Понимание документов в рамках ИИ: практическое применение и ценность
Понимание документов (Document Understanding, DU) сосредотачивается на автоматической интерпретации и обработке документов с учетом сложных структур композиции и мультимодальных элементов, таких как текст, таблицы, графики и изображения. Эта задача важна для извлечения и использования огромного объема информации, содержащейся в ежегодно создаваемых документах.
Практические решения и ценность
Одной из критических проблем является понимание длинных документов, охватывающих множество страниц и требующих комплексного восприятия различных модальностей и страниц. Традиционные модели DU для одностраничных документов не справляются с этим, что делает важным разработку методов оценки производительности моделей на длинных документах. Исследователи выявили, что для таких длинных документов необходимы специфические возможности, такие как локализация и понимание через различные страницы, что недостаточно рассматривается в текущих наборах данных для DU.
Новые методы DU включают в себя большие модели видео-языкового восприятия (LVLM) такие как GPT-4o, Gemini-1.5 и Claude-3, разработанные компаниями OpenAI и Anthropic. Эти модели показали перспективы в решении задач на одной странице, но нуждаются в помощи в понимании длинных документов из-за необходимости мультимодального понимания и интеграции мультимодальных элементов. Этот разрыв в возможностях подчеркивает важность создания всеобъемлющих бенчмарков для развития более продвинутых моделей.
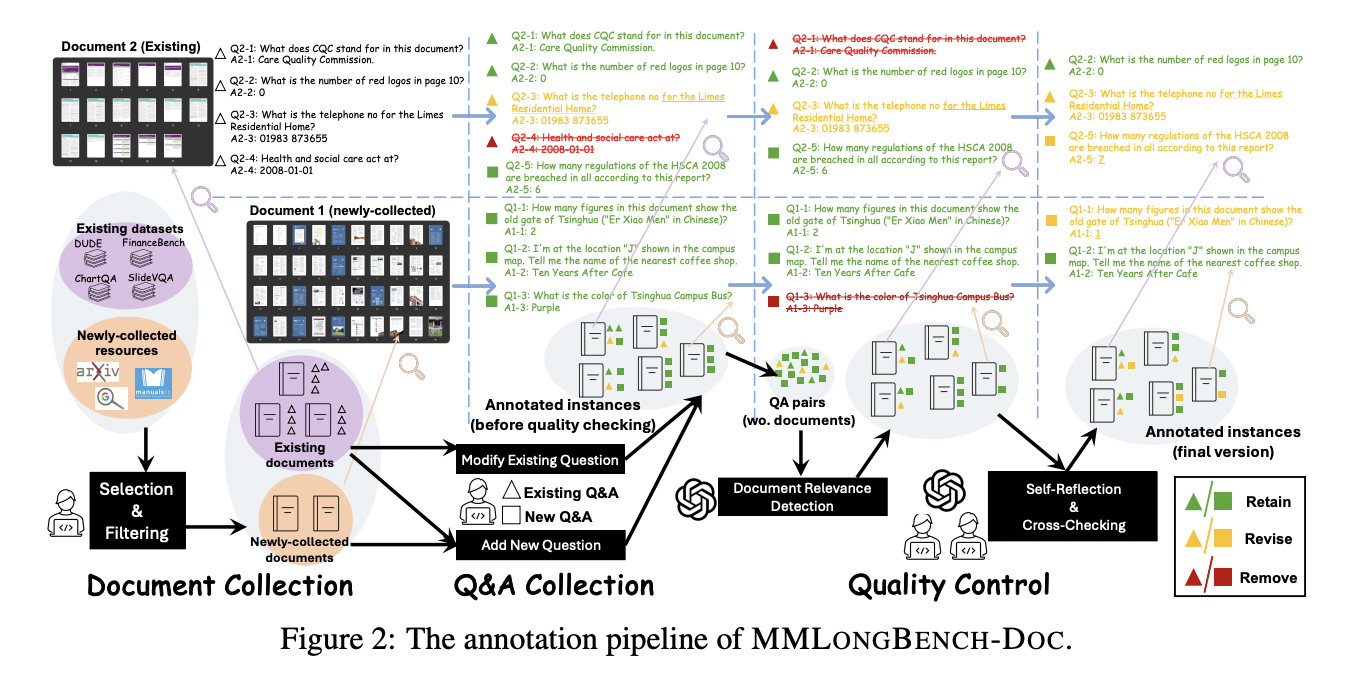
Исследователи из таких учреждений, как Университет Наньян, Шанхайская лаборатория ИИ и Университет Пекина, представили MMLongBench-Doc, всесторонний бенчмарк, разработанный для оценки возможностей LVLM в понимании длинных документов. Этот бенчмарк включает 135 документов в формате PDF из различных областей, в среднем по 47.5 страниц и 21 214.1 текстовых токенов. Он содержит 1091 вопрос, требующих доказательств из текста, изображений, графиков, таблиц и структур композиции, причем значительная часть требует мультимодального понимания через разные страницы. Этот строгий бенчмарк направлен на расширение границ текущих моделей DU.
Методология включает использование снимков страниц документов в качестве входных данных для LVLM, сравнение их производительности с традиционными моделями текстового распознавания оптических знаков (OCR). Создание бенчмарка было тщательным, с участием десяти экспертов-аннотаторов, которые редактировали вопросы из существующих наборов данных и создавали новые для всеобъемлющего понимания. Процесс аннотации обеспечил высокое качество благодаря трехраундовому полуавтоматическому процессу проверки. Такой подход подчеркнул необходимость моделей в обработке длинных документов, делая MMLongBench-Doc важным инструментом для оценки и улучшения моделей DU.
Оценки производительности показали, что LVLM в целом испытывают трудности с длинным DU. Например, лучшая по производительности модель GPT-4o достигла F1-оценки 44.9%, в то время как вторая по производительности модель GPT-4V набрала 30.5%. Другие модели, такие как Gemini-1.5 и Claude-3, показали еще более низкую производительность. Эти результаты указывают на значительные трудности в длинном DU и необходимость дальнейшего развития. Исследование сравнило эти результаты с моделями на основе OCR, отметив, что некоторые LVLM показали худшую производительность по сравнению с одномодальными LLM при обработке ущербного текста, распознанного посредством OCR.
Подробные результаты показали, что, хотя LVLM могут обрабатывать мультимодальные входы в определенной степени, их возможности все еще требуют улучшений. Например, 33.0% вопросов в бенчмарке были мультимодальными, требующими мультимодального понимания через несколько страниц, и 22.5% были созданы так, чтобы на них было невозможно ответить, для выявления возможных галлюцинаций. Этот строгий тест подчеркнул необходимость более продвинутых LVLM. Закрытые модели показали лучшую производительность по сравнению с открытыми моделями, что объясняется их большим количеством принимаемых изображений и максимальными разрешениями изображений.
В заключение, данное исследование подчеркивает сложность понимания длинных документов и необходимость развития продвинутых моделей, способных эффективно обрабатывать и понимать длинные мультимодальные документы. Разработанный при сотрудничестве с ведущими исследовательскими учреждениями бенчмарк MMLongBench-Doc является ценным инструментом для оценки и улучшения производительности этих моделей. Находки исследования выделяют значительные трудности существующих моделей и необходимость дальнейших исследований и разработок в этой области для достижения более эффективных и всесторонних решений DU.









