«`html
Преодоление модельного обвала с помощью укрепленных синтетических данных
По мере того как данные, созданные искусственным интеллектом, все чаще дополняют или даже заменяют данные, размеченные людьми, возникают опасения относительно ухудшения производительности моделей при итеративном их обучении на синтетических данных. Модельный обвал означает явление, при котором производительность модели значительно ухудшается при обучении на синтетических данных, сгенерированных с использованием этой модели. Эта проблема значительна, поскольку затрудняет разработку более эффективных и эффективных методов создания высококачественных сводок из больших объемов текстовых данных.
Практические решения и ценность
Для преодоления модельного обвала используются несколько подходов, включая использование обучения с подкреплением с обратной связью человека (RLHF), курирование данных и инженерия подсказок. RLHF использует обратную связь человека для обеспечения качества данных, используемых для обучения, тем самым поддерживая или улучшая производительность модели. Однако этот подход дорогостоящ и не масштабируем, поскольку сильно зависит от человеческих аннотаторов.
Другой метод включает тщательное курирование и фильтрацию синтезированных данных. Это может включать использование эвристик или заранее определенных правил для отбраковки низкокачественных или несущественных данных перед их использованием для обучения. Хотя этот метод может помочь смягчить негативное влияние низкокачественных синтезированных данных, часто требуется значительное усилие для поддержания качества обучающего набора данных, и он только частично устраняет риск модельного обвала, если критерии фильтрации достаточно надежны. Кроме того, инженерия подсказок — это метод, который включает создание конкретных подсказок, направляющих модель на генерацию более высококачественных результатов. Инженерия подсказок не является безошибочным методом и может быть ограничена встроенными предубеждениями и слабостями самой модели. Кроме того, для достижения оптимальных результатов часто требуется экспертное знание и итерационные эксперименты.
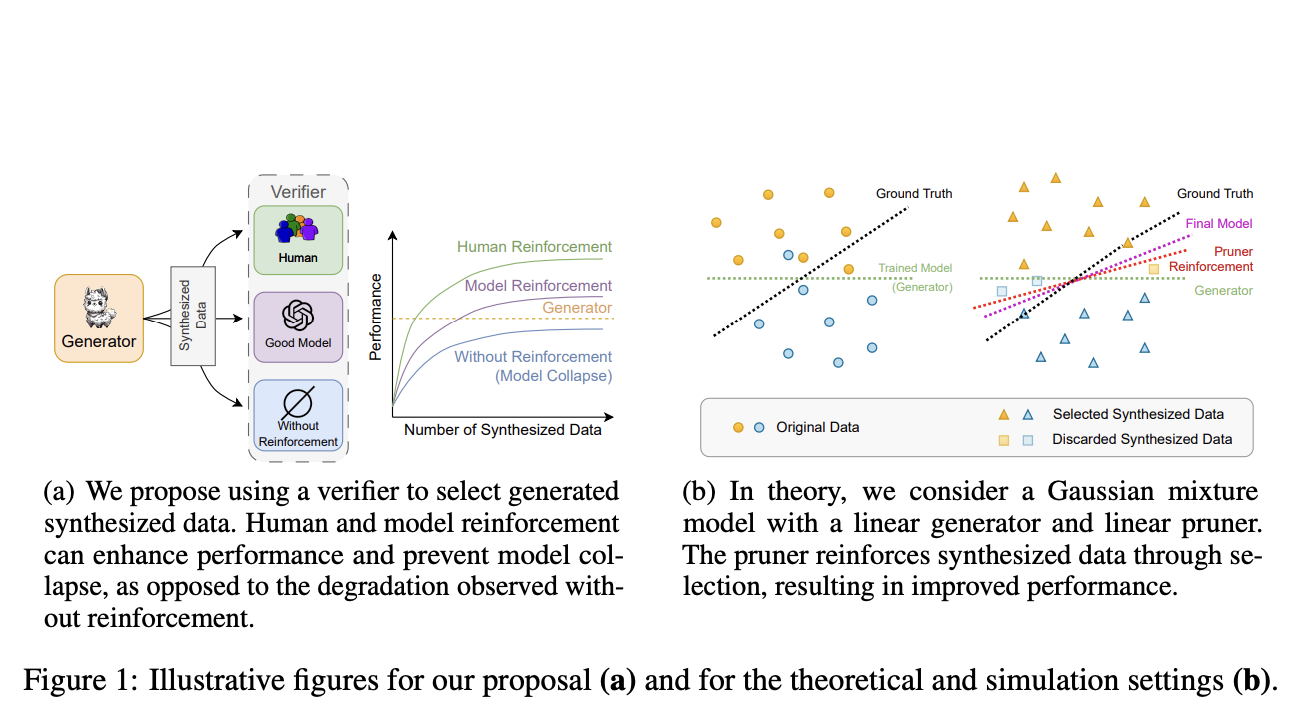
Для преодоления этих ограничений исследовательская группа из Meta AI, Нью-Йоркского университета и Пекинского университета предлагает метод, включающий обратную связь по синтезированным данным с целью предотвращения модельного обвала с помощью методов обучения с подкреплением. Их подход включает использование механизмов обратной связи для выбора или обрезки синтезированных данных, обеспечивая использование только высококачественных данных для дальнейшего обучения. Этот метод предполагается более эффективным и масштабируемым альтернативным вариантом RLHF, поскольку может быть частично или полностью автоматизирован.
Основу предлагаемой методологии составляет усиление синтезированных данных с помощью механизмов обратной связи, которые могут быть от человека или других моделей. Исследователи предоставляют теоретическую основу, демонстрирующую, что модель классификации смеси Гаусса может достичь оптимальной производительности при обучении на усиленных обратной связью синтезированных данных.
Два практических эксперимента подтверждают теоретические предсказания. Первый эксперимент включает обучение трансформаторов для вычисления собственных значений матрицы, задача, которая сталкивается с модельным обвалом при обучении на чисто синтетических данных. Производительность модели значительно улучшается путем обрезки неверных предсказаний и выбора лучших догадок из синтезированных данных, демонстрируя эффективность усиления через выбор данных. Второй эксперимент фокусируется на сводках новостей с использованием больших языковых моделей (LLM) таких как LLaMA-2. Здесь усиленные обратной связью данные предотвращают ухудшение производительности, даже при увеличении объема синтетических данных, подтверждая гипотезу о том, что усиление существенно для поддержания целостности модели.
Исследователи используют стратегию декодирования для генерации сводок и оценивают их производительность с использованием метрики Rouge-1. Они также используют сильную модель-проверку, Llama-3, для выбора лучших синтезированных данных для обучения. Результаты показывают, что предложенный метод значительно превосходит исходную модель, обученную на полном наборе данных, даже при использовании только 12,5% данных. Было отмечено, что модель, обученная на синтезированных данных, выбранных оракулом, достигает лучшей производительности, что указывает на то, что предложенный метод эффективно смягчает модельный обвал. Это значительное открытие, поскольку оно предполагает, что при правильном усилении синтетические данные высокого качества могут соответствовать и, возможно, превзойти качество данных, созданных человеком.
Исследование предлагает многообещающее решение проблемы модельного обвала в LLM, обученных на синтетических данных. Путем внедрения механизмов обратной связи для улучшения качества синтетических данных предложенный метод обеспечивает устойчивую производительность модели без необходимости обширного человеческого вмешательства. Этот подход предоставляет масштабируемую, экономически эффективную альтернативу текущим методам RLHF, прокладывая путь для более надежных и надежных систем искусственного интеллекта в будущем.
«`

























