«`html
Управление переменностью производительности в рамках кластеров с использованием PAL
Исследователи из Университета Висконсин-Мэдисон рассмотрели критическую проблему переменности производительности в рамках кластеров для машинного обучения (ML), ускоренного графическими процессорами (GPU), в больших вычислительных кластерах. Они выявили, что текущие методы управления кластерами, такие как SLURM и Kubernetes, часто не могут эффективно учитывать переменность производительности, что приводит к неоптимальному распределению ресурсов и низкой эффективности.
Как работает PAL
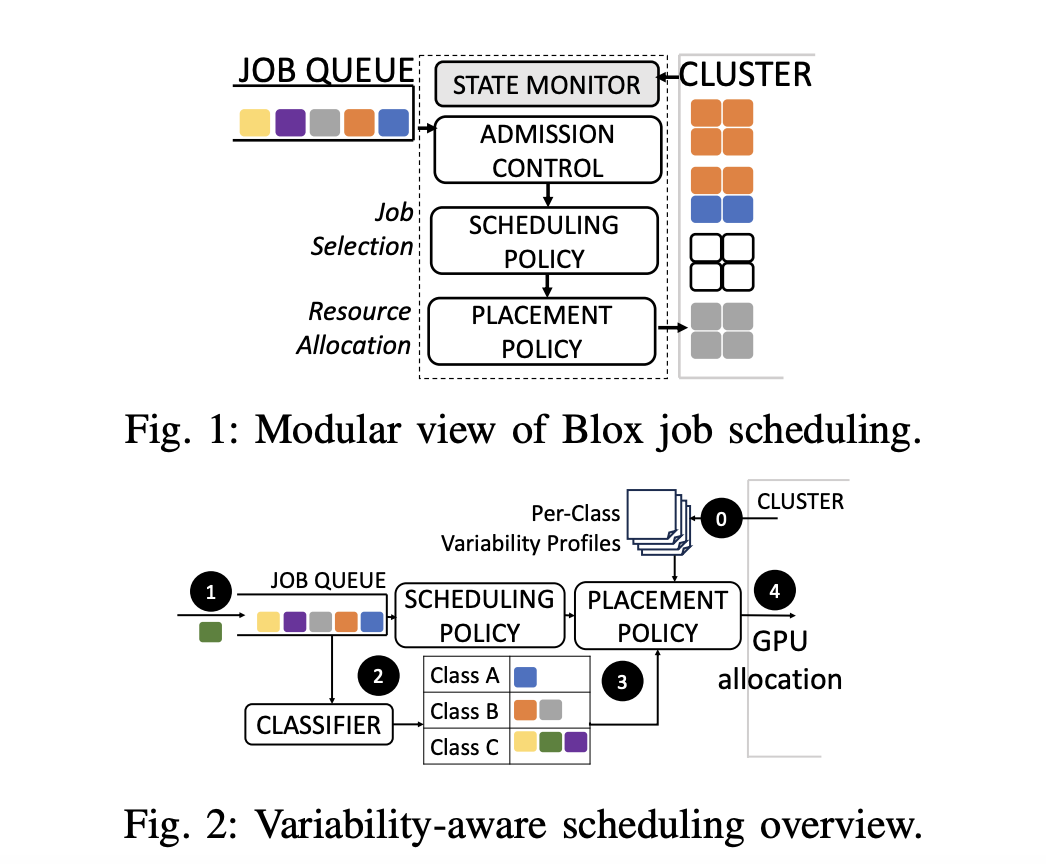
PAL — новый планировщик, разработанный для учета и смягчения эффектов переменности производительности в кластерах с GPU. Он профилирует как задания, так и узлы, позволяя принимать информированные решения о расписании, учитывая переменность производительности. PAL позволяет улучшить время выполнения заданий, использование ресурсов и общую эффективность кластера.
Практические применения
Несколько экспериментов показали, что PAL существенно превосходит существующие планировщики, достигая улучшения во времени выполнения заданий, использовании кластера и сокращении времени выполнения. Это делает PAL ценным инструментом для оптимизации крупномасштабных вычислительных систем, особенно тех, которые все более полагаются на GPU для ML и научных приложений.
Внедрение ИИ-решений
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Попробуйте ИИ ассистент в продажах здесь. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























