Преимущества модели ReMamba в обработке длинных последовательностей текста
В области обработки естественного языка (NLP) эффективная обработка длинных текстовых последовательностей представляет собой критическую задачу. Традиционные модели трансформера, широко используемые в больших языковых моделях (LLM), отлично справляются с многими задачами, но требуют улучшений при обработке длинных входов. Ограничения этих моделей связаны в первую очередь с квадратичной вычислительной сложностью и линейными затратами памяти, связанными с механизмом внимания, используемым в трансформерах. По мере увеличения длины текста требования к этим моделям становятся запретительно высокими, что затрудняет поддержание точности и эффективности. В связи с этим разрабатываются альтернативные архитектуры, направленные на более эффективную обработку длинных последовательностей при сохранении вычислительной эффективности.
Проблемы обработки длинных последовательностей в NLP
Одной из основных проблем моделирования длинных последовательностей в NLP является деградация информации по мере увеличения длины текста. Архитектуры рекуррентных нейронных сетей (RNN), часто используемые в качестве основы для этих моделей, особенно подвержены этой проблеме. По мере увеличения длины входных последовательностей эти модели нуждаются в помощи для сохранения важной информации из более ранних частей текста, что приводит к снижению производительности. Эта деградация является значительным препятствием для разработки более продвинутых LLM, способных обрабатывать расширенные текстовые входы без потери контекста или точности.
Решения и практические применения
Множество методов были предложены для решения этих проблем, включая гибридные архитектуры, объединяющие RNN с механизмами внимания трансформера. Эти гибриды нацелены на использование преимуществ обеих подходов: RNN обеспечивает эффективную обработку последовательностей, а механизмы внимания помогают сохранить критическую информацию в длинных последовательностях. Однако такие решения часто имеют увеличенные вычислительные и памятные затраты, что уменьшает эффективность. Некоторые методы сосредотачиваются на расширении возможностей моделей путем улучшения их способности экстраполяции длины без необходимости дополнительного обучения. Однако эти подходы обычно приводят только к умеренному увеличению производительности и лишь частично решают основную проблему деградации информации.
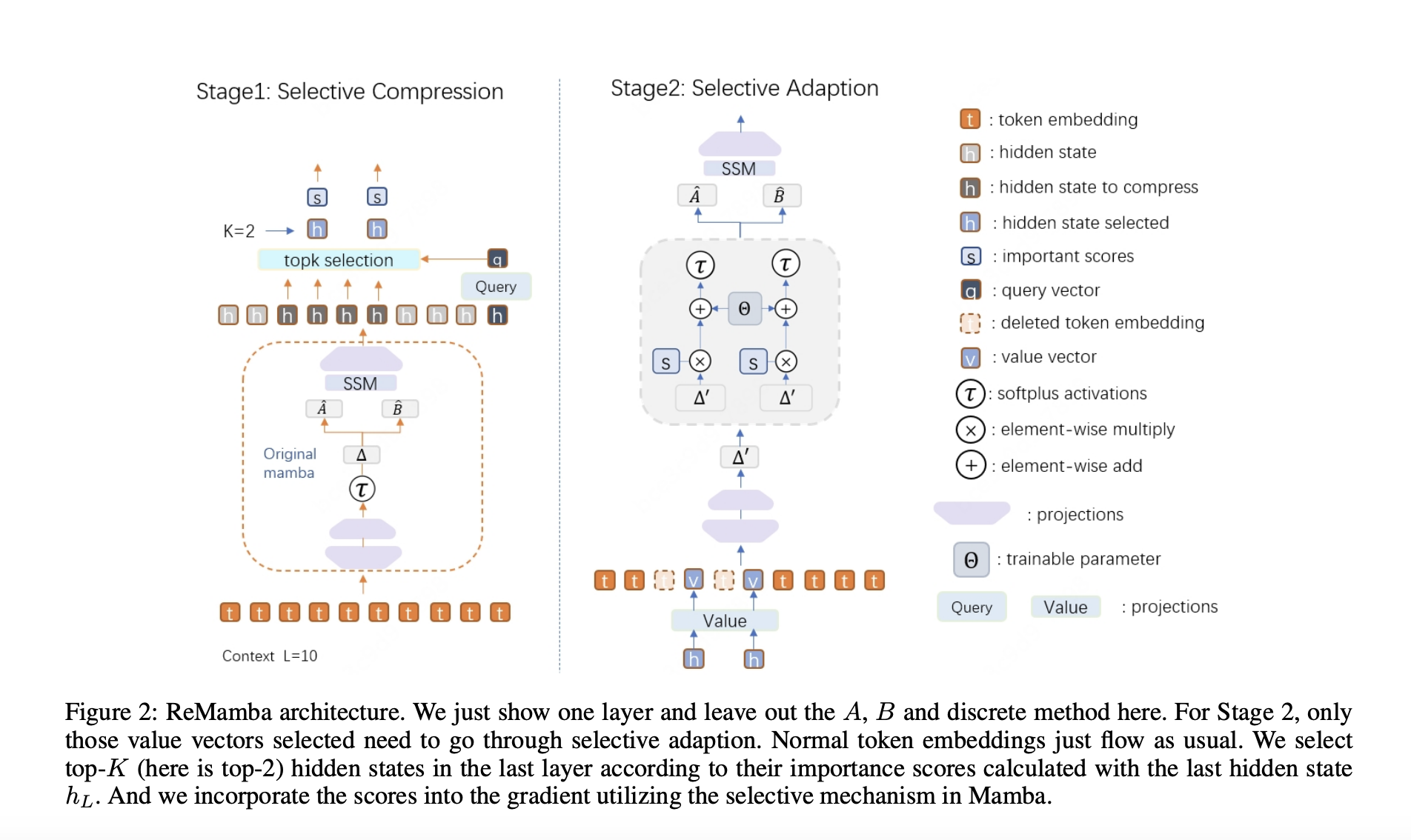
Исследователи из Пекинского университета, Национальной ключевой лаборатории общего искусственного интеллекта, 4BIGAI и Meituan представили новую архитектуру под названием ReMamba, разработанную для улучшения возможностей обработки длинного контекста существующей архитектуры Mamba. В то время как Mamba эффективно выполняет задачи с коротким контекстом, он показывает значительное снижение производительности при работе с более длинными последовательностями. Цель исследователей заключалась в преодолении этого ограничения путем внедрения методики селективной компрессии в рамках двухэтапного процесса повторной передачи. Такой подход позволяет ReMamba сохранять критическую информацию из длинных последовательностей, не увеличивая значительно вычислительной нагрузки, тем самым улучшая общую производительность модели.
