Улучшение возможностей долгосрочной памяти LSTM для продвинутого языкового моделирования и не только
Несмотря на значительный вклад в области глубокого обучения, у LSTM есть ограничения, особенно в пересмотре сохраненной информации. Например, при решении проблемы поиска ближайшего соседа, где последовательность должна найти наиболее похожий вектор, LSTM сталкивается с трудностями в обновлении сохраненных значений при обнаружении более близкого соответствия позже в последовательности. Эта неспособность пересматривать решения по хранению затрудняет их производительность в задачах, требующих динамических корректировок сохраненной информации. Эти вызовы требуют постоянного развития архитектур нейронных сетей для преодоления ограничений и улучшения возможностей модели.
Решение на практике
Исследователи из ELLIS Unit, LIT AI Lab, Institute for Machine Learning, JKU Linz, Austria NXAI Lab, Linz, Austria и NXAI GmbH, Linz, Austria стремятся улучшить языковое моделирование LSTM, учитывая его ограничения. Они представляют экспоненциальные гейты и модифицируют структуры памяти для создания xLSTM, который может эффективно пересматривать сохраненные значения, вмещать больше информации и обеспечивать параллельную обработку. Интеграция этих усовершенствований в архитектуры блоков остаточных значений достигает конкурентоспособной производительности, сравнимой с передовыми трансформаторами и моделями пространства состояний. Преодоление ограничений LSTM открывает пути для масштабирования языковых моделей до уровня современных больших языковых моделей, потенциально революционизируя задачи понимания и генерации языка.
Практическая ценность
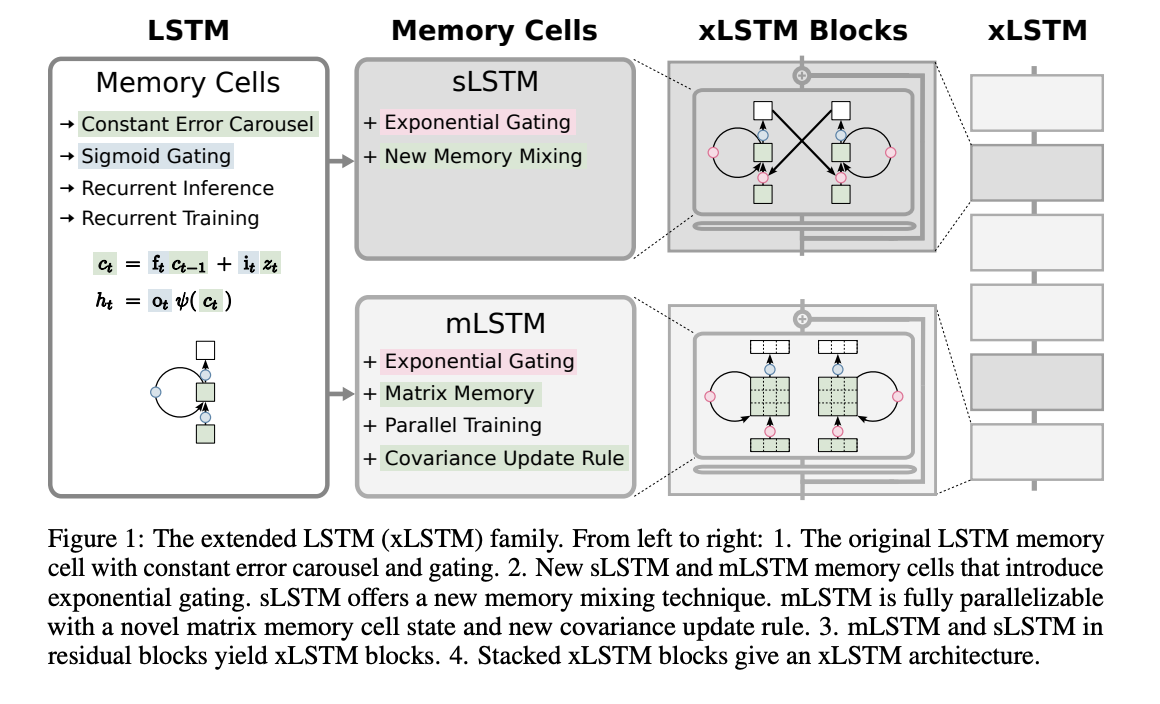
Расширенная долгосрочная память (xLSTM) представляет два варианта: sLSTM с скалярной памятью и обновлением, обладающий смешиванием памяти, и mLSTM с матричной памятью и правилом обновления ковариации, который полностью параллелизуем. Интеграция в архитектуры блоков остаточных значений дает xLSTM-блоки, которые могут нелинейно резюмировать прошлые контексты в высокомерных пространствах. Архитектуры xLSTM построены путем резидуального стекирования этих блоков, предлагая линейные вычисления и постоянную сложность памяти относительно длины последовательности. Хотя mLSTM вычислительно затратен из-за его матричной памяти, оптимизации позволяют эффективную параллельную обработку на графических процессорах.
Заключение
xLSTM сталкивается с ограничениями, включая более медленную параллелизацию по сравнению с mLSTM, медленные ядра CUDA и вычислительную сложность для матричной памяти. Однако xLSTM обещает в языковом моделировании, конкурируя с трансформаторами и моделями пространства состояний. Законы масштабирования показывают его потенциальную конкурентоспособность с большими языковыми моделями. Необходима дальнейшая оптимизация для более крупных архитектур xLSTM.

























