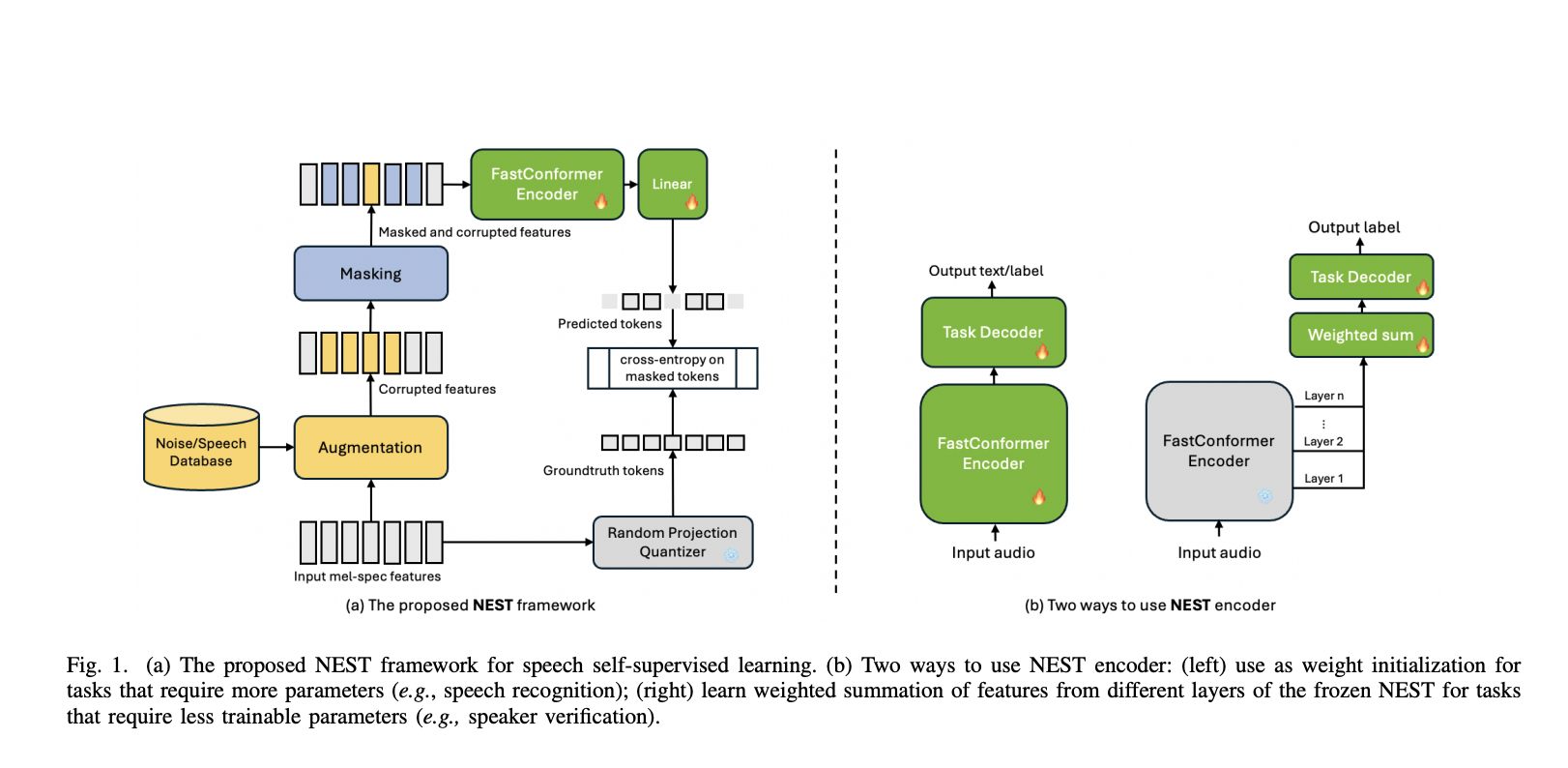
Решение от NVIDIA: NEST
Исследователи NVIDIA представили новое решение, NEST, которое решает эти проблемы. NEST построен на архитектуре FastConformer и предлагает эффективную и упрощенную систему для самообучения в обработке речи. В отличие от предыдущих моделей, NEST имеет 8-кратное подвыборное сэмплирование, что делает его быстрее по сравнению с архитектурами, использующими 20 мс или 40 мс длину кадра. Это значительно уменьшает вычислительную сложность модели, улучшая её способность обрабатывать большие наборы речи с высокой точностью.
Методология NEST включает несколько инновационных подходов для улучшения обработки речи. Одной из ключевых особенностей является его техника квантования на основе случайных проекций, которая заменяет дорогостоящие методы кластеризации, используемые другими моделями. Этот процесс существенно сокращает время и ресурсы, необходимые для обучения, при сохранении современной производительности. NEST также включает обобщенную технику увеличения зашумленной речи, которая улучшает способность модели отделять основного диктора от фонового шума или других дикторов, случайно вставляя речевые сегменты из разных источников во входные данные.
Отличительные особенности и результаты
Архитектура модели NEST разработана для максимизации эффективности и масштабируемости. Она применяет сверточное подвыборное сэмплирование к входным признакам Мел-спектрограмм перед их обработкой слоями FastConformer. Этот шаг сокращает длину входной последовательности, что приводит к более быстрым временам обучения без ущерба точности. Более того, метод квантования на основе случайных проекций использует фиксированный словарь с 8192 словами и 16-мерными признаками, дополнительно упрощая процесс обучения, не теряя при этом сущность входной речи.
Результаты экспериментов, проведенные исследовательской командой NVIDIA, впечатляют. В различных задачах обработки речи NEST последовательно превосходит существующие модели. Например, в задачах диаризации диктора и автоматического распознавания речи NEST достиг значительного улучшения точности по сравнению с другими моделями. Кроме того, в задачах распознавания фонем NEST продемонстрировал способность решать различные задачи обработки речи.
Заключение
NEST представляет собой значительный прорыв в области обработки речи. Его быстрота, эффективность и точность на разнообразных задачах обработки речи подчеркивают его потенциал как масштабируемого решения для реальных вызовов обработки речи.
«`

























