«`html
Authorship Verification (AV) in Natural Language Processing
Авторская верификация (AV) является критически важной в обработке естественного языка (NLP) и определяет, разделяют ли два текста одного автора. Эта задача имеет огромное значение в различных областях, таких как судебная экспертиза, литература и цифровая безопасность.
Современные решения с использованием глубокого обучения
Традиционный подход к AV сильно полагался на стилометрический анализ, который использует лингвистические и стилистические характеристики, такие как длина слов и предложений, и частота служебных слов, для различения авторов. С появлением глубоких моделей обучения, таких как BERT и RoBERTa, область претерпела парадигмальное изменение. Эти современные подходы используют сложные закономерности в тексте, обеспечивая превосходную производительность по сравнению с традиционными стилометрическими техниками.
Требования к AV моделям
Основное вызов в авторской верификации заключается в точности определения авторства и предоставлении четких и надежных объяснений для принятых решений. Текущие AV модели в основном сосредоточены на бинарной классификации, что часто лишено прозрачности. Недостаток объяснимости является проблемой академического интереса и практической озабоченности. Анализ процесса принятия решений моделями ИИ необходим для создания доверия и надежности, особенно в выявлении и устранении скрытых предубеждений.
Новый подход InstructAV
Команда исследований в области информационных систем и технологий из Университета технологий и дизайна в Сингапуре представила новый подход под названием InstructAV, который направлен на улучшение точности и объяснимости в задачах авторской верификации. InstructAV использует большие языковые модели (LLMs) с методом параметрической оптимизации (PEFT). Этот инновационный фреймворк разработан для выравнивания принятых классификационных решений с прозрачными и понятными объяснениями, что является значительным прогрессом в этой области.
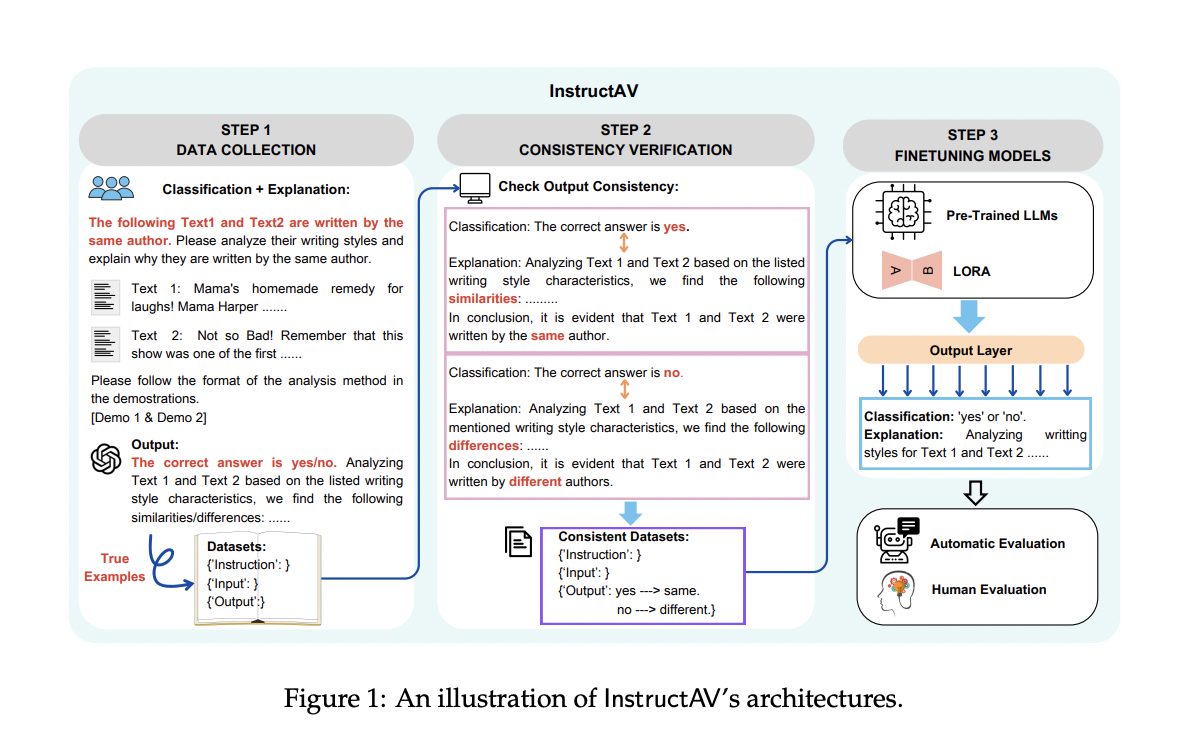
Методология InstructAV
Методология InstructAV включает три основных этапа: сбор данных, проверку согласованности и оптимизацию с использованием метода низкоранговой адаптации (LoRA). В начале фреймворк сосредотачивается на агрегировании объяснительных данных для образцов AV. Затем применяется строгая проверка качества для проверки согласованности объяснений с соответствующими метками классификации. Завершающий этап включает синтез данных оптимизации инструкций, который объединяет собранные метки классификации и соответствующие объяснения. Эти данные обеспечивают основу для оптимизации LLM с использованием метода адаптации LoRA, обеспечивая точную настройку моделей для задач AV и улучшая их способность предоставлять последовательные и надежные объяснения.
Результаты и выводы
Эффективность InstructAV была оценена через комплексные эксперименты на различных наборах данных AV, включая IMDB, Twitter и Yelp Reviews. Фреймворк продемонстрировал актуальную точность в авторской верификации, заметно превосходя базовые модели. Например, InstructAV с LLaMA-2-7B достиг точности 91,4% на наборе данных IMDB, что является значительным улучшением по сравнению с самой точной базовой моделью BERT, которая достигла 67,7%. InstructAV показал высокую точность классификации и установил новые стандарты в генерации согласованных и обоснованных объяснений для своих результатов.
Заключение
Фреймворк InstructAV решает критические задачи в области AV, объединяя высокую точность классификации с возможностью генерации подробных и надежных объяснений. Двойное внимание к производительности и интерпретируемости позиционирует InstructAV как передовое решение в этой области. Команда исследователей внесла значительные вклады, включая создание фреймворка InstructAV, создание трех наборов данных для оптимизации инструкций с надежными лингвистическими объяснениями, а также демонстрацию эффективности фреймворка через автоматизированные и человеческие оценки. Способность InstructAV повысить точность классификации, предоставляя высококачественные объяснения, является важным прогрессом в исследованиях AV.
«`

























