“`html
Синтетическое создание данных для оптимизации работы с большими языковыми моделями
Синтетическое создание данных приобретает все большую популярность в области машинного обучения. Эта техника создает обширные наборы данных, когда реальные данные ограничены и дороги. Исследователи могут более эффективно обучать модели машинного обучения, генерируя синтетические данные, улучшая их производительность в различных приложениях. Сгенерированные данные создаются таким образом, чтобы проявлять определенные характеристики, полезные для обучения моделей.
Проблемы и методы оптимизации пространства данных
Однако интеграция синтетических данных в модели машинного обучения представляет несколько вызовов, особенно в отношении искажений и характеристик, которые могут быть внесены синтетическими данными. Понимание того, как эти унаследованные характеристики влияют на поведение и производительность больших языковых моделей (LLM), является критическим. Основная проблема заключается в том, может ли синтетические данные внести непреднамеренные искажения или другие характеристики, которые могут повлиять на результаты модели. Это понимание важно для обеспечения того, что модели, обученные с использованием синтетических данных, являются эффективными и справедливыми, избегая усиления негативных черт процесса генерации данных.
Текущие методы оптимизации пространства данных включают аугментацию данных, псевдо-маркировку, взвешивание данных, обрезку данных и куррикулярное обучение. Однако эти методы ограничены свойствами, присущими исходным наборам данных, и часто нуждаются в способности внедрять новые, желательные характеристики, что ограничивает их эффективность в оптимизации моделей для конкретных характеристик.
Активное наследие и его значимость
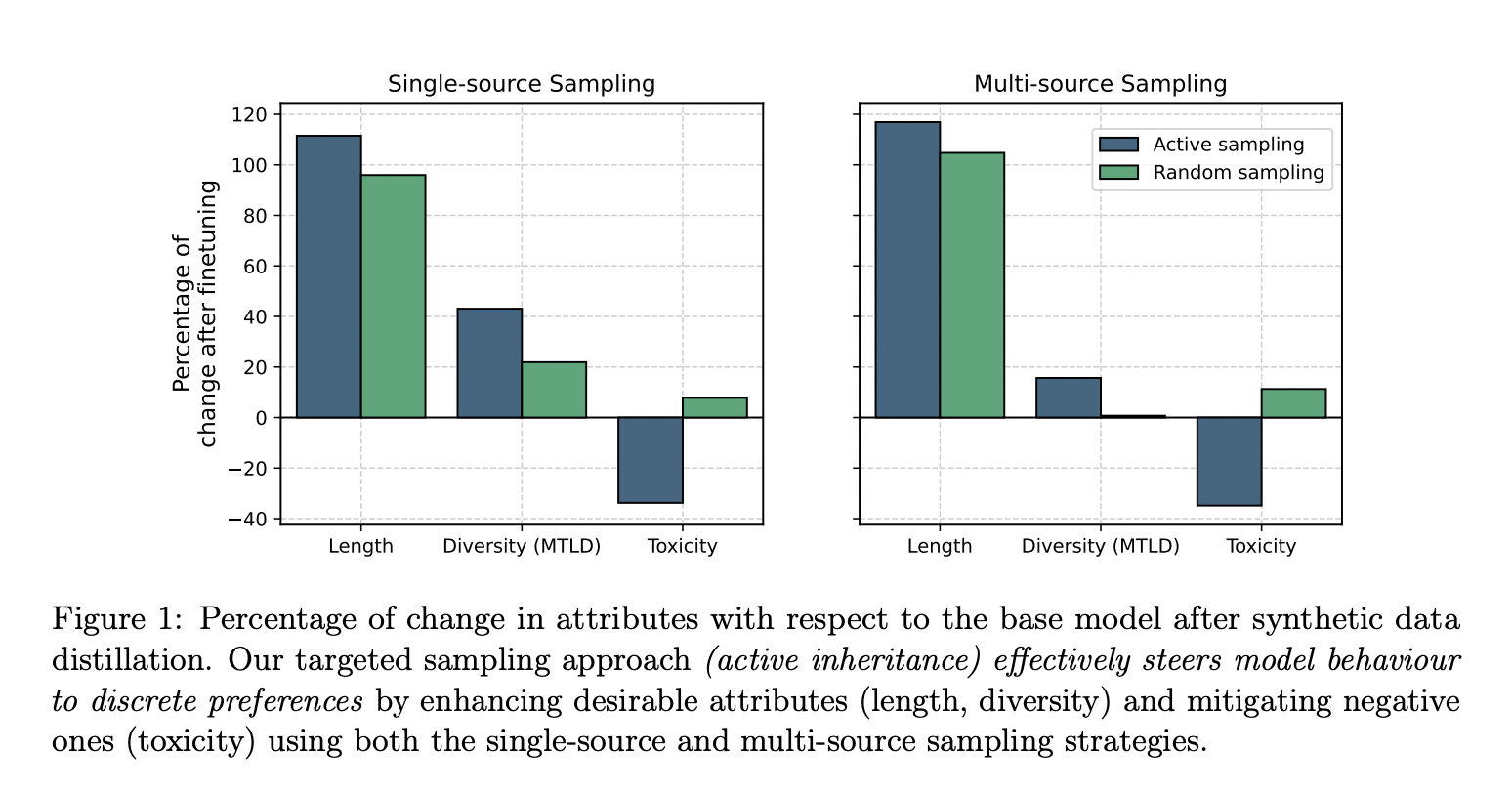
Исследователи из Cohere for AI предложили новую концепцию под названием “активное наследие”. Этот метод направлен на умышленное управление процессом синтетического создания данных в сторону конкретных недифференцируемых целей, таких как высокая лексическая разнообразность и низкая токсичность. Активное наследие включает в себя выбор заменителей меток на основе желаемых характеристик, генерацию нескольких образцов для каждого запроса и выбор образца, который максимизирует желаемую характеристику. Этот подход, известный как целевая выборка, позволяет настраивать модели на конкретные цели, используя синтетические наборы данных, созданные для улучшения этих характеристик.
