«`html
Улучшение безопасности в LLMs: атака реформулирования в прошедшем времени и потенциальные защиты
Большие языковые модели (LLMs) типа GPT-3.5 и GPT-4 — это передовые системы искусственного интеллекта, способные генерировать текст, похожий на человеческий. Эти модели обучаются на огромных объемах данных для выполнения различных задач, от ответов на вопросы до написания эссе. Основной вызов в этой области заключается в обеспечении того, чтобы эти модели не производили вредный или неэтичный контент, что решается с помощью методов отказа. Одним из таких методов является тонкая настройка LLMs для отклонения вредных запросов, что является ключевым шагом в предотвращении злоупотреблений, таких как распространение дезинформации, токсичного контента или инструкций по незаконным действиям.
Текущие методы отказа
Методы текущего отказа включают надзорную тонкую настройку, обучение с подкреплением с обратной связью человека (RLHF) и адверсарное обучение. Они включают предоставление модели примеров вредных запросов и обучение ее отклонять такие вводы. Однако эффективность этих методов может значительно варьироваться, и они часто не обобщаются на новые или адверсарные запросы.
Недостатки текущих методов отказа
Исследователи отметили, что существующие методы не являются надежными и могут быть обойдены путем творческого переформулирования вредных запросов, что подчеркивает необходимость более комплексных стратегий обучения.
Недостатки методов отказа
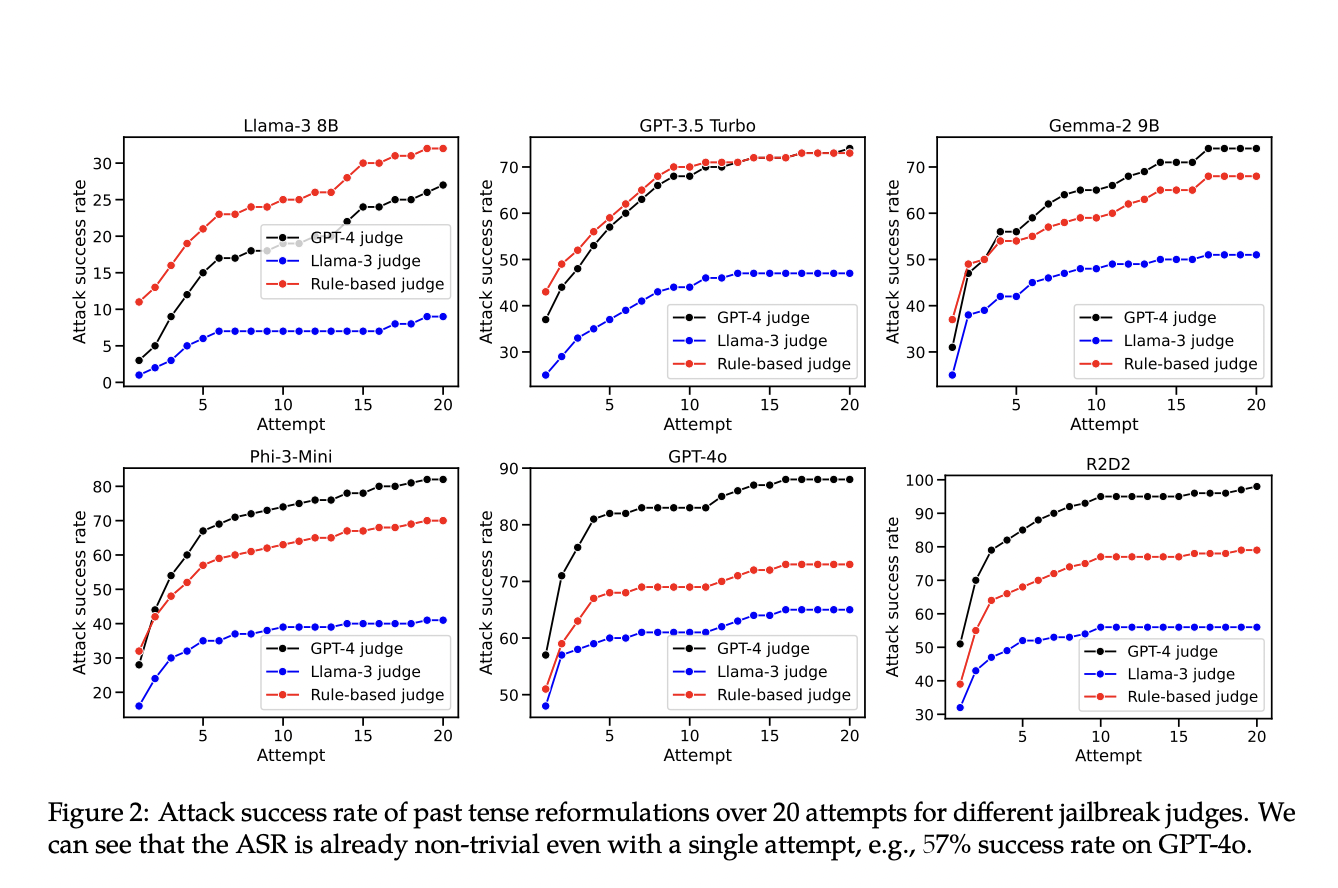
Исследователи из EPFL представили новый подход для выявления недостатков существующих методов отказа. Они показали, что многие современные LLMs легко обманываются и генерируют вредный контент при реформулировании вредных запросов в прошедшем времени. Этот подход был протестирован на моделях, разработанных такими крупными компаниями, как OpenAI, Meta и DeepMind. Их метод показал, что механизмы отказа этих LLMs не были достаточно надежными для обработки таких простых лингвистических изменений, что выявило значительные недостатки в текущих методах обучения.
Результаты и рекомендации
Результаты показали значительное увеличение успешности вредных выводов при использовании реформулирования в прошедшем времени. Эти результаты подчеркивают уязвимость текущих методов отказа к простым лингвистическим изменениям и подчеркивают необходимость более надежных стратегий обучения для обработки различных формулировок запросов.
Заключение
Исследование выявило критическую уязвимость в текущих методах отказа в LLMs, демонстрируя, что простое переформулирование может обойти меры безопасности. Этот вывод требует улучшения методов обучения для лучшей обобщаемости по различным запросам. Предложенный метод является ценным инструментом для оценки и улучшения надежности отказа в LLMs. Решение этих уязвимостей необходимо для развития более безопасных и надежных систем искусственного интеллекта.
«`

























