LLM-QFA Framework: A Once-for-All Quantization-Aware Training Approach to Reduce the Training Cost of Deploying Large Language Models (LLMs) Across Diverse Scenarios
Большие языковые модели (LLM) сделали значительные успехи в обработке естественного языка, но столкнулись с проблемами из-за памяти и вычислительных требований. Традиционные методы квантизации уменьшают размер модели за счет уменьшения битовой глубины весов модели, что помогает смягчить эти проблемы, но часто приводит к снижению производительности. Эта проблема усугубляется, когда LLM используются в различных ситуациях с ограниченными ресурсами. Это означает, что квантизационное обучение (QAT) необходимо проводить несколько раз для каждого применения, что требует больших ресурсов.
Практическое применение и ценность:
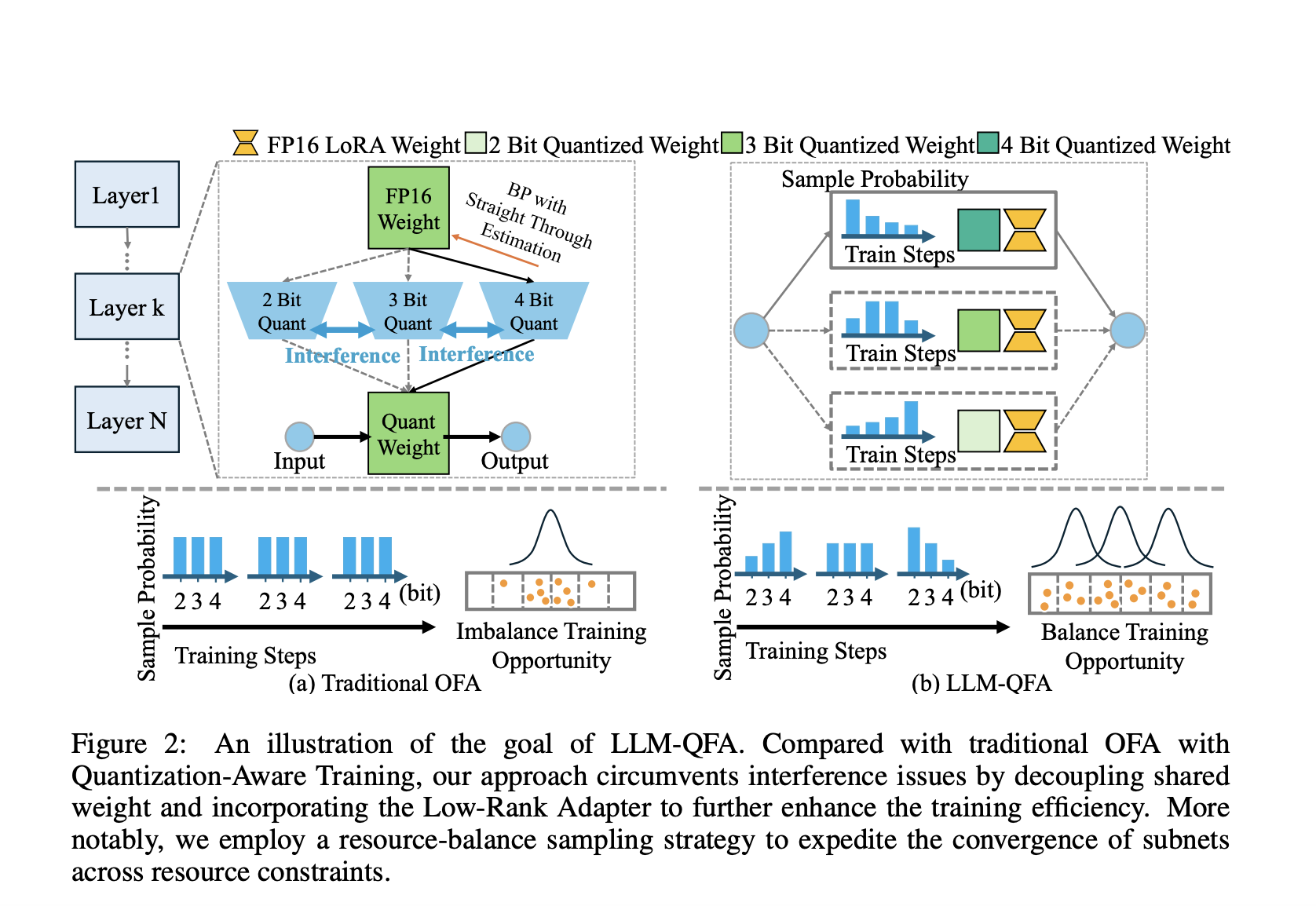
LLM-QFA (Quantization-Aware Fine-tuning once-for-all for LLMs) предлагает решение для эффективного обучения больших языковых моделей с учетом ограниченных ресурсов. Методика LLM-QFA решает проблемы путем обучения единственного супернабора, способного генерировать различные оптимальные подсети, предназначенные для различных сценариев развертывания без повторного обучения.
Фреймворк LLM-QFA устраняет проблемы, вызванные весовым обменом в традиционном квантизационном обучении путем разделения весов различных конфигураций квантизации. Это улучшает производительность и ресурсоэффективность LLM в различных сценариях развертывания.
Данный подход значительно снижает вычислительные затраты, связанные с традиционными методами квантизационного обучения, сохраняя и улучшая производительность. Это делает LLM более адаптивными и эффективными для реальных приложений, даже на устройствах с ограниченными ресурсами.

























