“`html
Искусственный интеллект (ИИ) в решении задач манипуляции
Использование физических симуляций для обучения роботов и последующего применения полученной политики в реальном мире представляет потенциальный подход к созданию универсальных роботов и решению сложных задач принятия решений. Однако основной вызов заключается в преодолении разрыва между симуляцией и реальностью (sim-to-real). Требуется большое количество данных для обучения решению этих задач, и сбор данных в реальном времени с физическими роботами становится сложным из-за неограниченной требовательности к обучению через современные симуляции. Поэтому важно плавно переносить и применять политики управления роботами в реальном мире с использованием обучения с подкреплением (RL).
Обучение роботов через перенос из симуляции в реальность
Физические симуляции используются для развития навыков роботов в манипуляциях, таких как работа на столе и передвижение, хотя разрывы полностью не устранены. Текущий подход включает в себя идентификацию системы, случайную доменную адаптацию, адаптацию к реальному миру и расширение симулятора. Успешный перенос из симуляции в реальность включает передвижение, непрехватывающие манипуляции и помогает в улучшении производительности. Еще один метод, обучение роботов с участием человека, является распространенной моделью, которая внедряет знания человека в автономные системы. В этом методе используются различные обратные связи от человека для решения последовательных задач принятия решений.
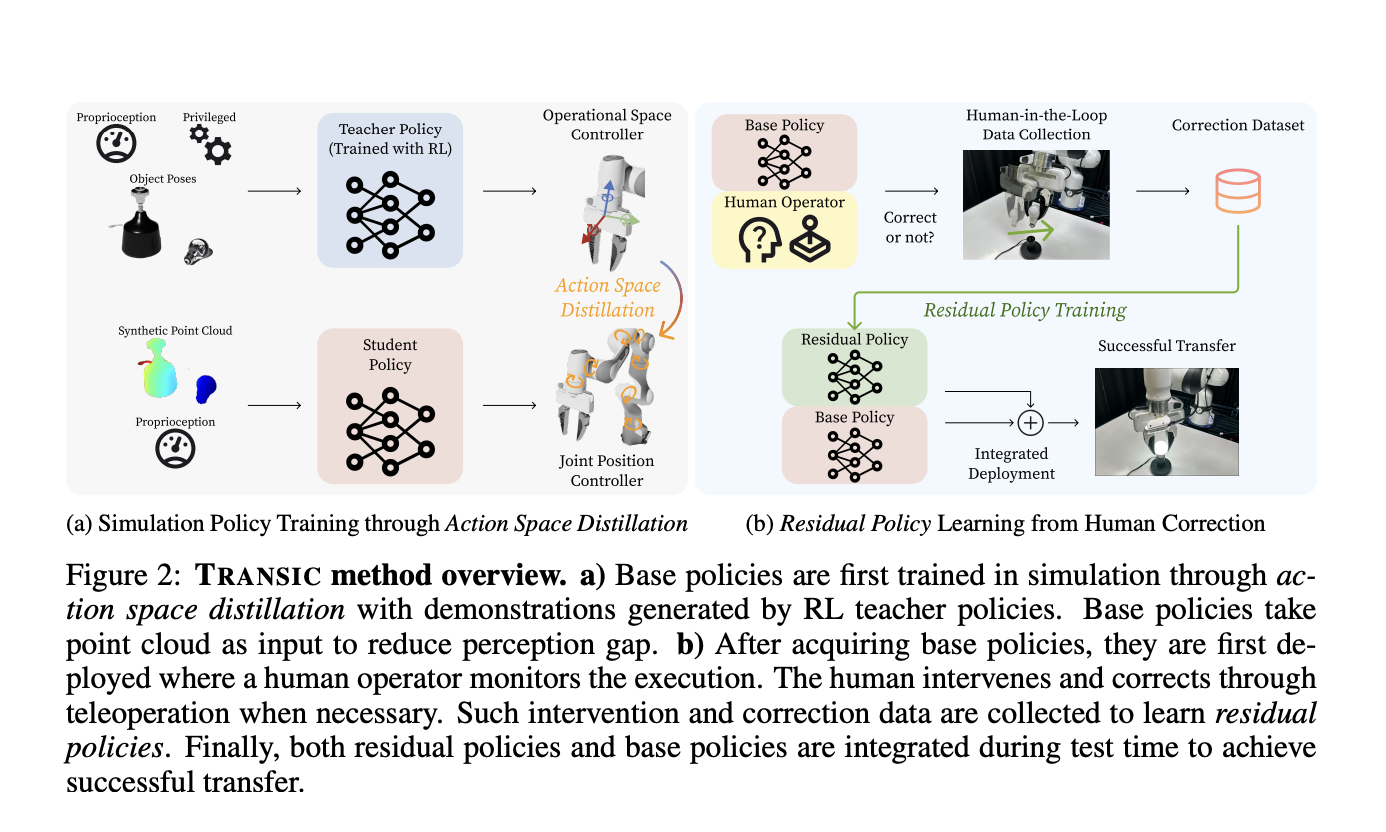
Исследователи из Стэнфордского университета предложили метод TRANSIC, основанный на данных, чтобы обеспечить успешный перенос из симуляции в реальность политик с использованием модели с участием человека. Это позволяет людям улучшать симуляционные политики для решения нескольких неучтенных разрывов между симуляцией и реальностью с помощью вмешательства и онлайн-коррекции. Коррекции помогают в обучении остаточных политик и интегрируются с симуляционными политиками для автономного выполнения. Также успешно достигается перенос из симуляции в реальность в сложных задачах манипуляции с использованием TRANSIC, и этот метод обладает хорошими свойствами, такими как масштабирование с усилиями человека.
