Проблемы генерации визуального текста
Создание точного и эстетически привлекательного визуального текста в моделях генерации изображений является серьезной задачей. Хотя модели на основе диффузии добились успехов в создании разнообразных и качественных изображений, они часто не могут генерировать четкий и правильно расположенный визуальный текст. Основные проблемы включают опечатки, пропущенные слова и неправильное выравнивание текста, особенно при генерации текстов на неродных языках, таких как китайский. Эти ограничения ограничивают применение таких моделей в реальных случаях, таких как производство цифровых медиа и реклама, где точная генерация визуального текста имеет решающее значение.
Текущие методы и их ограничения
Современные методы генерации визуального текста обычно встраивают текст непосредственно в скрытое пространство модели или накладывают позиционные ограничения во время генерации изображений. Однако эти подходы имеют свои ограничения. Byte Pair Encoding (BPE), часто используемый для токенизации в этих моделях, разбивает слова на подслова, что усложняет генерацию связного и четкого текста. Кроме того, механизмы перекрестного внимания в этих моделях не полностью оптимизированы, что приводит к слабому выравниванию между сгенерированным визуальным текстом и входными токенами.
Инновации в генерации визуального текста
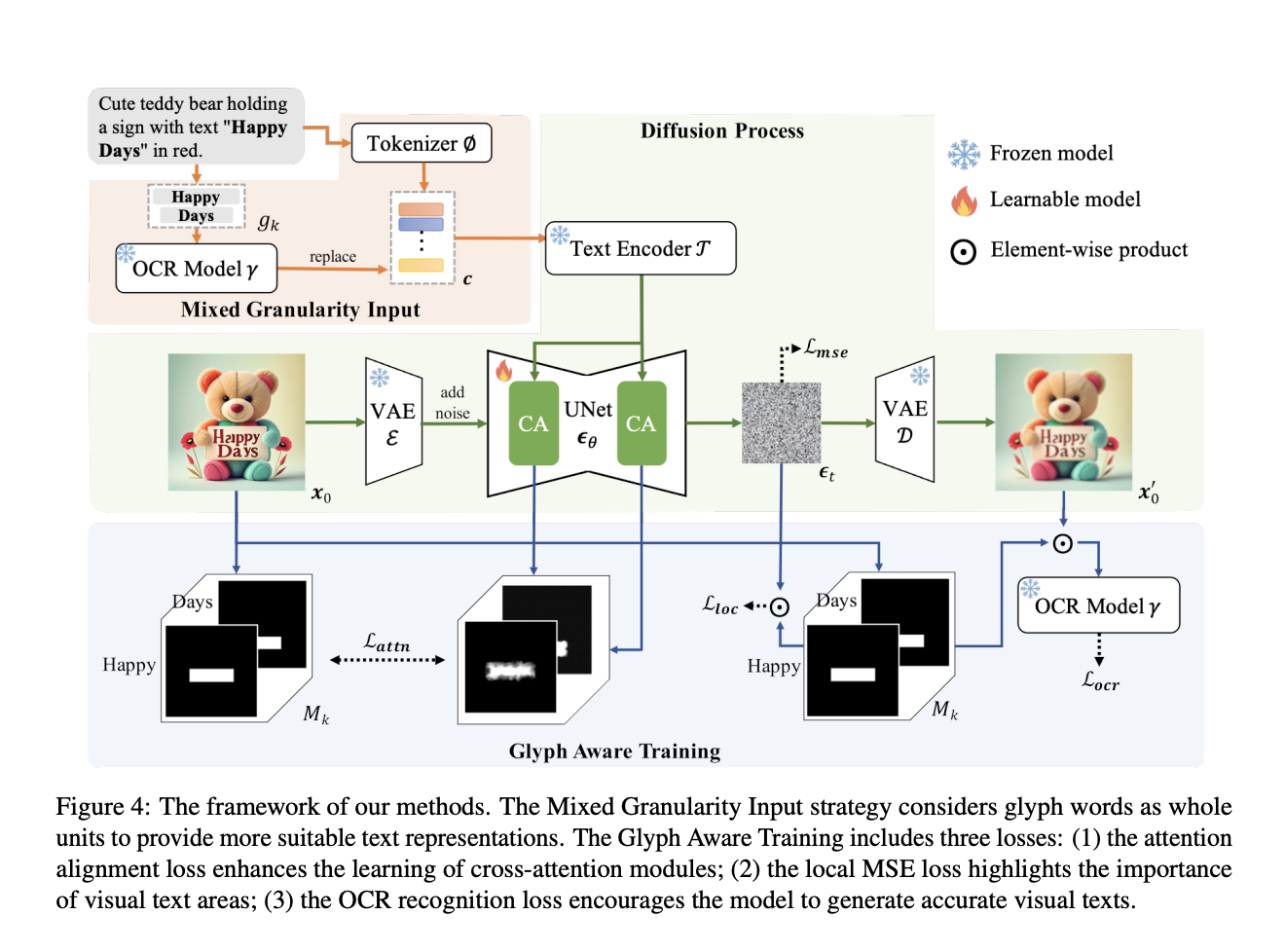
Исследователи из Университета Сямэнь, Baidu Inc. и Шанхайской лаборатории искусственного интеллекта представили две ключевые инновации: контроль за гранулярностью входных данных и обучение с учетом глифов. Стратегия смешанной гранулярности входных данных представляет собой целые слова вместо подслов, что позволяет обойти проблемы, вызванные токенизацией BPE, и обеспечивает более связную генерацию текста. Также была введена новая схема обучения, включающая три ключевые потери, что улучшает как визуальные, так и семантические аспекты генерации текста.
Преимущества нового подхода
Данный подход использует фреймворк латентной диффузии с тремя основными компонентами: вариационным автоэнкодером (VAE) для кодирования и декодирования изображений, UNet для управления процессом диффузии и текстовым энкодером для обработки входных подсказок. Модель обучается на наборе данных, состоящем из 240,000 английских и 50,000 китайских образцов, что обеспечивает высокое качество изображений с четким и связным визуальным текстом.
Результаты и достижения
Этот метод демонстрирует значительные улучшения как в точности генерации текста, так и в визуальной привлекательности. Точность, полнота и F1-оценки для генерации текста на английском и китайском языках значительно превышают показатели существующих методов. Новый подход к обучению с учетом глифов позволяет поддерживать мультиязычность, эффективно обрабатывая генерацию текста на китайском языке.
Заключение
Разработанный метод продвигает область генерации визуального текста, решая критические задачи, связанные с токенизацией и механизмами перекрестного внимания. Введение контроля за гранулярностью входных данных и обучения с учетом глифов позволяет генерировать точный и эстетически привлекательный текст как на английском, так и на китайском языках. Эти инновации расширяют практическое применение моделей генерации текста в изображениях, особенно в областях, требующих точной многозначной генерации текста.
Как использовать ИИ для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), используйте эти инновации. Проанализируйте, как ИИ может изменить вашу работу, и определите, где возможно применение автоматизации. Подберите подходящее решение и внедряйте ИИ постепенно, начиная с малого проекта. Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистента в продажах
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru. Этот ИИ ассистент помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.

























