«`html
Прорыв в понимании визуально-языковой информации: самоусовершенствование и интеграция специализированных знаний VILA 2
В области языковых моделей произошел значительный прогресс, стимулированный трансформаторами и усилиями по масштабированию. OpenAI GPT-серии продемонстрировали мощь увеличения параметров и использование качественных данных. Инновации, такие как Transformer-XL, расширили контекстные окна, в то время как модели, такие как Mistral, Falcon, Yi, DeepSeek, DBRX и Gemini, продвинули возможности еще дальше.
Визуально-языковые модели (VLM) также быстро развиваются. CLIP первоначально создал общие пространства для визуально-языковых признаков через контрастное обучение. BLIP и BLIP-2 улучшили это, выравнив предварительно обученные кодировщики с большими языковыми моделями. LLaVA и InstructBLIP показали сильную обобщенность по различным задачам. Kosmos-2 и PaLI-X масштабировали предварительное обучение данных с использованием псевдо-размеченных ограничивающих рамок, связывая улучшенное восприятие с лучшим высокоуровневым мышлением.
Практические решения и ценность
Недавние достижения в области визуально-языковых моделей (VLM) сосредоточены на выравнивании визуальных кодировщиков с большими языковыми моделями (LLM) для улучшения возможностей в различных визуальных задачах. Хотя прогресс достигнут в методах обучения и архитектурах, наборы данных часто остаются упрощенными. Для решения этой проблемы исследователи исследуют аугментацию данных на основе VLM в качестве альтернативы трудоемким наборам данных, созданным людьми. Статья представляет новый режим обучения, включающий этапы самоаугментации и специализированной аугментации, итеративно улучшая предварительные данные для создания более сильных моделей.
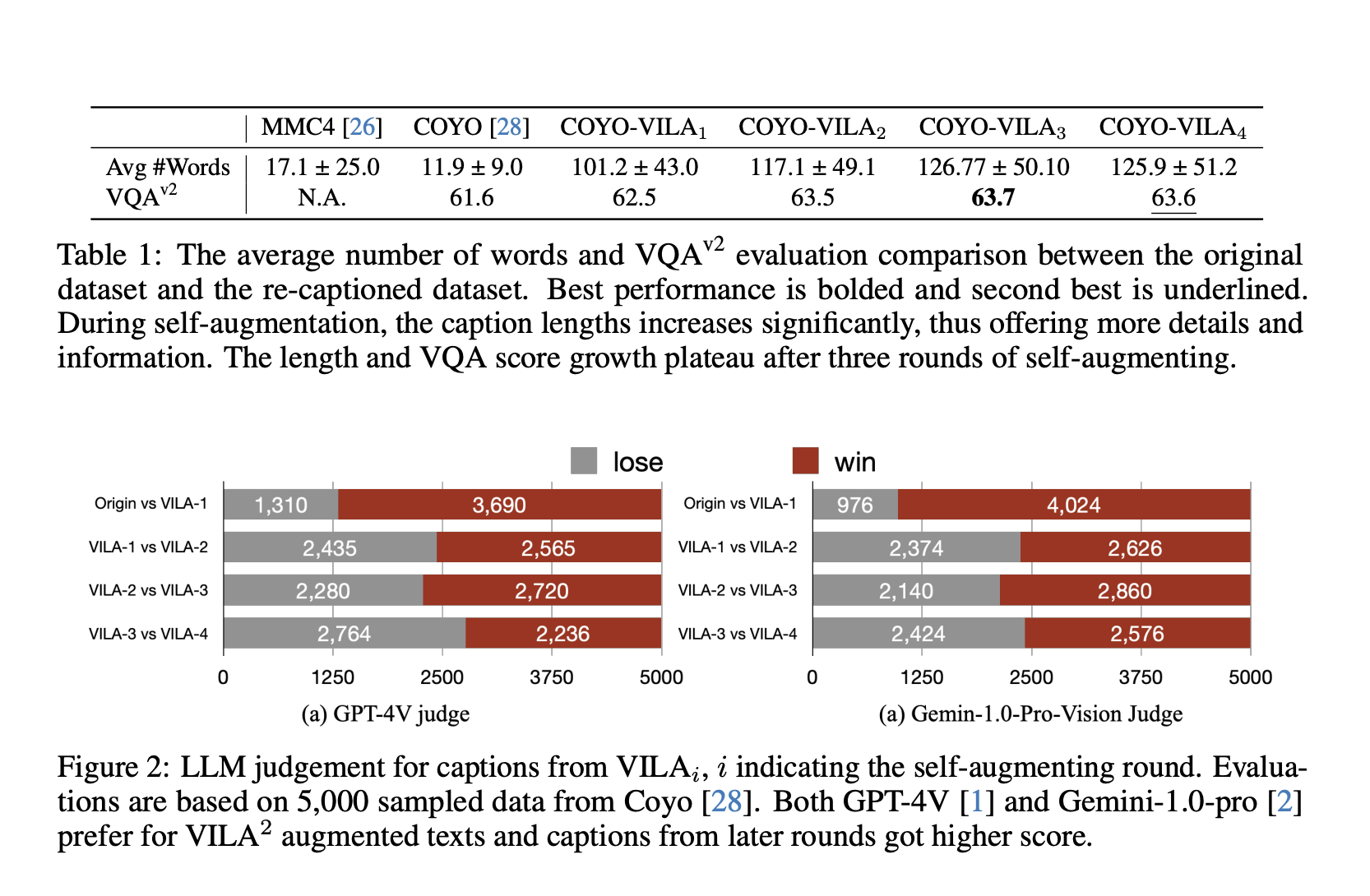
Исследование сосредоточено на авторегрессионных визуально-языковых моделях (VLM), использующих трехэтапную парадигму обучения: выравнивание-предварительное обучение-SFT. Методология представляет новый режим обучения аугментации, начиная с самоаугментации обучения VLM в зацикленной петле, за которой следует специализированная аугментация для использования навыков, полученных во время SFT. Этот подход постепенно улучшает качество данных, улучшая визуальную семантику и уменьшая галлюцинации, что прямо повышает производительность VLM. Исследование представляет семейство моделей VILA 2, которые превосходят существующие методы на основных бенчмарках без дополнительных сложностей.
VILA 2 достигает передовой производительности в рейтинге тестового набора данных MMMU среди открытых моделей, используя только общедоступные наборы данных. Процесс самоаугментации постепенно устраняет галлюцинации из подписей, улучшая качество и точность. Через итерационные раунды VILA 2 значительно увеличивает длину и качество подписей, преимущественно улучшаясь после первого раунда. Улучшенные подписи последовательно превосходят существующие методы на различных визуально-языковых бенчмарках, демонстрируя эффективность улучшенного качества предварительного обучения данных.
