Улучшение обучения с подкреплением от обратной связи человека с помощью моделей вознаграждения, генерируемых критикой
Языковые модели приобрели значительное значение в обучении с подкреплением от обратной связи человека (RLHF), но текущие подходы к моделированию вознаграждения сталкиваются с вызовами в точном улавливании человеческих предпочтений. Традиционные модели вознаграждения, тренируемые как простые классификаторы, испытывают трудности в явном рассуждении о качестве ответа, что снижает их эффективность в руководстве поведением языковых моделей. Основная проблема заключается в их неспособности генерировать цепочки рассуждений, принуждая все оценки происходить неявно в одном прямом проходе. Это ограничение затрудняет возможность модели оценить тонкие нюансы человеческих предпочтений.
Практические решения:
Ранжирующие модели, такие как Bradley-Terry и Plackett-Luce, позволяют учесть предпочтения, но сталкиваются с нелогичными предпочтениями. Некоторые исследования напрямую моделируют вероятность предпочтения одного ответа перед другим, в то время как другие сосредотачиваются на моделировании вознаграждений по нескольким целям.
Значимые результаты:
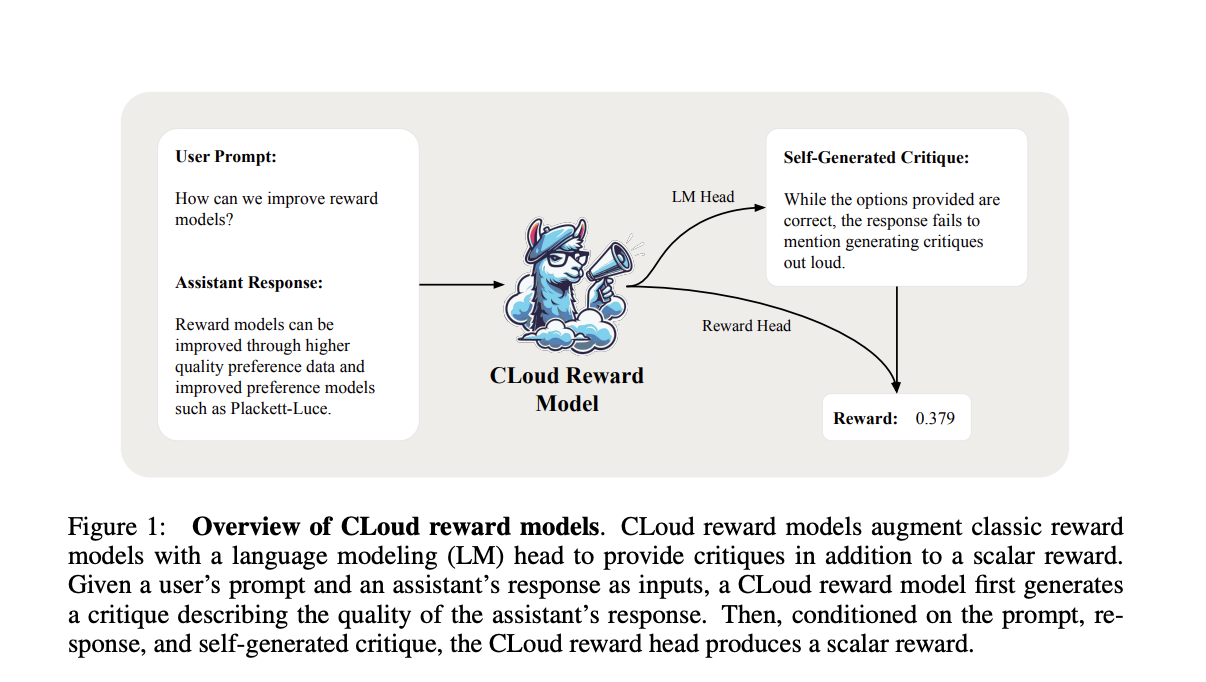
Исследователи от Databricks, MIT и Университета Калифорнии, Сан-Диего представляют модели вознаграждения Critique-out-Loud (CLoud), которые представляют уникальный подход к улучшению производительности языковых моделей в обучении с подкреплением от обратной связи человека. Эти модели генерируют подробную критику о том, насколько ответ помощника отвечает на запрос пользователя, прежде чем производят скалярное вознаграждение за качество ответа. Такой подход объединяет преимущества классических моделей вознаграждения и метода LLM-as-a-Judge.

























