“`html
Оценка способностей ИИ к временному рассуждению: новый ToT Benchmark
В сфере искусственного интеллекта (ИИ) ключевую роль играет временное рассуждение – понимание и интерпретация взаимосвязей событий во времени. Это необходимо для разработки ИИ, способного выполнять различные задачи, от обработки естественного языка до принятия решений в динамических средах. Используя точное интерпретирование данных, связанных со временем, ИИ способен выполнять сложные операции, такие как планирование, прогнозирование и анализ исторических данных. В результате временное рассуждение становится фундаментальным аспектом разработки передовых систем ИИ.
Оценка способностей ИИ к временному рассуждению: вызовы и решения
Существующие бенчмарки временного рассуждения часто нуждаются в корректировке, поскольку они сильно зависят от реальных данных, с которыми модели могли столкнуться во время обучения, или используют техники анонимизации, которые могут привести к неточностям. Это создает потребность в более надежных методах оценки, которые точно измеряют способности моделей к временному рассуждению. Основной вызов заключается в создании бенчмарков, которые тестируют запоминание и действительно оценивают навыки рассуждения, что критически важно для приложений, требующих точного и контекстно-ориентированного понимания времени.
В настоящее время идет работа по созданию синтетических наборов данных для проверки способностей моделей, таких как логическое и математическое рассуждение. Широко используются такие фреймворки, как TempTabQA, TGQA и бенчмарки на основе графов знаний. Однако эти методы ограничены встроенными предубеждениями и предварительными знаниями в моделях. Это часто приводит к оценкам, которые не отражают действительные способности моделей в рассуждении, а скорее их способность запоминать изученную информацию. Фокус на известных сущностях и фактах должен адекватно проверять понимание моделями временной логики и арифметики, что приводит к неполной оценке их реальных способностей.
Для решения этих вызовов исследователи из Google Research, Google DeepMind и Google представили бенчмарк Test of Time (ToT). Этот инновационный бенчмарк использует синтетические наборы данных, специально разработанные для оценки временного рассуждения без использования предварительных знаний моделей. Бенчмарк предоставлен в открытом доступе для поощрения дальнейших исследований и разработок в этой области. Введение ToT представляет собой значительный прогресс, обеспечивая контролируемую среду для систематического тестирования и улучшения навыков временного рассуждения моделей ИИ.
Структура и результаты ToT Benchmark
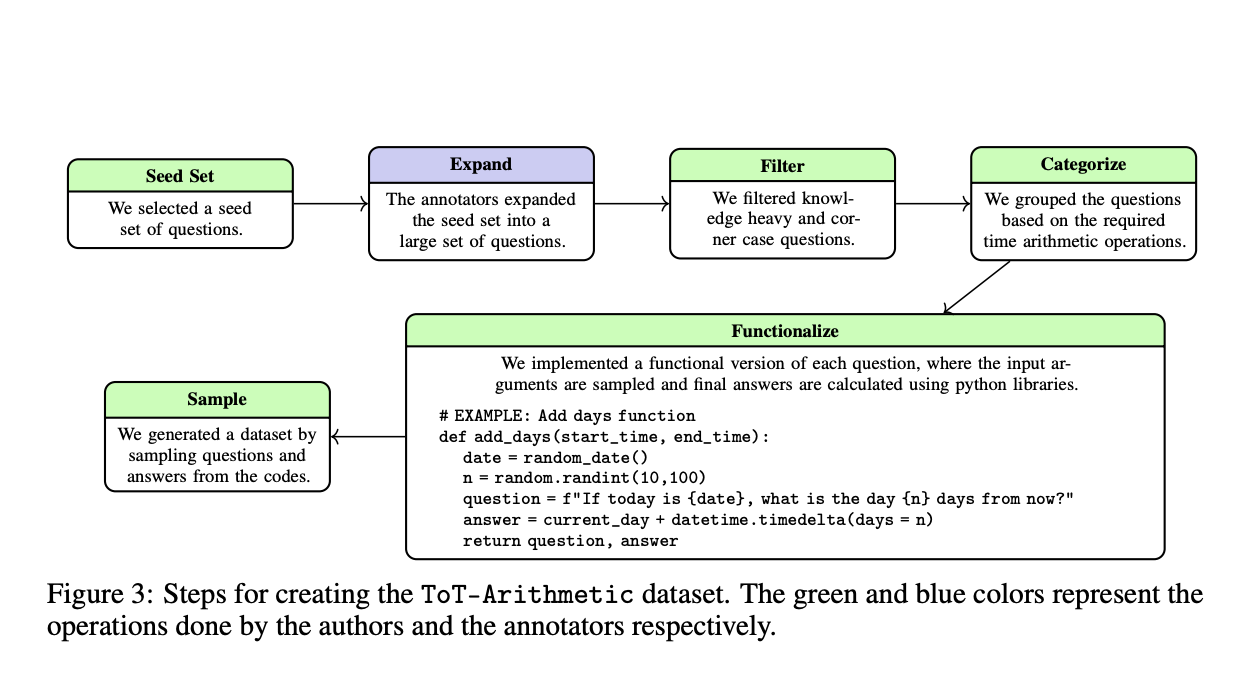
