DeepStack: улучшение мультимодельных моделей с использованием слоев интеграции визуальных токенов для высокопроизводительных изображений
Большинство мультимодельных языковых моделей (LMMs) интегрируют видение и язык, преобразуя изображения в визуальные токены, которые подаются в виде последовательностей в LLMs. Этот метод эффективен для мультимодального понимания, но значительно увеличивает требования к памяти и вычислениям, особенно при использовании фотографий или видео высокого разрешения. Различные техники, такие как пространственная группировка и сжатие токенов, направлены на снижение их количества, но часто жертвуют детальной визуальной информацией. Несмотря на эти усилия, фундаментальный подход остается прежним: визуальные токены преобразуются в одномерную последовательность и подаются на вход LLMs, что неизбежно увеличивает вычислительные затраты.
Практические решения и ценность
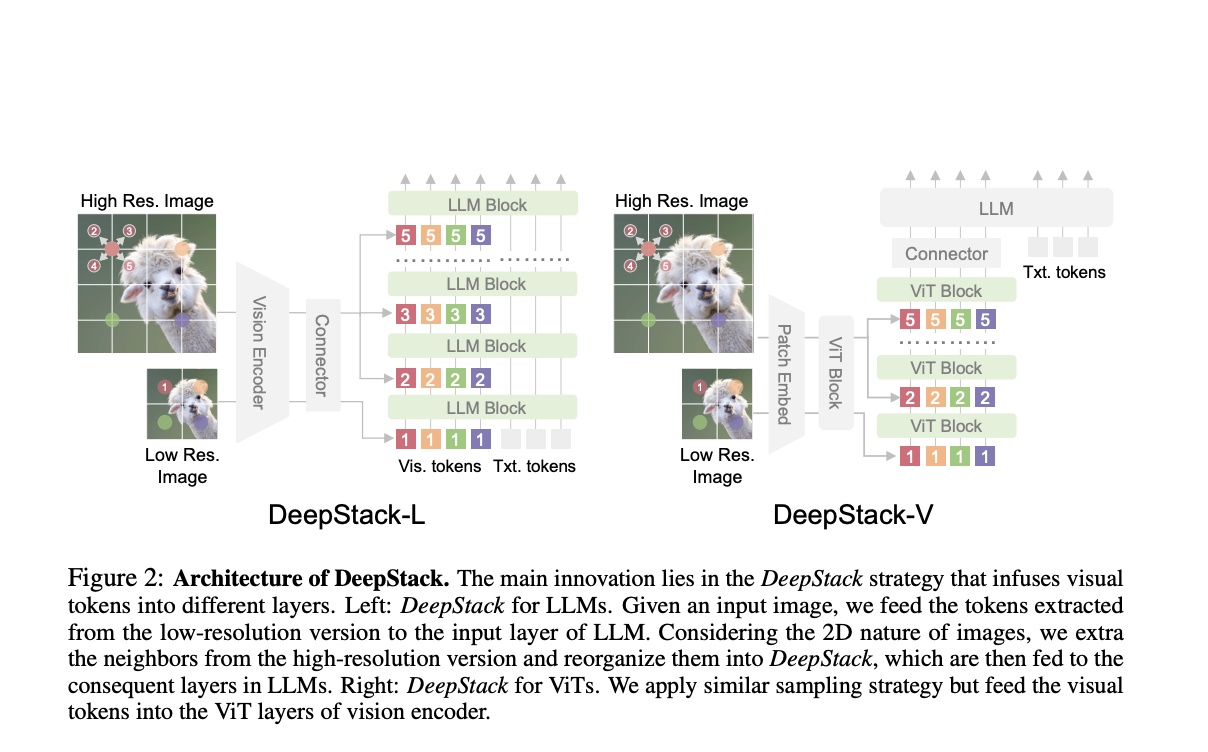
Исследователи из Университета Фудан и Microsoft разработали «DeepStack», новую архитектуру для LMMs. Вместо подачи длинной последовательности визуальных токенов на первый слой языковой модели, DeepStack распределяет эти токены по нескольким слоям, выравнивая каждую группу с соответствующим слоем. Этот подход снизу вверх улучшает способность модели обрабатывать сложные визуальные входы без увеличения вычислительных затрат. После тестирования моделей LLaVA-1.5 и LLaVA-Next DeepStack показывает значительный прирост производительности по различным показателям, особенно в задачах с высоким разрешением, и способен эффективно обрабатывать больше токенов, чем традиционные методы.
Недавние достижения в LLMs, такие как BERT, T5 и GPT, революционизировали обработку естественного языка (NLP) с использованием трансформеров и стратегий предварительного обучения и последующей настройки. Эти модели отлично справляются с различными задачами, от генерации текста до ответов на вопросы. Параллельно LMMs, такие как CLIP и Flamingo, эффективно интегрируют видение и язык, выравнивая их в общем семантическом пространстве. Однако обработка изображений высокого разрешения и сложных визуальных входов по-прежнему вызывает трудности из-за высоких вычислительных затрат. Новый подход «DeepStack» решает эту проблему, распределяя визуальные токены по нескольким слоям LLMs или Vision Transformers (ViTs), улучшая производительность и снижая нагрузку.
DeepStack улучшает LMMs, используя двухпоточный подход для интеграции детализированных визуальных деталей без увеличения длины контекста. Он разделяет обработку изображений на глобальный поток для общей информации и высокоразрешенный поток, который добавляет детальные особенности изображения по слоям LLM. Токены высокого разрешения увеличиваются и расширяются, затем подаются на различные слои LLM. Эта стратегия значительно улучшает способность модели эффективно обрабатывать сложные визуальные входы. В отличие от традиционных методов, которые конкатенируют визуальные токены, DeepStack интегрирует их по слоям, поддерживая эффективность и улучшая визуальные возможности модели.
Эксперименты с DeepStack демонстрируют его эффективность в улучшении мультимодельных языковых моделей путем интеграции визуальных токенов высокого разрешения. Используя двухэтапный процесс обучения, он использует кодировщик изображений CLIP для мозаичного объединения высокоразрешенных фрагментов изображения в полные характеристики изображения. Во время предварительного обучения модель использует 558 тыс. образцов из LAION и других наборов данных, а при настройке включает 748 тыс. образцов, адаптируя конвейер LLaVA. DeepStack последовательно превосходит базовые показатели, такие как LLaVA, по различным VQA и мультимодальным показателям, доказывая его способность эффективно обрабатывать детальную визуальную информацию. Он преуспевает в задачах, связанных с текстом, и видео-вопросами и ответами, подтверждая, что раннее и стратегическое вставление визуальных токенов значительно улучшает производительность модели без дополнительных вычислительных затрат.
В заключение, DeepStack представляет инновационный подход к улучшению LMMs путем стекирования визуальных токенов по нескольким слоям модели, а не подачи их все в первый слой. Этот метод снижает требования к вычислительным ресурсам и памяти, значительно улучшая производительность в задачах с высоким разрешением. Распределение визуальных токенов по различным слоям трансформера позволяет более эффективно взаимодействовать между этими токенами по слоям. Это приводит к существенным улучшениям, превосходя традиционные модели, такие как LLaVA, по различным показателям. Техника особенно полезна в задачах, требующих детального визуального понимания, открывая путь к более эффективным и мощным мультимодельным моделям.
Используйте DeepStack для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте DeepStack: Enhancing Multimodal Models with Layered Visual Token Integration for Superior High-Resolution Performance.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























