RetrievalAttention: Ускорение вычислений внимания и снижение потребления памяти GPU без обучения
Практические решения и ценность:
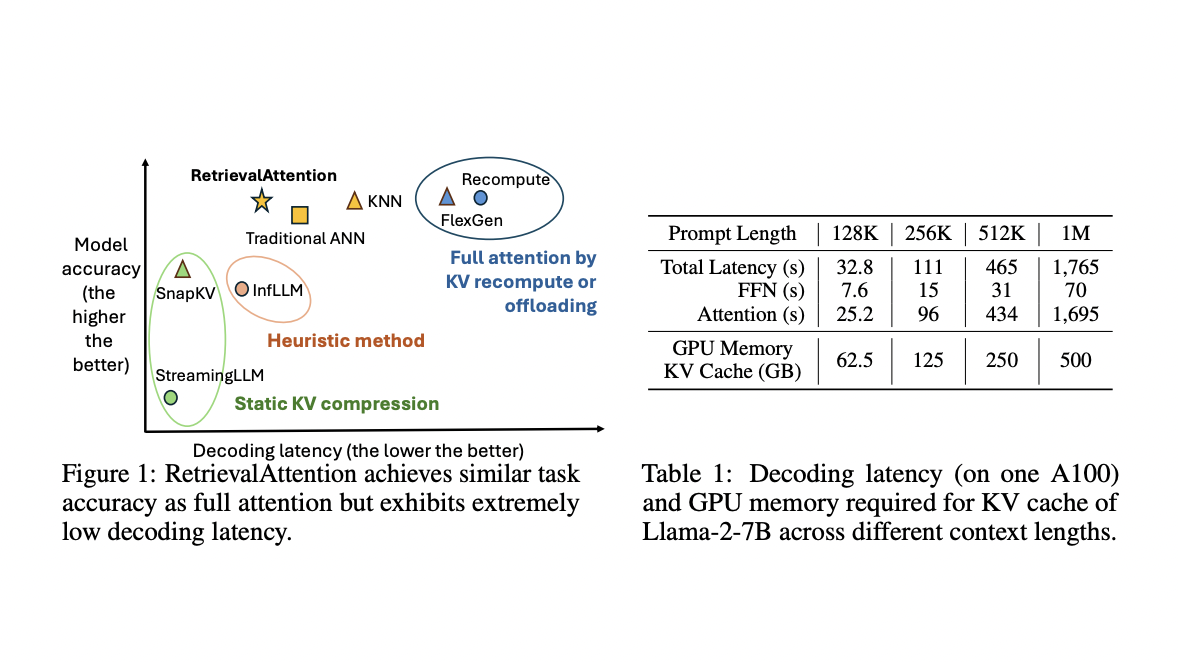
RetrievalAttention — инновационный метод для ускорения обработки длинных контекстов LLM, который переносит большинство векторов KV в память ЦП и использует динамическое разреженное внимание через векторный поиск. Этот подход позволяет эффективно выделять критические токены для генерации модели.
Экспериментальные результаты показывают, что RetrievalAttention демонстрирует значительное ускорение декодирования в 4,9 раза и 1,98 раза по сравнению с точным KNN и традиционными методами ANNS соответственно на одном GPU RTX4090 с контекстом из 128 тыс. токенов. RetrievalAttention — первая система, поддерживающая работу с LLM уровня 8B с 128 тыс. токенов на одном GPU 4090 (24 ГБ), обеспечивая приемлемую задержку и сохраняя точность модели.
Этот прорыв значительно повышает эффективность и доступность больших языковых моделей для обработки обширных контекстов.
Практические шаги для внедрения ИИ в ваш бизнес:
1. Проанализируйте, как ИИ может изменить вашу работу и определите области для автоматизации.
2. Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
3. Подберите подходящее решение для вашего бизнеса и начните внедрение с небольшого проекта.
4. Анализируйте результаты и KPI, постепенно расширяя автоматизацию на основе полученного опыта.
Если вам нужны советы по внедрению ИИ, обращайтесь к нам на Telegram.
Попробуйте ИИ ассистент в продажах от Flycode.ru. Этот ассистент поможет вам эффективно взаимодействовать с клиентами, генерировать контент и снижать нагрузку на персонал.
Узнайте, как ИИ может оптимизировать ваши процессы с решениями от Flycode.ru.

