Метод активного наследия показал значительные результаты. Например, целевая выборка эффективно направляет поведение модели на желательные характеристики, что приводит к существенным улучшениям. Модели продемонстрировали улучшение длины до 116% и увеличение лингвистического разнообразия до 43%. Более того, метод снизил токсичность на 40%. Эти результаты подчеркивают потенциал активного наследия для улучшения качества и безопасности языковых моделей. Фокусировка на конкретные характеристики позволяет исследователям гарантировать, что модели обладают желательными чертами, минимизируя негативные.
Исследование также рассмотрело, как пассивное наследие, при котором модели унаследуют свойства от синтетических данных без явного руководства, влияет на производительность модели. Исследование подчеркнуло, что модели чувствительны к свойствам искусственных данных, на которых они обучаются, даже когда запросы данных кажутся нейтральными. Эта чувствительность вызывает опасения относительно возможности внесения непреднамеренных искажений и характеристик в модели. Полученные результаты подчеркивают важность тщательной кураторской работы с синтетическими данными для избежания нежелательных результатов.
Заключение
Исследование подчеркивает значительное влияние синтетических данных на характеристики больших языковых моделей. Представив концепцию активного наследия, исследователи из Cohere предоставили прочную основу для управления синтетическим созданием данных в сторону желательных характеристик. Этот метод улучшает конкретные характеристики, такие как лексическая разнообразность и сниженная токсичность, обеспечивая эффективность и безопасность моделей, обученных с использованием синтетических данных. Результаты исследования демонстрируют, что возможно успешно и эффективно внедрять желательные характеристики в генерацию моделей с минимальными усилиями. Активное наследие представляет собой многообещающий подход к оптимизации моделей машинного обучения, предлагая путь к более сложным и надежным системам искусственного интеллекта.
“`

























