Итеративная оптимизация предпочтений для улучшения задач рассуждения в языковых моделях
Методы итеративной оптимизации предпочтений показали свою эффективность в настройке общих задач настройки, но они приводят к ограниченным улучшениям в задачах рассуждения. Эти методы, использующие оптимизацию предпочтений, улучшают соответствие языковой модели человеческим требованиям по сравнению с простой настройкой под наблюдением. Офлайновые техники, такие как DPO, становятся популярными из-за своей простоты и эффективности. Недавние достижения предлагают итеративное применение офлайновых процедур, таких как Итеративное DPO, Самовознаграждающие LLM и SPIN, которые создают новые отношения предпочтения для дальнейшего улучшения производительности модели. Однако оптимизация предпочтений остается неизученной в этой области, несмотря на успешное применение других итеративных методов обучения, таких как STaR и RestEM, для задач рассуждения.
Практические решения и ценность
Методы итеративного выравнивания включают как стратегии с участием человека, так и автоматизированные стратегии. В то время как некоторые полагаются на обратную связь человека для обучения с подкреплением (RLHF), другие, такие как Итеративное DPO, оптимизируют предпочтительные пары автономно, генерируя новые пары для последующих итераций с использованием обновленных моделей. SPIN, вариант Итеративного DPO, использует метки человека и генерации модели для создания предпочтительных пар, но сталкивается с ограничениями, когда производительность модели соответствует стандартам человека. Самовознаграждающие LLM также используют Итеративное DPO, причем сама модель выступает в качестве оценщика наград, принося улучшения в следовании инструкциям, но умеренные улучшения в рассуждениях. В отличие от этого, Экспертная итерация и STaR сосредотачиваются на кураторстве выборки и улучшении обучающих данных, отклоняясь от оптимизации предпочтительных пар.
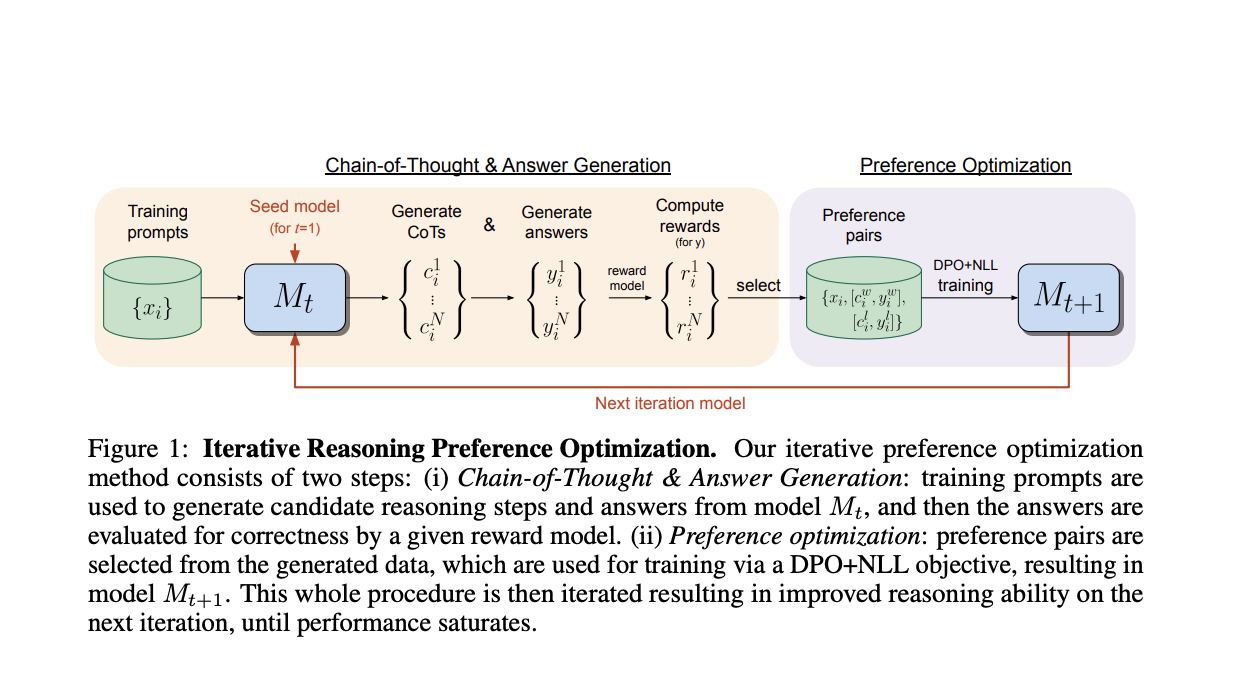
Исследователи из FAIR в Meta и Нью-Йоркского университета представляют подход, нацеленный на итеративную оптимизацию предпочтений для задач рассуждения, в частности Chain-of-Thought (CoT) рассуждения. Каждая итерация включает выбор нескольких шагов рассуждения CoT и окончательных ответов, конструирование предпочтительных пар, где победители имеют правильные ответы, а проигравшие – неправильные. Обучение включает в себя вариант DPO, включающий термин потери отрицательного логарифма правдоподобия (NLL) для победителей пар, что является важным для улучшения производительности. Итеративный процесс повторяется путем генерации новых пар и повторного обучения модели с предыдущей итерации, тем самым пошагово улучшая производительность модели.
Этот подход зависит от базовой языковой модели, обычно предварительно обученной или настроенной по инструкции, и набора данных тренировочных входов, с возможностью оценить правильность окончательного вывода. Исследования используют наборы данных с золотыми метками для тренировочных входов, получая бинарную награду от точных совпадений между метками и окончательными ответами. Метод включает два шага на каждую итерацию: (i) Генерация цепочки рассуждений и ответов и (ii) Оптимизация предпочтений.
В экспериментах исследователи были обучены использовать модифицированную потерю DPO с добавленным термином отрицательного логарифма правдоподобия, который был признан важным. Профессиональные навыки рассуждения улучшаются на протяжении последовательных итераций этого метода. Используя только примеры из набора данных для обучения, подход приводит к увеличению точности для Llama-2-70B-Chat, повышаясь с 55,6% до 81,6% на GSM8K (и 88,7% при большинстве голосов из 32 образцов), с 12,5% до 20,8% на MATH и с 77,8% до 86,7% на ARC-Challenge. Эти улучшения превосходят производительность других моделей на основе Llama-2, которые не используют дополнительные наборы данных.
Заключение
Данное исследование представляет итеративный алгоритм обучения, нацеленный на улучшение производительности задач рассуждения на основе цепочки мыслей для языковых моделей. Каждая итерация генерирует несколько ответов и создает предпочтительные пары на основе правильности окончательного ответа, используя модифицированную потерю DPO с дополнительным термином NLL для обучения. Метод не требует участия человека или дополнительных обучающих данных, сохраняя простоту и эффективность. Экспериментальные результаты показывают существенные улучшения на GMS8K, MATH и ARC-Challenge по сравнению с различными базовыми моделями, использующими ту же базовую модель и обучающие данные. Эти результаты подчеркивают эффективность итеративного подхода к обучению для улучшения рассуждения языковых моделей.