ReMamba работает с помощью тщательно разработанного двухэтапного процесса. На первом этапе модель использует три сети прямого распространения для оценки значимости скрытых состояний из последнего слоя модели Mamba. Затем эти скрытые состояния селективно сжимаются на основе их оценочных баллов, которые рассчитываются с использованием меры косинусного сходства. Сжатие уменьшает необходимые обновления состояний, эффективно уплотняя информацию и минимизируя деградацию. На втором этапе ReMamba интегрирует эти сжатые скрытые состояния в контекст ввода с помощью механизма селективной адаптации, позволяя модели поддерживать более последовательное понимание всей текстовой последовательности. Этот метод влечет за собой лишь минимальные дополнительные вычислительные затраты, что делает его практичным решением для улучшения производительности при работе с длинным контекстом.
Эффективность ReMamba была продемонстрирована через обширные эксперименты на установленных бенчмарках. На бенчмарке LongBench ReMamba превзошел базовую модель Mamba на 3,2 пункта; на бенчмарке L-Eval он достиг улучшения в 1,6 пункта. Эти результаты подчеркивают способность модели приблизиться к уровню производительности моделей на основе трансформеров, которые обычно более мощны в обработке длинных контекстов. Исследователи также проверили передаточную способность своего подхода, применив тот же метод к модели Mamba2, что привело к улучшению на бенчмарке LongBench на 1,6 пункта, дополнительно подтверждая надежность их решения.
Производительность ReMamba особенно заметна в его способности обрабатывать различные длины ввода. Модель последовательно превосходила базовую модель Mamba при различных длинах контекста, увеличивая эффективную длину контекста до 6000 токенов по сравнению с 4000 токенами для настроенной базовой модели Mamba. Это демонстрирует улучшенную способность ReMamba управлять более длинными последовательностями без ущерба для точности или эффективности. Кроме того, модель сохраняла значительное преимущество в скорости перед традиционными моделями трансформеров, работая сравнимо со стандартной скоростью оригинальной модели Mamba при обработке более длинных входов.
В заключение, модель ReMamba решает критическую задачу моделирования длинных последовательностей с помощью инновационного подхода к сжатию и селективной адаптации. Путем более эффективного сохранения и обработки критической информации ReMamba сокращает разрыв в производительности между Mamba и моделями на основе трансформеров, сохраняя при этом вычислительную эффективность. Это исследование не только предлагает практичное решение для ограничений существующих моделей, но также заложено основу для будущих разработок в области обработки длинного контекста естественного языка. Результаты бенчмарков LongBench и L-Eval подчеркивают потенциал ReMamba для улучшения возможностей LLM.

