Для устранения разрывов между симуляцией и реальностью с помощью TRANSIC созданы 5 различных пар симуляция-реальность, и специально созданы большие разрывы для каждой пары. TRANSIC достигает средней успешности 77% для всех 5 пар с разрывами между симуляцией и реальностью и превосходит лучший базовый метод IWR, который может достигнуть только среднюю успешность 18%. Некоторые возможности TRANSIC включают обучение многоразовых навыков для обобщения объектов на уровне категорий, работу в полностью автономной среде после обучения механизма управления, учет частичных облаков точек и данных коррекции, а также обучение постоянных визуальных характеристик между симуляцией и реальностью.
Исследователи доказали, что TRANSIC превосходит лучший базовый метод IWR в масштабируемости данных человека. При увеличении размера данных коррекции с 25% до 75% предложенный метод достигает относительного улучшения средней успешности на 42%, превосходя IWR, который достигает только 23% относительного улучшения. Более того, производительность IWR становится постоянной на ранней стадии и начинает уменьшаться при наличии большего количества данных человека. IWR не способен моделировать поведенческие режимы людей и обученных роботов, но TRANSIC преодолевает эти вызовы путем обучения остаточных политик с учетом коррекции человека.
В заключение, исследователи из Стэнфордского университета представили метод TRANSIC, основанный на участии человека, для обработки переноса политик из симуляции в реальность для задач манипуляции. Для достижения успеха хорошая базовая политика, выученная из симуляции, интегрируется с ограниченными данными из реального мира. Предложенный метод решает проблему эффективного использования данных коррекции человека для преодоления разрыва между симуляцией и реальностью. Однако некоторые ограничения этого метода заключаются в том, что: (a) текущие задачи ограничены только сценарием на столе с мягким параллельным захватом; (b) в фазе сбора данных коррекции требуется участие человека; (c) сложно обучиться самостоятельно, поэтому TRANSIC нуждается в симуляционных политиках с разумной производительностью.
Посмотрите статью и проект. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 42k+ ML SubReddit.
Источник: MarkTechPost
“`
























