Повышение понимания документов с помощью интеграции OCR и Vision в модели GPT-4
Понимание документов — это критическая область, которая фокусируется на преобразовании документов в осмысленную информацию. Это включает в себя чтение и интерпретацию текста, понимание макета, нематериальных элементов и стиля текста. Возможность понимать пространственное расположение, визуальные подсказки и текстовую семантику является ключевой для точного извлечения и интерпретации информации из документов.
Практические решения и ценность
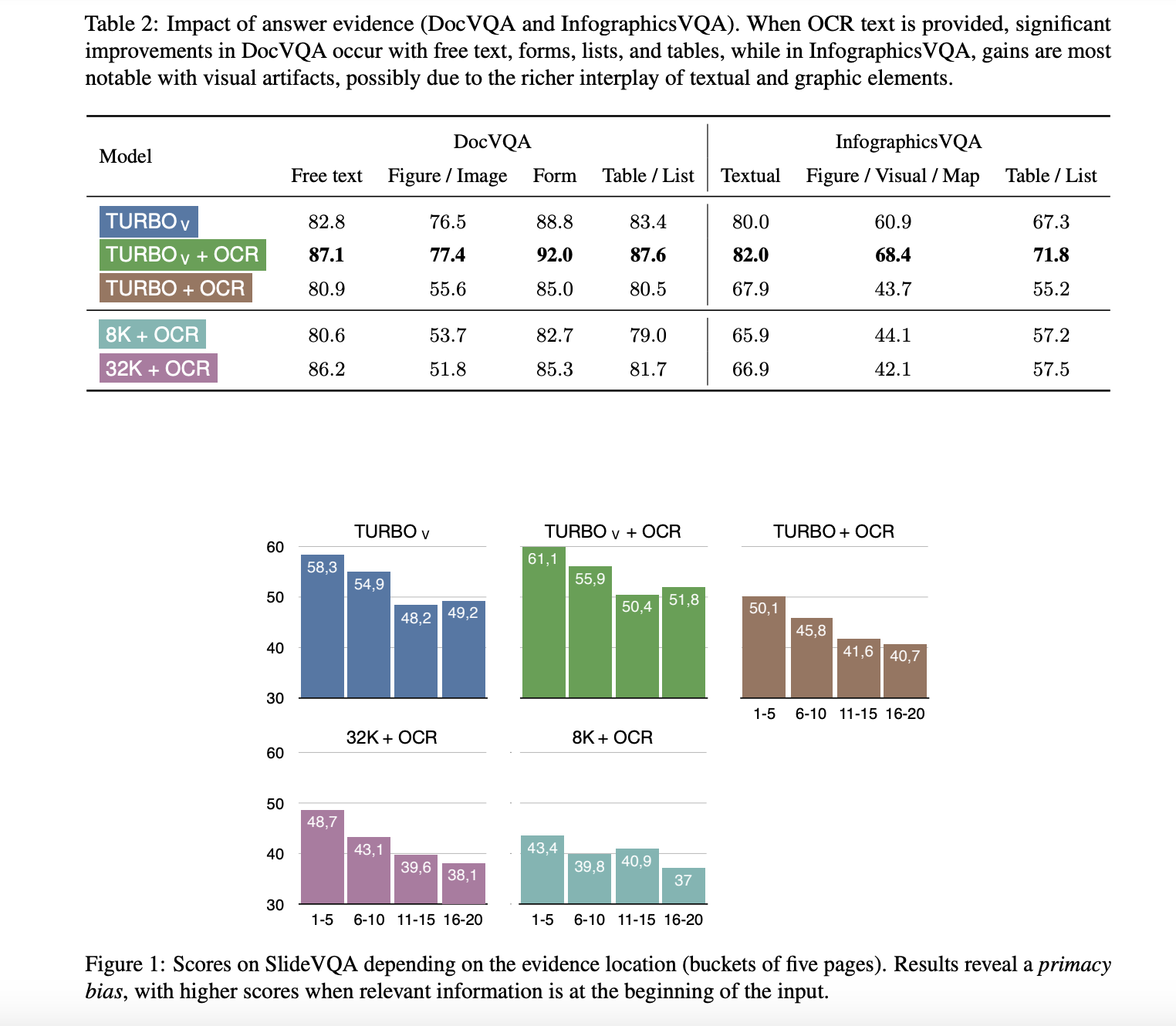
Для эффективного извлечения информации из документов смешанного типа, содержащих текстовые и визуальные элементы, используются модели, которые могут обрабатывать как текст, так и изображения одновременно. Например, модель GPT-4 Vision Turbo достигла значительного улучшения производительности с ANLS-оценкой 87,4 на DocVQA и 71,9 на InfographicsVQA при использовании как текста OCR, так и изображений в качестве входных данных. Это демонстрирует важность интеграции визуальной информации для точного понимания документов.
Исследование также выявило, что модель GPT-4 Vision Turbo превзошла более тяжелые модели, работающие только с текстом, в большинстве задач. Лучшая производительность достигается с высоким разрешением изображений (2048 пикселей по более длинной стороне) и текстом OCR, подчеркивая важность качества изображений и точности OCR для улучшения производительности понимания документов.
В заключение, исследование продвинуло понимание документов, демонстрируя эффективность интеграции текста, распознанного OCR, с изображениями документов. Модель GPT-4 Vision Turbo продемонстрировала выдающиеся результаты на различных наборах данных, достигая передовых результатов в задачах, требующих текстового и визуального понимания. Этот подход решает ограничения моделей, работающих только с текстом, и обеспечивает более полное понимание документов.

























