«`html
Решение для эффективного обучения и переноса знаний в машинном обучении
Обучение с подкреплением (Reinforcement Learning, RL) сосредотачивается на том, как агенты могут учиться принимать решения, взаимодействуя с окружающей средой. Основная задача агентов — максимизировать накопленные вознаграждения за счет проб и ошибок. Однако для эффективного применения RL требуется большое количество данных, и возникают сложности с обработкой ограниченных или отсутствующих вознаграждений в реальных приложениях.
Проблема и практическое решение
Одной из основных проблем в RL является нехватка данных во воплощенном искусственном интеллекте, где агенты должны взаимодействовать с физическим окружением. Это осложняется необходимостью значительного количества данных с метками вознаграждений для эффективного обучения агентов. Для решения этой проблемы требуется разработка методов, способных повысить эффективность использования данных и обеспечить передачу знаний между различными задачами.
Существующие методы в RL часто нуждаются в помощи по сбору и использованию данных. Техники, такие как Hindsight Experience Replay, пытаются повторно использовать собранные опыты для улучшения эффективности обучения. Однако эти методы все еще нуждаются в улучшении, так как требуют значительного человеческого контроля и неспособны автономно адаптироваться к новым задачам.
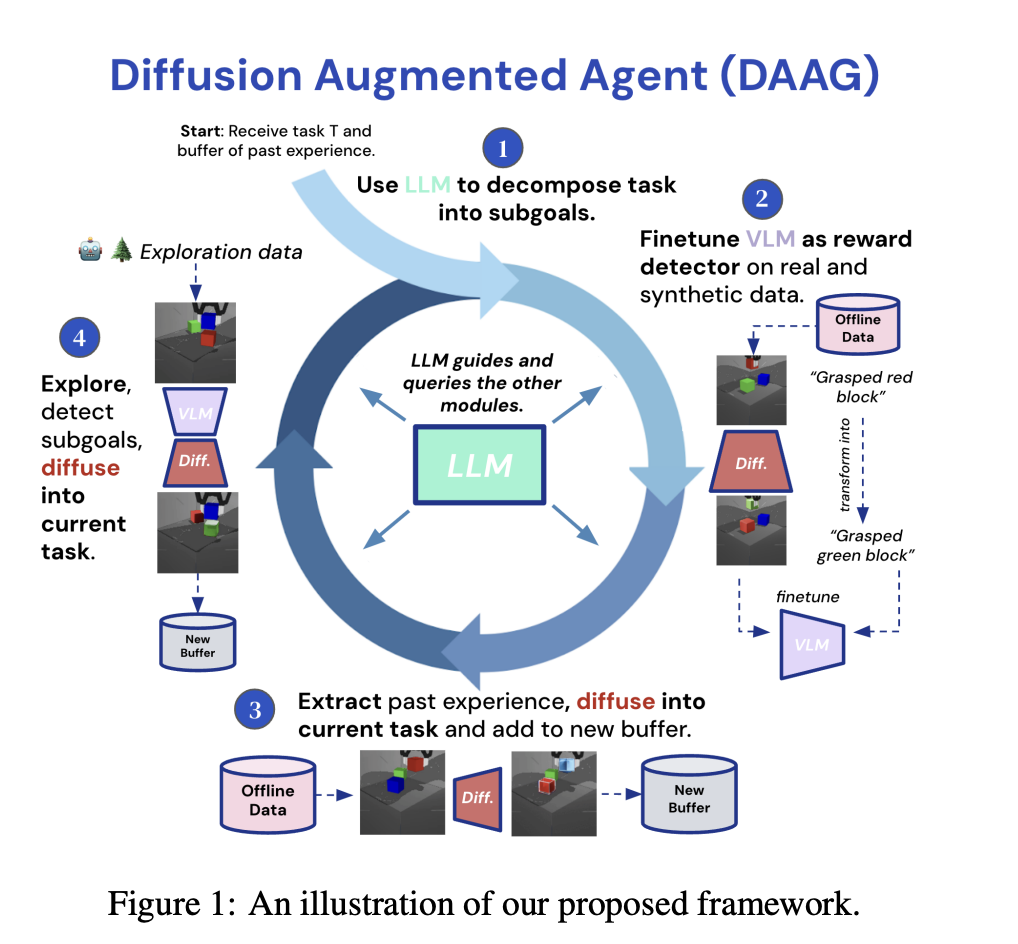
Исследователи из Imperial College London и Google DeepMind представили фреймворк Diffusion Augmented Agents (DAAG), который интегрирует большие языковые модели, модели видеообработки и модели диффузии для повышения эффективности выборки и передачи знаний. Этот фреймворк разработан для автономной работы, минимизируя необходимость человеческого контроля и делая процесс обучения более эффективным и масштабируемым.
Практические результаты
Фреймворк DAAG продемонстрировал значительное улучшение различных метрик. В среде управления роботами процент успешного выполнения задач увеличился на 40%, при этом количество образцов данных с метками вознаграждений сократилось на 50%. DAAG сократил количество тренировочных эпизодов на 30% для задач навигации, сохраняя при этом высокую точность. Кроме того, в задачах, связанных со стыковкой цветных кубиков, фреймворк достиг 35% более высокого уровня завершения, чем традиционные методы RL. Эти количественные результаты демонстрируют эффективность DAAG в улучшении производительности обучения и передачи знаний между задачами.
В заключение, фреймворк DAAG предлагает многообещающее решение для проблемы нехватки данных и передачи знаний в RL. Использование передовых моделей и автономных процессов значительно повышает эффективность обучения во воплощенных агентах. Это открытие является шагом вперед в создании более способных и адаптивных систем искусственного интеллекта.
Если вы хотите узнать больше о решениях на основе искусственного интеллекта, пишите нам на Telegram или посетите наш сайт Flycode.ru.
«`

























