Улучшение процесса обучения языковых моделей с помощью GenQA
Обработка естественного языка значительно улучшила настройку языковых моделей. Этот процесс включает улучшение ИИ-моделей для более эффективного выполнения конкретных задач путем их обучения на обширных наборах данных. Однако создание таких больших и разнообразных наборов данных является сложным и дорогостоящим процессом, часто требующим значительного человеческого вмешательства. Эта проблема создала разрыв между академическим исследованием, которое обычно использует небольшие наборы данных, и промышленными приложениями, которые получают выгоду от обширных, тщательно настроенных наборов данных.
Проблема и решение
Одной из основных проблем в этой области является зависимость от данных, аннотированных людьми. Ручное составление наборов данных трудоемко и дорого, что ограничивает масштаб и разнообразие данных, которые можно сгенерировать. Существующие методы для решения этой проблемы включают использование больших языковых моделей для модификации и дополнения контента, написанного людьми. Однако эти методы все еще требуют доработки в плане масштабируемости и разнообразия.
Исследователи из Университета Мэриленда предложили инновационное решение этой проблемы, представив GenQA. Этот метод использует один хорошо разработанный запрос для автономной генерации миллионов разнообразных примеров инструкций. GenQA стремится создать масштабные и высокоразнообразные наборы данных, минимизируя человеческое вмешательство. Основная технология GenQA заключается в использовании генераторных запросов для улучшения случайности и разнообразия выводов, производимых языковыми моделями.
Результаты и применение
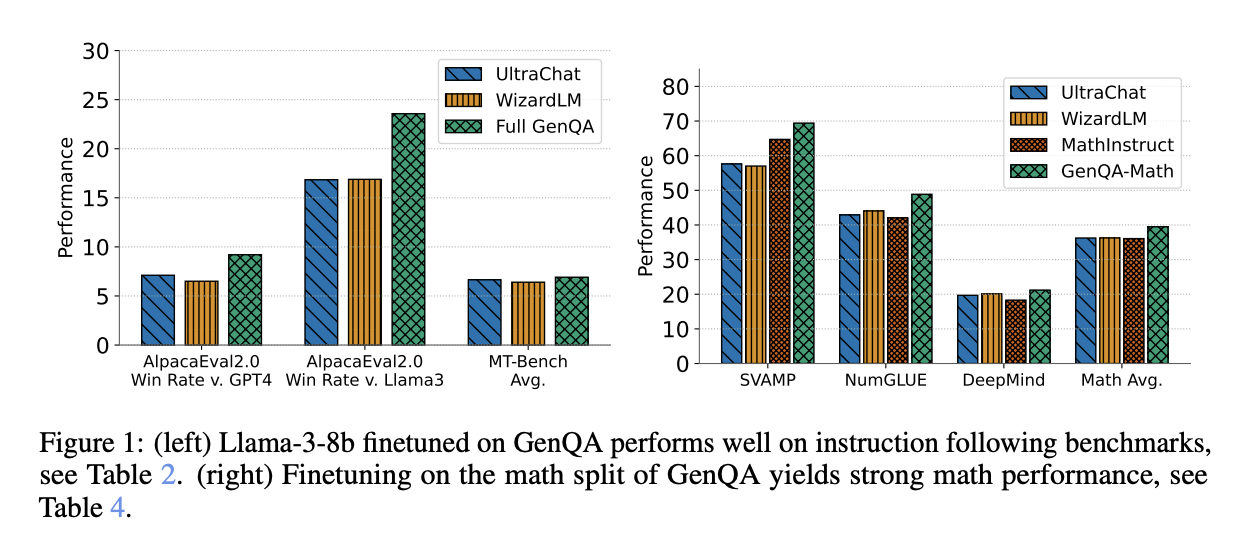
Исследователи проверили набор данных GenQA, настраивая модель Llama-3 8B. Результаты были впечатляющими, с производительностью модели на знаниевых и разговорных тестах, соответствующей или превышающей результаты наборов данных, таких как WizardLM и UltraChat. Выводы показали, что генераторные запросы GenQA привели к высокому разнообразию сгенерированных вопросов и ответов, а также к широкой применимости набора данных.
В заключение, внедрение GenQA демонстрирует, что создание масштабных и разнообразных наборов данных с минимальным человеческим вмешательством возможно. Этот подход снижает затраты и сокращает разрыв между академическим и промышленным практиками. Успех GenQA в настройке модели Llama-3 8B подчеркивает его потенциал для трансформации исследований и применений в области искусственного интеллекта.

























