CS-Bench: оценка производительности LLM в области информатики
Искусственный интеллект (ИИ) сегодня играет важную роль в различных отраслях, и его применение становится все более значимым. Однако для эффективной работы с большими языковыми моделями (LLMs) в области информатики существует целый ряд вызовов. Существующие исследования не оценивают полностью производительность LLM в информатике, что не позволяет развивать их способности в этой области.
Оценка производительности LLM в информатике
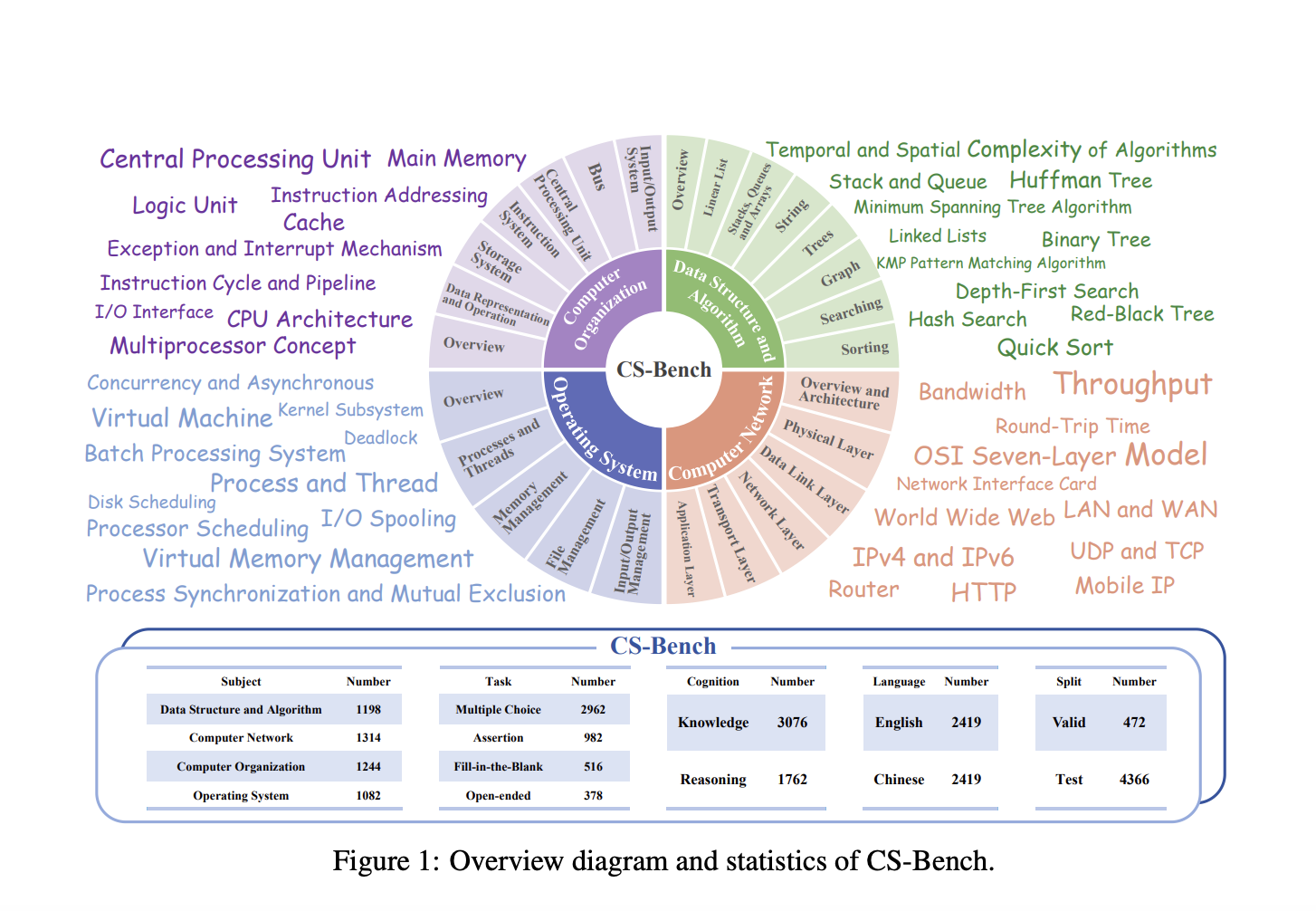
Исследователи из Пекинского университета почтовых и телекоммуникаций предлагают CS-Bench — первый бенчмарк, посвященный оценке производительности LLM в информатике. CS-Bench включает около 5000 тщательно отобранных тестов, охватывающих 26 разделов в четырех основных областях информатики. Бенчмарк оценивает как вопросы на знание, так и вопросы на рассуждение, поддерживая двуязычную оценку на китайском и английском языках.
Результаты оценки
Результаты оценки показывают, что общие баллы моделей варьируются от 39.86% до 72.29%. LLM-модели GPT-4 и GPT-4o продемонстрировали наивысший уровень профессионализма на CS-Bench. Открытые модели, такие как Qwen1.5-110B и Llama3-70B, превзошли ранее сильные закрытые модели. Усовершенствованные модели демонстрируют значительные улучшения по сравнению с предыдущими версиями. Все модели в целом показали лучшие результаты по вопросам на знание по сравнению с результатами по рассуждению, что указывает на то, что рассуждение представляет более серьезное испытание. LLM в целом справляются лучше всего в области структуры данных и алгоритмов и хуже всего в операционных системах. Более сильные модели продемонстрировали лучшую способность использовать знание для рассуждения и проявляют большую устойчивость к различным форматам задач.
Заключение
CS-Bench предоставляет ценные исследовательские данные, позволяющие понять производительность LLM в области информатики. Даже самые успешные модели, такие как GPT-4o, имеют значительный потенциал для улучшения. Бенчмарк выделяет тесные взаимосвязи между информатикой, математикой и навыками кодирования в LLM. Эти результаты предлагают направления для улучшения LLM в этой области и являются ценными исследовательскими данными для будущих достижений в области ИИ и информатики.

























