«`html
Модели машинного обучения для прогнозирования эффективности редактирования генов
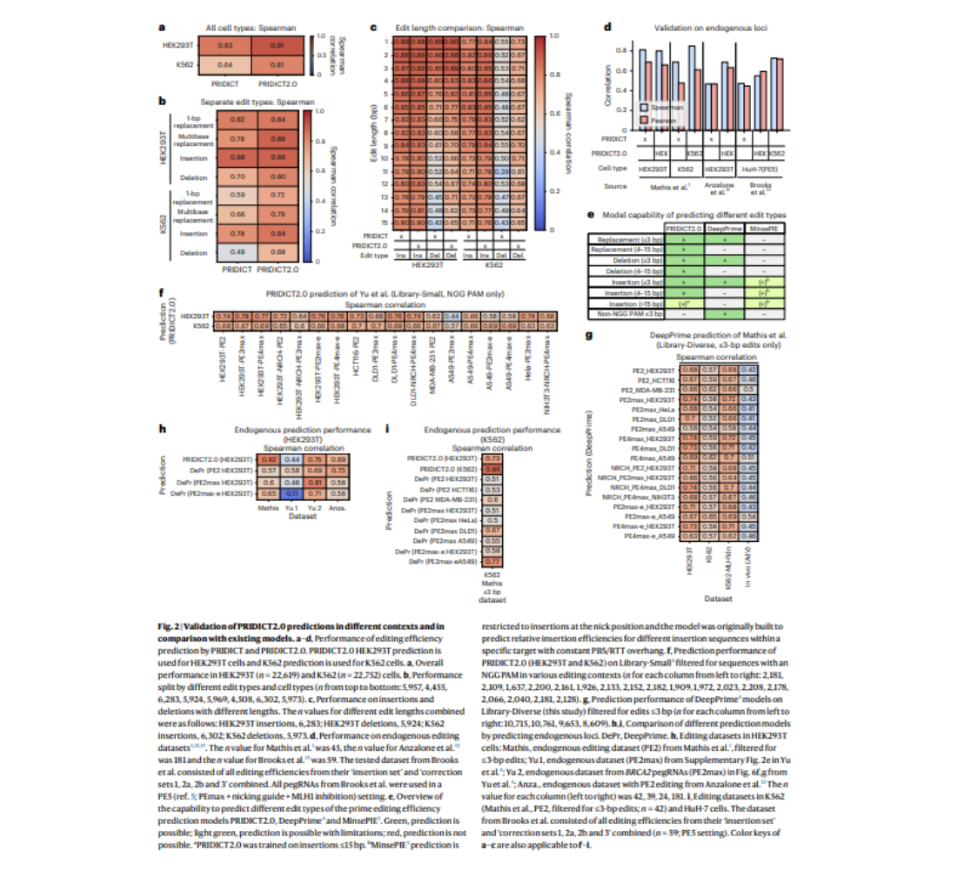
Для успешного редактирования генов крайне важно правильно спроектировать РНК-матрицу редактирования (pegRNA) и выбрать целевой локус. Исследователи создали две взаимодополняющие модели машинного обучения — PRIDICT2.0 и ePRIDICT — для прогнозирования эффективности редактирования генов при различных типах редактирования и в различных хроматиновых контекстах.
Модель PRIDICT2.0
Оценивает производительность pegRNA для редактирования до 15 пар оснований (bp) в линиях клеток с нарушенным и нормальным механизмом ремонта несоответствий (MMR).
Модель ePRIDICT
Количественно оценивает, как местные хроматиновые окружения влияют на скорость редактирования генов.
Эти модели представляют собой ценный инструмент для улучшения проектирования pegRNA и максимизации эффективности редактирования генов в различных биологических контекстах.
Роль хроматина в эффективности редактирования генов
Исследование также показало, что хроматиновые особенности оказывают значительное влияние на эффективность редактирования генов. Модель ePRIDICT была спроектирована для прогнозирования результатов редактирования, учитывая локус-специфические хроматиновые особенности, что добавляет новый уровень точности к прогнозам редактирования генов.
Проектирование и клонирование pegRNA
Использовалась TRIP-библиотека плазмид для проведения исследований хроматиновых контекстов. Для валидации pegRNA на эндогенных мишенях были выбраны 20 геномических сайтов из предыдущего скрининга — 10 сайтов с высокой и 10 с низкой эффективностью редактирования.
Производство и отбор вирусных векторов
Были произведены лентивирусные и псевдотипированные векторы AAV9 посредством трансфекции клеток HEK293T необходимыми плазмидами. Также был произведен отдельный вирусный вектор, содержащий компонент для редактирования генов. Библиотека pegRNA была заказана у коммерческого поставщика и включала патогенные варианты и мутации некодирующих областей.
Анализ библиотеки и эффективности редактирования
Чтение секвенировалось, фильтровалось и обрабатывалось для обеспечения точности. Эффективность редактирования рассчитывалась путем сравнения последовательностей чтения с измененными и исходными последовательностями, корректируя частоты фона. PegRNA валидировалась на основе конкретных критериев и усреднялась по различным повторам, что давало несколько наборов данных.
Модели машинного обучения, включая PRIDICT2.0, обучались и валидировались при помощи различных наборов данных, а их производительность оценивалась с использованием кросс-валидации и анализа важности признаков.
«`

