Специализированное обучение дополнительно улучшает производительность VILA 2 путем внедрения предметной экспертизы в общую VLM, улучшая точность в широком диапазоне задач. Комбинация самоаугментации и специализированного обучения приводит к значительному увеличению производительности на различных бенчмарках, расширяя возможности VILA. Эта методология циклов захвата и обучения не только улучшает качество данных, но также повышает производительность модели, способствуя последовательному улучшению точности и достижению новых передовых результатов.
Результаты показывают постепенное устранение галлюцинаций и улучшение качества подписей в процессе самоаугментации. Комбинированный подход самоаугментации и специализированного обучения приводит к улучшенной точности на различных задачах, достигая новых передовых результатов в рейтинге тестового набора данных MMMU среди открытых моделей. Эта методология демонстрирует потенциал итеративного улучшения данных и моделей в развитии возможностей визуально-языкового понимания.
В заключение, VILA 2 представляет собой значительный прорыв в области визуально-языковых моделей, достигая передовой производительности благодаря инновационным техникам самоаугментации и специализированной аугментации. Путем итеративного улучшения предварительных данных с использованием только общедоступных наборов данных модель демонстрирует превосходное качество подписей, уменьшение галлюцинаций и улучшение точности в различных визуально-языковых задачах. Комбинация общих знаний с предметной экспертизой приводит к значительному увеличению производительности на бенчмарках. Успех VILA 2 подчеркивает потенциал улучшения данных в развитии мультимодальных систем искусственного интеллекта, открывая путь к более сложному пониманию визуальной и текстовой информации. Этот подход не только улучшает производительность модели, но также демонстрирует эффективность использования существующих моделей для улучшения качества данных, что потенциально революционизирует разработку будущих систем искусственного интеллекта.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 47k+ ML на Reddit
Найдите предстоящие вебинары по ИИ здесь
Статья: «Революционизация понимания визуально-языковой информации: самоусовершенствование и интеграция специализированных знаний VILA 2»
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Revolutionising Visual-Language Understanding: VILA 2’s Self-Augmentation and Specialist Knowledge Integration.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