Бенчмарк ToT состоит из двух основных задач. ToT-Semantic фокусируется на временной семантике и логике, позволяя гибко исследовать разнообразные графовые структуры и сложности рассуждений. Эта задача выделяет основные способности рассуждения от предварительных знаний. ToT-Arithmetic оценивает способность выполнять вычисления, связанные с моментами времени и продолжительностью, используя задачи, созданные с привлечением сообщества, чтобы обеспечить практическую значимость. Эти задачи тщательно разработаны для охвата различных сценариев временного рассуждения, обеспечивая комплексную систему оценки.
Для создания задачи ToT-Semantic исследователи генерировали случайные графовые структуры с использованием алгоритмов, таких как модели Эрдёша-Реньи и Барабаши–Альберта. Эти графы затем использовались для создания разнообразных вопросов о времени, позволяя провести глубокую оценку способности моделей ИИ понимать и рассуждать о времени. Для ToT-Arithmetic задачи были разработаны для проверки практических арифметических операций, связанных с временем, таких как вычисление продолжительности и обработка конвертации часовых поясов. Двойной подход обеспечивает комплексную оценку как логических, так и арифметических аспектов временного рассуждения.
Экспериментальные результаты с использованием бенчмарка ToT позволяют сделать значительные выводы о сильных и слабых сторонах текущих моделей ИИ. Например, производительность GPT-4 значительно различалась в зависимости от графовых структур, с точностью от 40,25% на полных графах до 92,00% на графах AWE. Эти результаты подчеркивают влияние временной структуры на производительность рассуждения. Кроме того, порядок представления фактов моделям существенно влиял на их производительность, с наивысшей точностью, наблюдаемой при сортировке фактов и начального времени.
В рамках исследования также изучались типы временных вопросов и их уровни сложности. Одиночные вопросы на основе одного факта были легче для моделей, в то время как множественные вопросы, требующие интеграции нескольких фактов, представляли большие вызовы. Например, GPT-4 достигал точности 90,29% на вопросах типа EventAtWhatTime, но испытывал затруднения с вопросами типа Timeline, указывая на сложности в обработке сложных временных последовательностей. Детальный анализ типов вопросов и производительности моделей предоставляет ясное представление о текущих возможностях и областях, требующих улучшения.
Заключение: перспективы развития временного рассуждения в ИИ
Бенчмарк ToT представляет собой значительный прогресс в оценке способностей моделей ИИ к временному рассуждению. Обеспечивая более комплексную и контролируемую систему оценки, он помогает выявить области для улучшения и направляет развитие более способных систем ИИ. Этот бенчмарк ставит начало для будущих исследований по улучшению способностей моделей ИИ в временном рассуждении, что в конечном итоге способствует достижению общего искусственного интеллекта.
“`


























