Q*: Универсальный подход искусственного интеллекта для улучшения производительности LLM в задачах рассуждения
Большие языковые модели (LLM) продемонстрировали удивительные способности в решении различных задач рассуждения, выраженных естественным языком, включая математические задачи, генерацию кода и планирование. Однако с увеличением сложности задач рассуждения даже самые передовые LLM сталкиваются с ошибками, галлюцинациями и несогласованностью из-за их авторегрессивной природы. Эта проблема особенно ощутима в задачах, требующих нескольких шагов рассуждения, где «система 1» мышления LLM — быстрое и инстинктивное, но менее точное — оказывается недостаточной. Необходимость более обдуманного, логического «системы 2» мышления становится критически важной для точного и последовательного решения сложных задач рассуждения.
Практические решения:
Для решения этих проблем были предприняты несколько попыток. Например, методы наблюдаемого дообучения (SFT) и обучения с подкреплением на основе обратной связи от людей (RLHF) направлены на согласование выводов LLM с ожиданиями человека. Также были разработаны методы прямой оптимизации предпочтений (DPO) и выравнивания для улучшения согласованности. В области улучшения LLM с возможностями планирования были применены методы «Tree-of-Thoughts» (ToT), A* поиск и Монте-Карло дерево поиска (MCTS). Для математического рассуждения и генерации кода были исследованы техники, такие как инженерия подсказок, дообучение с помощью задачно-специфических корпусов и обучение моделей вознаграждения.
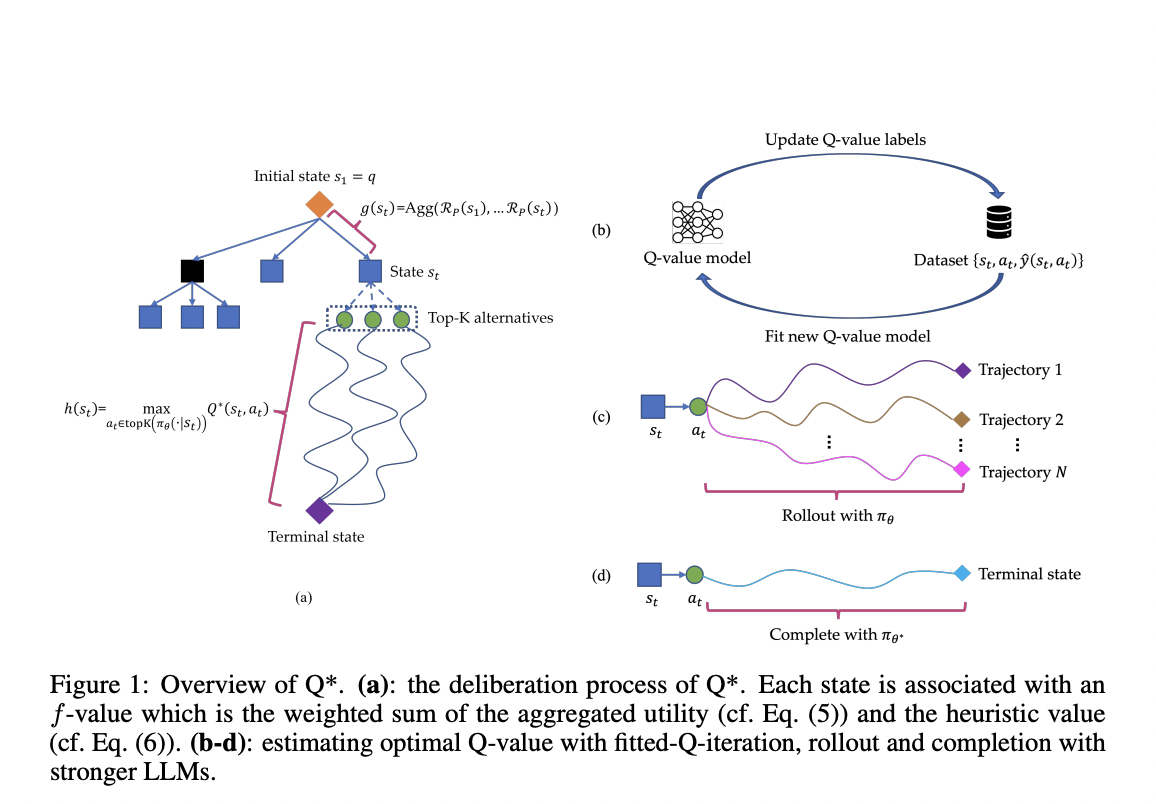
Исследователи из Skywork AI и Национального Технологического Университета Наньян представляют Q*, надежную среду, разработанную для улучшения многошаговых рассуждений LLM через обдуманное планирование. Этот подход формализует рассуждение LLM как процесс принятия решений Маркова (MDP), где состояние объединяет вводное обращение и предыдущие шаги рассуждения, действие представляет следующий шаг рассуждения, а вознаграждение измеряет успех задачи. Q* вводит общие методы оценки оптимальных Q-значений пар состояние-действие, включая обучение с подкреплением в офлайн режиме, выбор лучшей последовательности из прогнозов и завершение с использованием более мощных LLM.
Рамка Q* использует сложную архитектуру для улучшения многошаговых рассуждений LLM. Она формализует процесс как задачу эвристического поиска с использованием алгоритма A*. Рамка ассоциирует каждое состояние с f-значением, вычисляемым как взвешенная сумма агрегированной полезности и эвристического значения. Агрегированная полезность рассчитывается с использованием функции вознаграждения на основе процесса, а эвристическое значение оценивается с использованием оптимального Q-значения состояния. Q* представляет три метода оценки оптимальных Q-значений: обучение с подкреплением в офлайн режиме, обучение на примерах и приближение с использованием более мощных LLM. Эти методы позволяют рамке обучаться на тренировочных данных без задачно-специфических модификаций.
Значимость Q*:
Q* продемонстрировал значительное улучшение производительности на различных задачах рассуждения. На наборе данных GSM8K он улучшил Llama-2-7b, достигнув точности 80,8%, превзойдя ChatGPT-turbo. Для набора данных MATH Q* улучшил Llama-2-7b и DeepSeekMath-7b, достигнув точности 55,4%, превзойдя модели, такие как Gemini Ultra (4-shot). В задаче генерации кода Q* улучшил точность CodeQwen1.5-7b-Chat до 77,0% на наборе данных MBPP. Эти результаты последовательно показывают эффективность Q* в улучшении производительности LLM в задачах математического рассуждения и генерации кода, превзойдя традиционные методы и некоторые закрытые модели.
Q* представляет собой эффективный метод преодоления вызова многошагового рассуждения в LLM путем внедрения надежной среды обдуманного планирования. Этот подход улучшает способность LLM решать сложные проблемы, требующие глубокого, логического мышления за пределами простой авторегрессивной генерации токенов. В отличие от предыдущих методов, полагающихся на задачно-специфические функции полезности, Q* использует универсальную модель Q-значений, обученную исключительно на фактических данных, что делает ее легко адаптируемой к различным задачам рассуждения без модификаций. Рамка использует модели Q-значений для эвристических функций, эффективно направляя LLM без необходимости задачно-специфического дообучения, тем самым сохраняя производительность в различных задачах. Гибкость Q* проистекает из ее подхода одношагового рассмотрения, в отличие от более ресурсоемких методов, таких как MCTS. Обширные эксперименты в математическом рассуждении и генерации кода демонстрируют превосходство Q*, подчеркивая его потенциал для значительного улучшения способностей LLM в решении сложных проблем.

























