Ускорение LLM-вывода: Введение SampleAttention для эффективной обработки длинного контекста
Большие языковые модели (LLM) теперь поддерживают очень длинные контекстные окна, но квадратичная сложность стандартного внимания приводит к значительному увеличению задержки Time-to-First-Token (TTFT). Существующие методы решения этой сложности требуют дополнительного предварительного обучения или донастройки и часто ухудшают точность модели. Квадратичная природа механизма внимания в этих моделях значительно увеличивает вычислительное время, что затрудняет взаимодействие в реальном времени.
Практическое решение:
SampleAttention представляет собой адаптивный структурированный разреженный механизм внимания, который уменьшает вычислительные затраты, сохраняя точность, что делает его практичным решением для интеграции в предварительно обученные модели.
Метод SampleAttention был оценен на широко используемых вариантах LLM, таких как ChatGLM2-6B и internLM2-7B, демонстрируя его эффективность в длинных контекстных сценариях. SampleAttention показал значительное улучшение производительности, уменьшив TTFT до 2,42 раз по сравнению с FlashAttention, при этом поддерживая практически нулевую потерю точности.
Практическое применение:
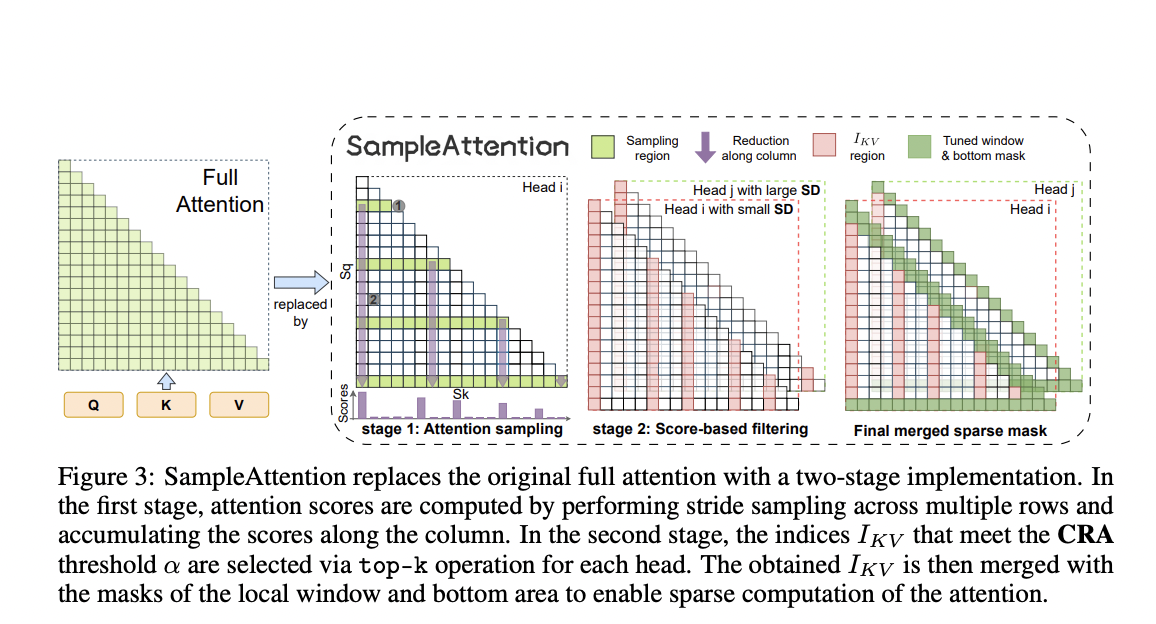
SampleAttention представляет собой обещающий прогресс для реального времени применения LLM, обеспечивая эффективную обработку важной информации с помощью локальных окон и столбчатых узоров.
Если вы хотите использовать преимущества искусственного интеллекта для развития вашей компании, обратитесь к нам для советов по внедрению ИИ.
Не упустите возможность улучшить свою работу с помощью интеллектуальных решений от Flycode.ru.

























