Практические решения в области MLLMs с интеграцией мультиуровневых визуальных данных
Проблематика
MLLMs представляют собой передовое направление в искусственном интеллекте, объединяющее визуальную и текстовую информацию для понимания и генерации ответов. Эти модели значительно расширили свои возможности, перейдя от обработки и понимания только текстовых данных к умению также обрабатывать и анализировать визуальную информацию.
Практические решения
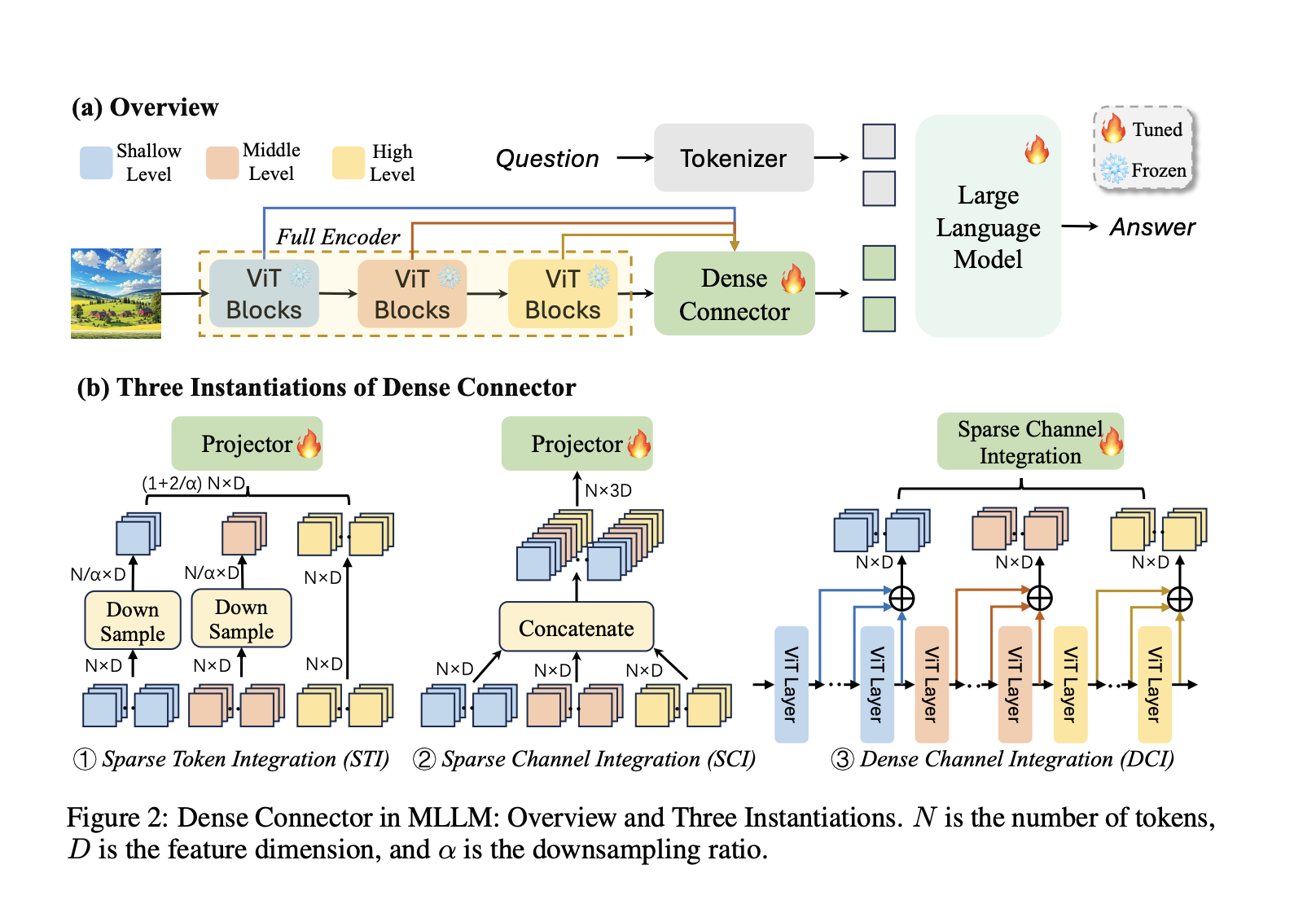
Текущие исследования включают различные методы и модели для MLLMs, такие как CLIP, SigLIP и Q-former, которые соединяют визуальные и языковые модели с использованием предварительно обученных визуальных кодировщиков. Методы, такие как LLaVA и Mini-Gemini, используют высокоразрешенные визуальные представления и настройку инструкций для повышения производительности. Методы, такие как Sparse Token Integration и Dense Channel Integration, эффективно используют многоканальные визуальные признаки для улучшения устойчивости и масштабируемости MLLMs по разнообразным наборам данных и архитектурам.
Значение
Ввод в области AI и интеллектуальные системы предлагает инновационные методы, предназначенные для эффективной интеграции мультиуровневых визуальных данных в MLLMs. Эти методы существенно повышают качество визуальной информации, поступающей в LLM, не повышая вычислительной сложности. Эксперименты демонстрируют значительное улучшение производительности MLLM на различных наборах изображений и видео, подчеркивая их потенциал для продвижения мультимодального понимания в AI.

























