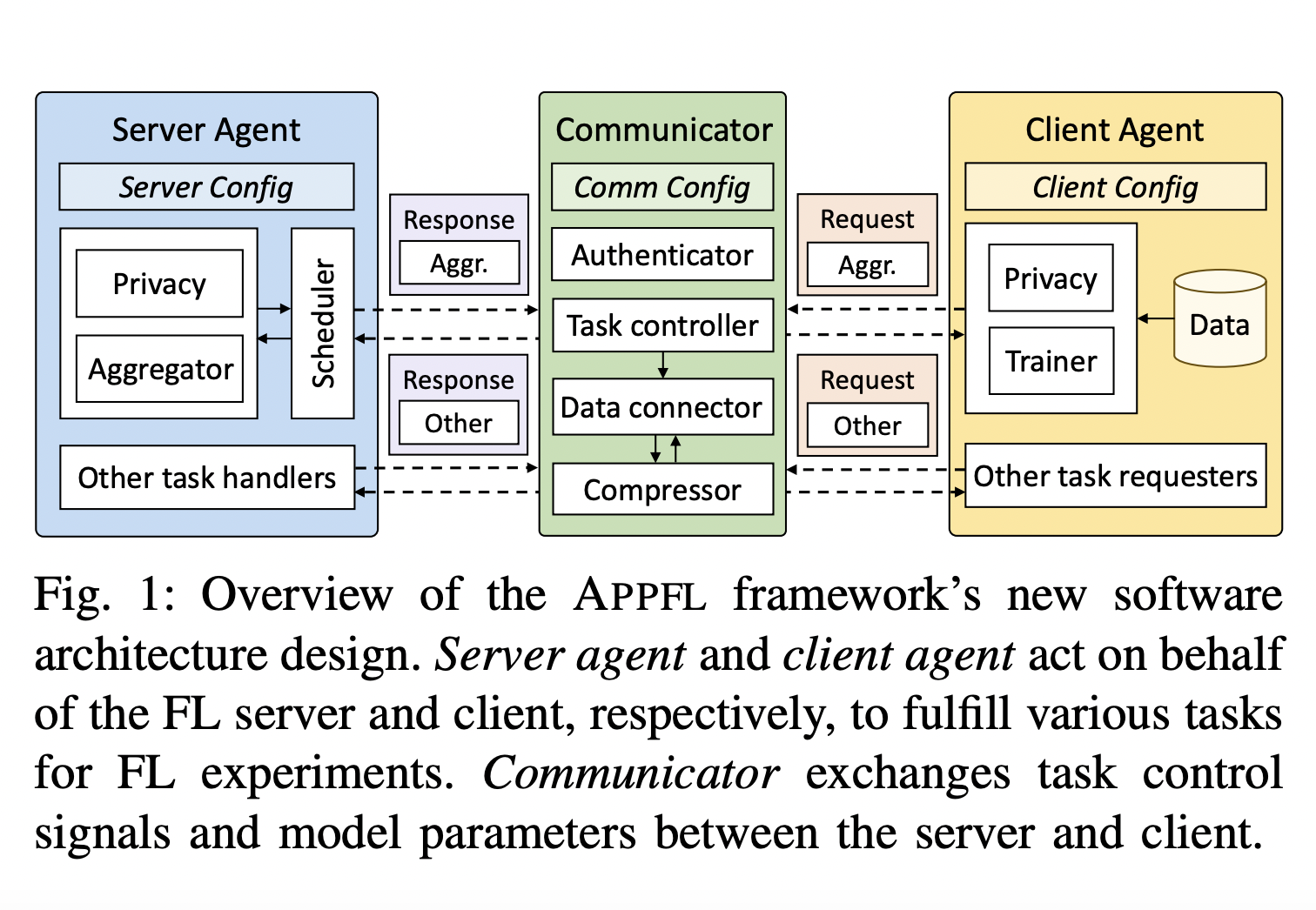
Продвинутое конфиденциальное федеративное обучение (APPFL): Решение для проблем с данными, вычислительными неравенствами и безопасностью в децентрализованном машинном обучении
Федеративное обучение (FL) – мощная парадигма машинного обучения, которая позволяет нескольким владельцам данных обучать модели без централизации их данных совместно. Этот подход особенно ценен в областях, где конфиденциальность данных играет важную роль, таких как здравоохранение, финансы и энергетика. Основа федеративного обучения заключается в обучении моделей на децентрализованных данных, хранящихся на устройствах каждого клиента. Однако этот распределенный характер создает значительные проблемы, включая гетерогенность данных, различия в вычислительных мощностях устройств и риски безопасности, такие как возможное раскрытие чувствительной информации через обновления модели. Несмотря на эти проблемы, федеративное обучение представляет собой многообещающий путь для использования больших распределенных наборов данных для создания высокоточных моделей, сохраняя при этом конфиденциальность пользователей.
Решение проблем
Одной из основных проблем федеративного обучения является различное качество и распределение данных на устройствах клиентов. В традиционном машинном обучении данные обычно считаются равномерно распределенными и независимо собранными. Однако данные клиентов часто являются несбалансированными и независимыми в федеративной среде. Например, одно устройство может содержать сильно отличающиеся данные от другого, что приводит к различиям в целях обучения у разных клиентов. Эта вариативность может привести к субоптимальной производительности модели, когда локальные обновления объединяются в глобальную модель. Вычислительная мощность устройств клиентов сильно разнится, что приводит к замедлению процесса обучения на более медленных устройствах. Эти расхождения затрудняют эффективную синхронизацию процесса обучения, что приводит к неэффективности и снижению точности модели.
Разработка APPFL
Исследователи из Национальной лаборатории Аргонн, Университета Иллинойса и Университета штата Аризона разработали фреймворк Advanced Privacy-Preserving Federated Learning (APPFL) в ответ на эти ограничения. Этот новый фреймворк предлагает комплексное и гибкое решение, решающее технические и безопасностные проблемы текущих моделей FL. APPFL улучшает эффективность, безопасность и масштабируемость систем федеративного обучения. Он поддерживает синхронные и асинхронные стратегии агрегирования, что позволяет адаптироваться к различным сценариям развертывания. В нем предусмотрены надежные механизмы защиты конфиденциальности, чтобы защитить от атак на восстановление данных, обеспечивая при этом обучение модели высокого качества на распределенных клиентах.


























