Применение INT-FlashAttention для улучшения эффективности и скорости работы LLMs
Проблема:
Большие языковые модели (LLMs) сталкиваются с проблемой увеличения сложности вычислений и использования памяти при обработке длинных последовательностей, что затрудняет их масштабирование для приложений с длинными контекстами.
Решение:
FlashAttention был разработан для ускорения вычислений внимания и оптимизации использования памяти за счет разделения вычислений на более мелкие части, что позволяет эффективнее использовать память GPU.
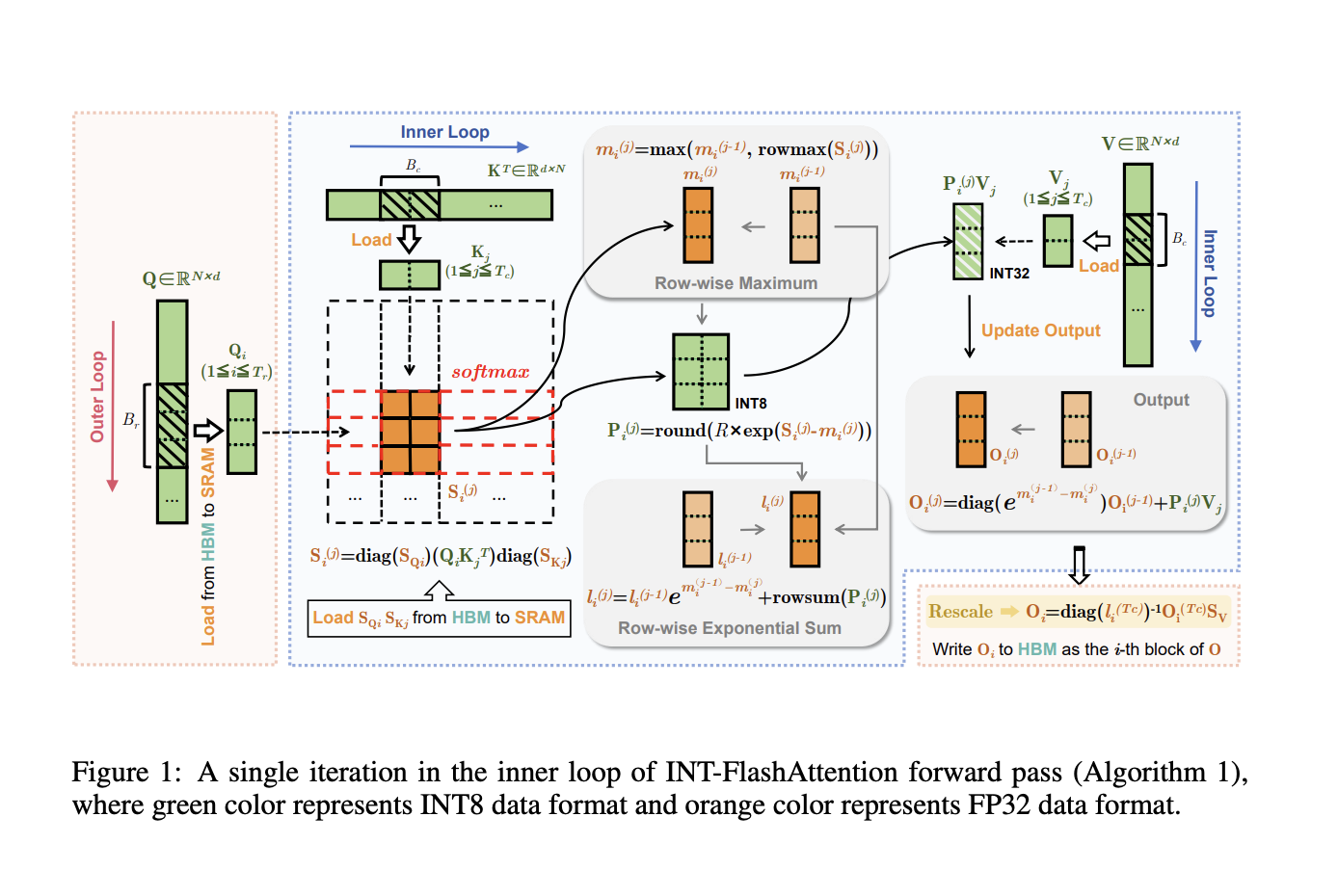
Комбинирование методов квантования с FlashAttention представляет собой интригующую новую тему исследований. Квантование использует менее сложные числовые формы, такие как INT8 (8-битное целое число), для ускорения обработки и экономии памяти.
Преимущества INT-FlashAttention:
INT-FlashAttention обеспечивает ускорение скорости вывода на 72% по сравнению с реализацией FlashAttention на FP16 и устраняет ошибку квантования на 82%, что повышает точность. Это значительно увеличивает масштабируемость и эффективность LLMs на широко используемом оборудовании, таком как Ampere GPUs.
Заключение:
INT-FlashAttention представляет собой ключевой шаг к улучшению эффективности и доступности высокопроизводительных LLMs для широкого спектра приложений. Его использование вместе с квантованием и FlashAttention обеспечивает эффективный способ улучшения скорости вывода и точности моделей обработки языка на больших объемах данных.

























