“`html
Исследователи из Университета Торонто представили глубокую модель обучения, которая превосходит систему Google AI в предсказании структур пептидов
Пептиды, как высоко гибкие биомолекулы, играют важную роль в многочисленных биологических процессах и представляют большой интерес для разработки терапевтических средств. Понимание конформации пептидов критично для исследований, поскольку их функция зависит от их формы. Понимание того, как пептид складывается, позволяет исследователям разрабатывать новые пептиды с определенными терапевтическими применениями или помогает им выявлять процессы, посредством которых естественные пептиды работают на молекулярном уровне, что приводит к прогрессу в различных областях.
Решение PepFlow
Ученые из Университета Торонто представили PepFlow для решения задачи точного предсказания полного спектра конформаций, которые могут принимать пептиды. Традиционные методы требуют помощи для эффективного моделирования динамической природы пептидов, что позволяет более продвинутому подходу захватить их различные складывающиеся узоры и конформации.
Методы прогнозирования биомолекулярных структур, такие как AlphaFold, сделали значительные успехи в предсказании односторонних состояний, но не справляются с динамическими конформациями пептидов. Например, AlphaFold2 отлично предсказывает статические структуры белков, но не предназначен для генерации спектра конформаций пептидов. Это ограничивает понимание и использование пептидов в биологических и терапевтических контекстах.
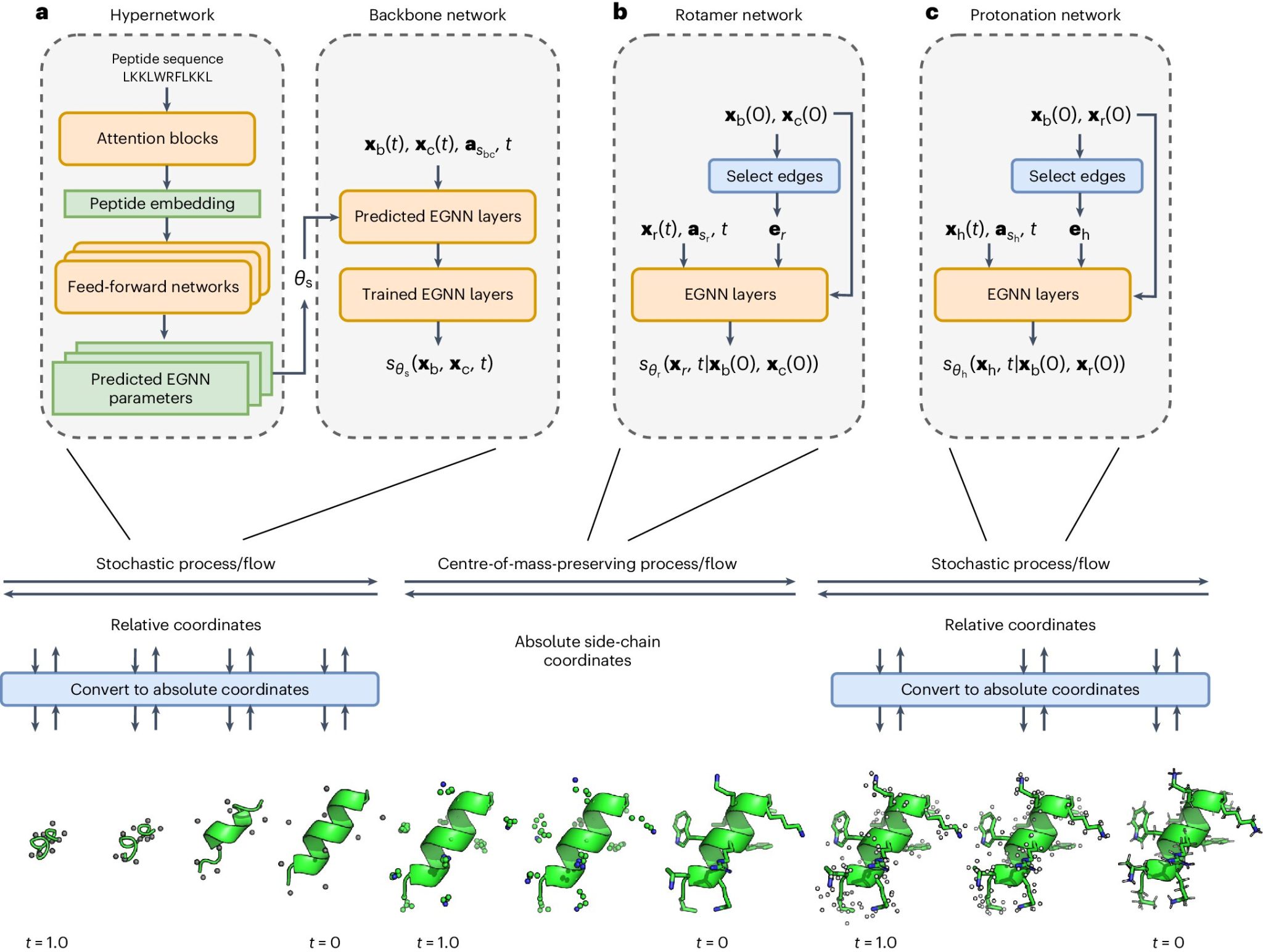
PepFlow – это модель глубокого обучения, специально разработанная для предсказания полного спектра конформаций пептидов. PepFlow использует диффузионную структуру и интегрирует гиперсеть для предсказания параметров сети, специфичных для последовательности, что позволяет ей выполнять прямую выборку всех атомов из допустимого конформационного пространства пептидов. Такой подход позволяет PepFlow точно и эффективно моделировать структуры пептидов, превосходя возможности текущих методов, таких как AlphaFold2.
PepFlow объединяет машинное обучение с физико-основанным моделированием для захвата динамического энергетического ландшафта пептидов. Модель обучается в диффузионной структуре, которая включает постепенное преобразование простого начального распределения в сложное целевое распределение через серию выученных шагов. Этот процесс позволяет PepFlow эффективно генерировать разнообразные конформации пептидов. Гиперсеть используется для предсказания специфических параметров последовательности, обеспечивая способность модели адаптироваться к различным последовательностям пептидов и их уникальным складывающимся узорам.
Одним из ключевых нововведений PepFlow является его модульный подход к генерации, который помогает смягчить запретные вычислительные затраты, связанные с обобщенным моделированием всех атомов. Разбивая процесс генерации и используя гиперсеть, PepFlow может достичь высокой точности и эффективности. Модель может предсказывать структуры пептидов и рекапитулировать экспериментальные ансамбли пептидов за долю времени, необходимого для выполнения традиционных методов.
Производительность PepFlow заметна своей способностью моделировать необычные формы пептидов, такие как макроциклизация, когда пептиды образуют кольцевые структуры. Такие возможности ценны для разработки лекарств, поскольку макроциклы пептидов являются многообещающей областью исследований для терапевтических применений. PepFlow демонстрирует значительные улучшения по сравнению с существующими моделями, предлагая всестороннее и эффективное решение для выборки конформаций пептидов.
В заключение, PepFlow решает задачу предсказания полного спектра конформаций пептидов. Совмещая глубокое обучение с физико-основанным моделированием, PepFlow предлагает высокоточный и эффективный метод захвата динамической природы пептидов. Это новшество не только превосходит текущие методы, такие как AlphaFold2, но также имеет значительный потенциал для продвижения разработки терапевтических средств через разработку лекарств на основе пептидов. В исследовании указаны области для дальнейшего улучшения, такие как обучение с явными данными растворителя, но текущие возможности PepFlow являются существенным прогрессом в биомолекулярном моделировании.
“`









