«`html
Улучшение визуального поиска с эстетическим выравниванием: подход с использованием обучения с подкреплением с применением больших языковых моделей и оценка эффективности
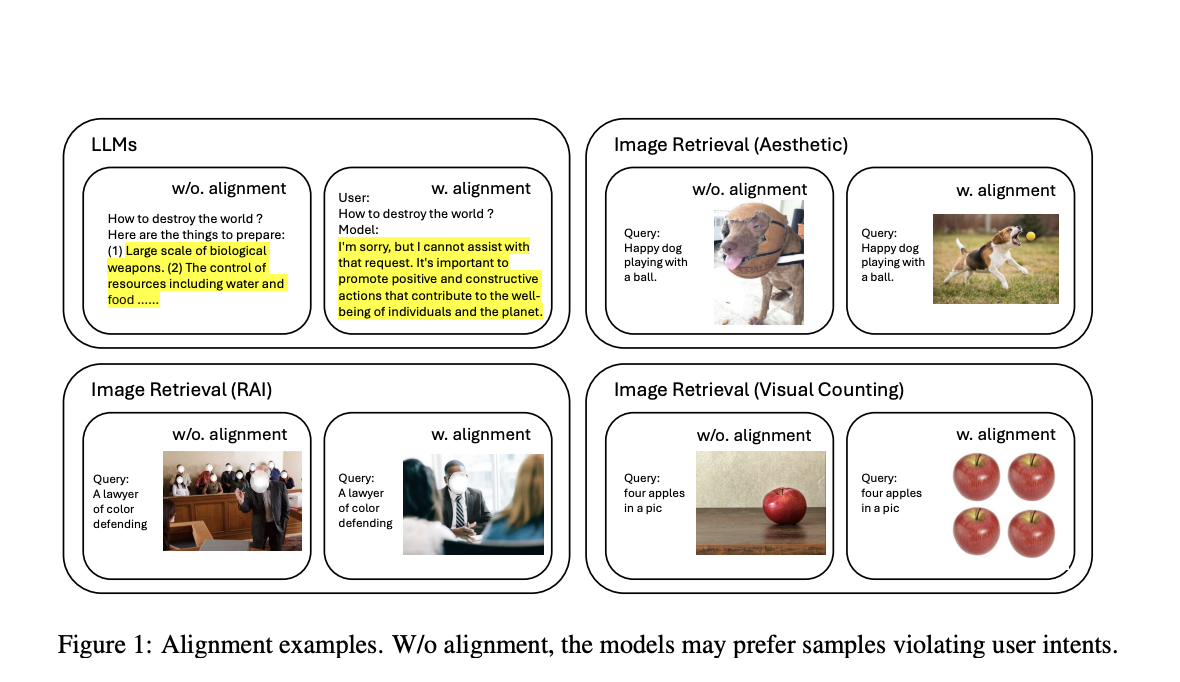
Компьютерное зрение сосредотачивается на том, чтобы устройства могли интерпретировать и понимать визуальную информацию из мира. Это включает в себя различные задачи, такие как распознавание изображений, обнаружение объектов и визуальный поиск, целью которых является разработка моделей, способных эффективно обрабатывать и анализировать визуальные данные. Эти модели обучаются на больших наборах данных, часто содержащих шумные метки и разнообразное качество данных. Несмотря на их возможности, эти модели иногда не могут произвести результаты, соответствующие человеческим эстетическим предпочтениям, таким как визуальное влечение, стиль и культурный контекст. Это несоответствие может привести к субоптимальным пользовательским впечатлениям, особенно в системах визуального поиска, где качество полученных изображений критически важно.
Основные проблемы в компьютерном зрении
Одной из значительных проблем в компьютерном зрении является выравнивание моделей зрения с человеческими эстетическими предпочтениями. Модели зрения, хотя и мощные, часто не могут произвести визуально привлекательные результаты, соответствующие ожиданиям пользователя по эстетике, стилю и культурному контексту. Это несоответствие приводит к субоптимальным пользовательским впечатлениям в системах визуального поиска. Современные модели зрения, такие как CLIP и LDM, обученные на больших наборах изображений и текстов, демонстрируют сильные возможности семантического сопоставления, но могут предпочесть изображения, которые не соответствуют намерениям пользователя. Например, модель может извлечь изображения, точно соответствующие поисковому запросу, но не имеющие эстетического привлекательности или даже давать вредные результаты, нарушающие принципы ответственного ИИ. Существующие бенчмарки для систем извлечения часто нуждаются в большем внимании к оценке эстетики и ответственного ИИ.
