“`html
Повышение эффективности нейронных сетей: от подсчета параметров к практической подгонке данных
Нейронные сети, несмотря на свою теоретическую способность подгоняться под обучающие наборы с количеством образцов, равным количеству параметров, часто не справляются на практике из-за ограничений в процессах обучения. Это создает значительные вызовы для приложений, требующих точной подгонки данных, таких как медицинская диагностика, автономное вождение и модели языка большого масштаба. Понимание и преодоление этих ограничений критически важно для продвижения исследований в области искусственного интеллекта и повышения эффективности нейронных сетей в реальных задачах.
Практические решения и ценность
Текущие методы решения гибкости нейронных сетей включают в себя перепараметризацию, сверточные архитектуры, различные оптимизаторы и функции активации, такие как ReLU. Однако эти методы имеют заметные ограничения. Например, перепараметризованные модели, хотя теоретически способны к универсальной аппроксимации функций, часто не достигают оптимальных минимумов на практике из-за ограничений в алгоритмах обучения. Сверточные сети, хотя и более параметрически эффективны, чем многослойные перцептроны и Vision Transformers, не полностью используют свой потенциал на случайно размеченных данных. Оптимизаторы, такие как SGD и Adam, традиционно считались регуляризаторами, но на самом деле они могут ограничивать способность сети подгонять данные. Кроме того, функции активации, разработанные для предотвращения затухания и взрыва градиентов, непреднамеренно ограничивают способности подгонки данных.
Команда исследователей из Нью-Йоркского университета, Университета Мэриленда и Capital One предлагает комплексное эмпирическое исследование способности нейронных сетей подгонять данные с использованием метрики Effective Model Complexity (EMC). Этот новаторский подход измеряет максимальный размер выборки, который модель может идеально подогнать, учитывая реалистичные циклы обучения и различные типы данных. Путем систематической оценки влияния архитектур, оптимизаторов и функций активации предложенные методы предлагают новое понимание гибкости нейронных сетей. Инновация заключается в эмпирическом подходе к измерению способности и выявлению факторов, действительно влияющих на подгонку данных, предоставляя тем самым понимание за пределами теоретических границ аппроксимации.
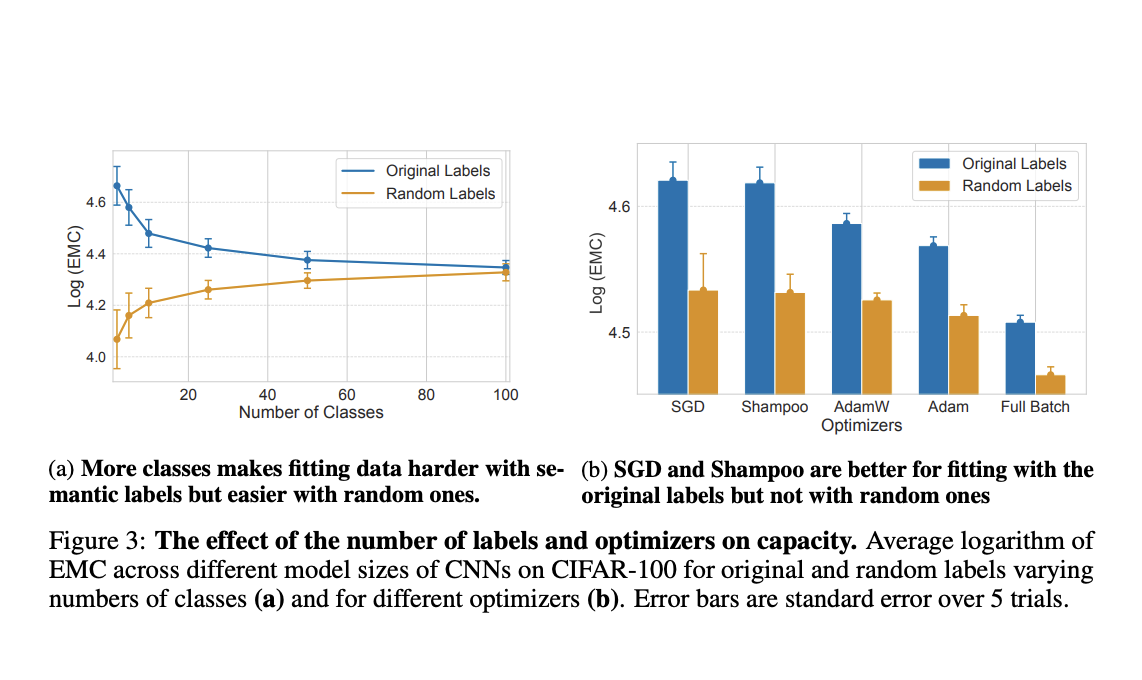
Метрика EMC рассчитывается через итеративный подход, начиная с небольшого обучающего набора и постепенно увеличивая его, пока модель не перестанет достигать 100% точности обучения. Этот метод применяется на нескольких наборах данных, включая MNIST, CIFAR-10, CIFAR-100 и ImageNet, а также на табличных наборах данных, таких как Forest Cover Type и Adult Income. Ключевые технические аспекты включают использование различных архитектур нейронных сетей (MLP, CNN, ViT) и оптимизаторов (SGD, Adam, AdamW, Shampoo). Исследование обеспечивает достижение минимума функции потерь в каждом обучающем запуске путем проверки норм градиента, стабильности потерь обучения и отсутствия отрицательных собственных значений в гессиане потерь.
Исследование раскрывает значительные идеи: стандартные оптимизаторы ограничивают способность подгонки данных, в то время как сверточные сети более параметрически эффективны даже на случайных данных. Функции активации ReLU обеспечивают лучшую подгонку данных по сравнению с сигмоидальными активациями. Сверточные сети (CNN) продемонстрировали превосходную способность подгонять обучающие данные по сравнению с многослойными перцептронами (MLP) и Vision Transformers (ViT), особенно на наборах данных с семантически согласованными метками. Кроме того, CNN, обученные стохастическим градиентным спуском (SGD), подгоняли больше обучающих образцов, чем те, которые обучались с полным градиентным спуском, и эта способность предсказывала лучшую обобщенность. Эффективность CNN особенно проявлялась в их способности подгонять больше правильно размеченных образцов по сравнению с неправильно размеченными, что свидетельствует о их способности обобщения.
В заключение, предложенные методы обеспечивают комплексную эмпирическую оценку гибкости нейронных сетей, вызывая сомнения в традиционном представлении о их способности подгонять данные. Исследование вводит метрику EMC для измерения практической способности, раскрывая, что сверточные сети более параметрически эффективны, чем ранее считалось, и что оптимизаторы и функции активации значительно влияют на подгонку данных. Эти идеи имеют существенное значение для улучшения обучения нейронных сетей и проектирования архитектуры, продвигая область путем решения критической проблемы в исследованиях по искусственному интеллекту.
“`

























