«`html
Увеличение энергоэффективности в области обслуживания больших языковых моделей с помощью DynamoLLM
Большие языковые модели (LLM) стали неотъемлемой частью многих приложений благодаря их быстрому росту и широкому использованию. Кластеры обработки запросов LLM управляют огромным потоком запросов, каждый из которых имеет строгие цели уровня обслуживания (SLO), которые должны быть выполнены для гарантированной адекватной производительности, поскольку эти модели стали более интегрированными в различные услуги. LLM обычно выполняются на мощных высокопроизводительных GPU, чтобы удовлетворить эти ожидания. Этот метод гарантирует, что модели могут быстро и точно обрабатывать данные, но он также потребляет много энергии и увеличивает выбросы углерода.
Оптимизация энергопотребления
Существует значительный потенциал для увеличения энергоэффективности кластеров обработки LLM за счет использования внутренней гетерогенности и органических колебаний в их вычислительных характеристиках. Это означает, что энергопотребление кластеров обработки может быть оптимизировано путем знания различных требований к обработке различных задач LLM и изменения этих требований со временем. Например, различные виды запросов могут потребовать различного количества вычислительной мощности; эти различия можно использовать для снижения энергопотребления без ущерба функциональности.
Фреймворк DynamoLLM
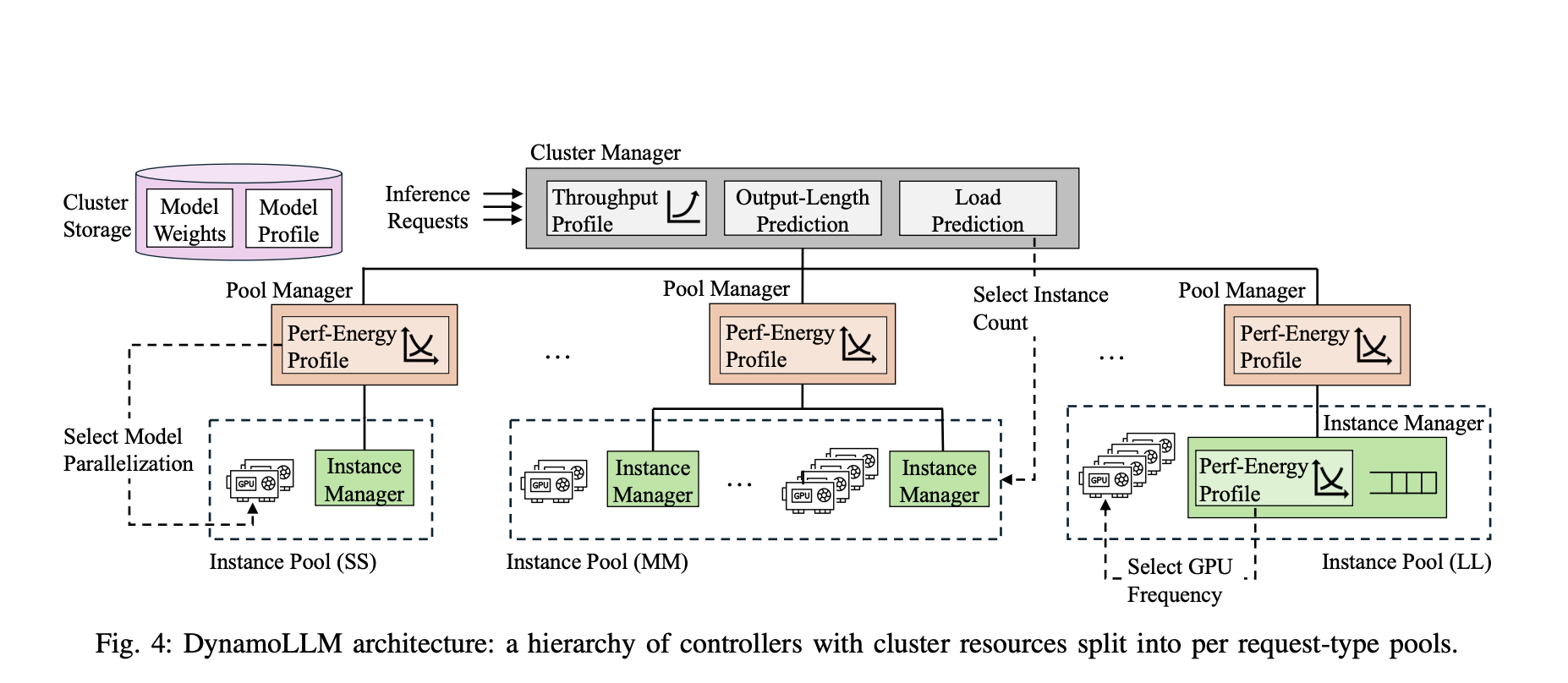
В ответ на эти ограничения команда исследователей из Университета Иллинойса в Урбане-Шампейне и Microsoft создала уникальный фреймворк управления энергией под названием DynamoLLM, предназначенный для использования в контекстах обработки LLM. С целью оптимизации потребления энергии и затрат, DynamoLLM создан для автоматического и динамического пересмотра конфигураций кластеров обработки, гарантируя при этом выполнение SLO производительности услуги. Это означает, что DynamoLLM находит лучшие потенциальные компромиссы между вычислительной мощностью и энергоэффективностью, непрерывно мониторируя производительность системы и корректируя конфигурацию по мере необходимости.
Ключевые характеристики кластеров обработки, влияющие на производительность DynamoLLM, включают количество запущенных экземпляров, степень параллелизма модели среди GPU и частоту операций GPU. Путем настройки этих параметров в реальном времени DynamoLLM может значительно сократить потребление энергии и выбросы углерода, не жертвуя качеством обслуживания. В частности, было продемонстрировано, что DynamoLLM может сэкономить до 53% энергии, обычно требуемой кластерами обработки LLM на уровне обслуживания. Он также может снизить цены для потребителей на 61% и выбросы углерода на 38%, сохраняя при этом требуемые уровни SLO задержки для гарантирования продолжительной эффективности и отзывчивости услуги.
Заключение
DynamoLLM представляет собой значительное достижение в деле улучшения устойчивости и экономики LLM, решая финансовые и экологические проблемы в быстро развивающейся области искусственного интеллекта.
«`

