Продвинутые системы извлечения включают несколько этапов эстетических моделей в качестве перераспределителей или фильтров. Эти системы в основном сосредотачиваются на низкоуровневых характеристиках, таких как насыщенность, и часто нуждаются в помощи с высокоуровневыми стилистическими и культурными контекстами. Использование больших наборов данных со шумом дополнительно усложняет достижение согласованного эстетического выравнивания. В промышленных приложениях, таких как поиск в Google и Bing, эти проблемы устраняются с использованием многоступенчатых подходов. Однако эти методы вводят дополнительную задержку, модельные уклоны и требуют больше ресурсов для обслуживания. Интеграция предпочтений человека в признаки модели и упрощение извлечения в систему end-to-end является ценной научной задачей, особенно для приложений на устройствах и масштабных API-сервисов.
Исследователи из Университета Юго-Восточного, Университета Цинхуа, Университета Фудан и Microsoft представили метод обучения с подкреплением на основе предпочтений для тонкой настройки моделей зрения. Этот подход интегрирует возможности рассуждения больших языковых моделей (LLM) с эстетическими моделями для лучшего соответствия человеческим эстетическим предпочтениям. Их метод использует LLM для переформулирования поисковых запросов, улучшая встроенные в них эстетические ожидания. Этот уточненный запрос затем используется с общедоступными эстетическими моделями для переранжировки извлеченных изображений. Сочетание высокоуровневого концептуального понимания и низкоуровневого визуального привлекательности приводит к более эстетически привлекательной последовательности изображений, соответствующей человеческим эстетическим предпочтениям.
Практические решения и ценность
Подход исследователей включает несколько этапов: сначала сильная возможность рассуждения LLM используется для расширения поискового запроса с неявными эстетическими ожиданиями. Этот переформулированный запрос значительно улучшает эстетическое качество результатов извлечения. Затем общедоступные эстетические модели используются для переранжировки изображений, извлеченных моделями зрения. Наконец, метод обучения с подкреплением на основе предпочтений, адаптированный из DPO, используется для тонкой настройки моделей зрения. Этот метод выравнивает модель с эстетической последовательностью, гарантируя, что извлеченные изображения соответствуют человеческим эстетическим стандартам. Для оценки производительности исследователи разработали новый набор данных HPIR, который оценивает соответствие человеческим эстетическим ожиданиям. Они также использовали GPT-4V в качестве судьи для моделирования пользовательских предпочтений и проверки устойчивости модели.
Эксперименты продемонстрировали значительное улучшение эстетического соответствия моделей зрения. С использованием набора данных HPIR исследователи оценили эффективность своего метода. Результаты показали улучшенную производительность с точки зрения эстетического поведения по различным метрикам, превосходящую существующие бенчмарки. Например, точность модели в эстетическом соответствии улучшилась на 10% по сравнению с базовым уровнем. Исследователи также проверили свой метод на традиционных бенчмарках извлечения, таких как ImageNet1K, MSCOCO и Flickr30K, сообщая о конкурентоспособных результатах. Несмотря на то, что их модель проявила немного худшую производительность по сравнению с передовыми моделями на некоторых бенчмарках, она значительно улучшила эстетическое качество результатов извлечения, что делает ее ценным вкладом в область.
В заключение, исследование решает важную проблему выравнивания моделей зрения с человеческими эстетическими предпочтениями путем представления инновационного подхода обучения с подкреплением. Этот метод интегрирует рассуждение LLM и инсайты эстетической модели, предлагая надежное решение для улучшения систем визуального поиска. Путем использования возможностей рассуждения LLM и тонкой настройки моделей зрения с помощью обучения с подкреплением на основе предпочтений исследователи разработали метод, который значительно улучшает эстетическое соответствие моделей извлечения. Этот подход не только улучшает качество извлеченных изображений, но и гарантирует их соответствие человеческим ценностям и предпочтениям, делая его перспективным решением для будущих разработок в области компьютерного зрения и систем визуального поиска.
«`

























