Michelangelo: Искусственный Интеллект для Оценки Долгосрочного Рассуждения в Больших Языковых Моделях
Практические Решения и Ценность:
В области искусственного интеллекта и обработки естественного языка долгосрочное рассуждение стало ключевым направлением исследований. Машины должны уметь синтезировать и извлекать необходимую информацию из огромных наборов данных. Это требует способности моделей находить конкретные фрагменты информации и понимать сложные взаимосвязи в обширных контекстах. Возможность рассуждать в долгих контекстах необходима для функций, таких как резюмирование документов, генерация кода и анализ данных в масштабах, что является ключевым для прогресса в области ИИ.
Основным вызовом, с которым сталкиваются исследователи, является необходимость более эффективных инструментов для оценки понимания долгих контекстов в больших языковых моделях. Большинство существующих методов сосредоточены на поиске, где задача ограничивается нахождением одного фрагмента информации в огромном контексте, похоже на поиск иголки в стоге сена. Однако простой поиск не полностью тестирует способность модели понимать и синтезировать информацию из больших наборов данных. По мере увеличения сложности данных критично измерять, насколько хорошо модели могут обрабатывать и связывать разрозненные фрагменты информации, а не просто полагаться на простой поиск.
Текущие подходы недостаточны, потому что они часто измеряют изолированные возможности поиска, а не более сложное умение синтезировать соответствующую информацию из большого непрерывного потока данных. Популярный метод, называемый задачей «иголка в стоге сена», оценивает, насколько хорошо модели могут найти конкретные данные. Однако этот подход не тестирует способность модели понимать и обрабатывать несколько связанных фрагментов данных, что приводит к ограничениям в оценке их истинного потенциала долгосрочного рассуждения. Хотя недавние бенчмарки дали некоторое представление о способностях этих моделей, их критикуют за ограниченный охват и неспособность измерить глубокое рассуждение в больших контекстах.
Исследователи из Google DeepMind и Google Research представили новый метод оценки под названием Michelangelo. Эта инновационная структура тестирует долгосрочное рассуждение в моделях с использованием синтетических, не утекших данных, обеспечивая сложные и актуальные оценки. Фреймворк Michelangelo фокусируется на понимании долгих контекстов через систему под названием Latent Structure Queries (LSQ), которая позволяет модели выявлять скрытые структуры в большом контексте, отбрасывая ненужную информацию. Исследователи стремятся оценить, насколько хорошо модели могут синтезировать информацию из разрозненных фрагментов данных по всему обширному набору данных, а не просто находить изолированные детали. Michelangelo вводит новый набор тестов, который значительно улучшает традиционный подход поиска «иголки в стоге сена».
Фреймворк Michelangelo включает три основные задачи: Latent List, Multi-Round Coreference Resolution (MRCR) и задачу IDK. Задача Latent List включает представление последовательности операций на Python модели, требуя от нее отслеживать изменения в списке и определять конкретные результаты, такие как суммы, минимумы или длины после множества модификаций списка. Эта задача разработана с увеличивающейся сложностью, начиная с простых одношаговых операций и заканчивая последовательностями, включающими до 20 соответствующих модификаций. С другой стороны, MRCR вызывает модели обрабатывать сложные диалоги, воспроизводя ключевые фрагменты информации, встроенные в длинный диалог. Задача IDK тестирует способность модели определить, когда у нее недостаточно информации для ответа на вопрос. Обеспечение того, что модели не выдают неточные результаты на основе неполных данных, имеет важное значение.
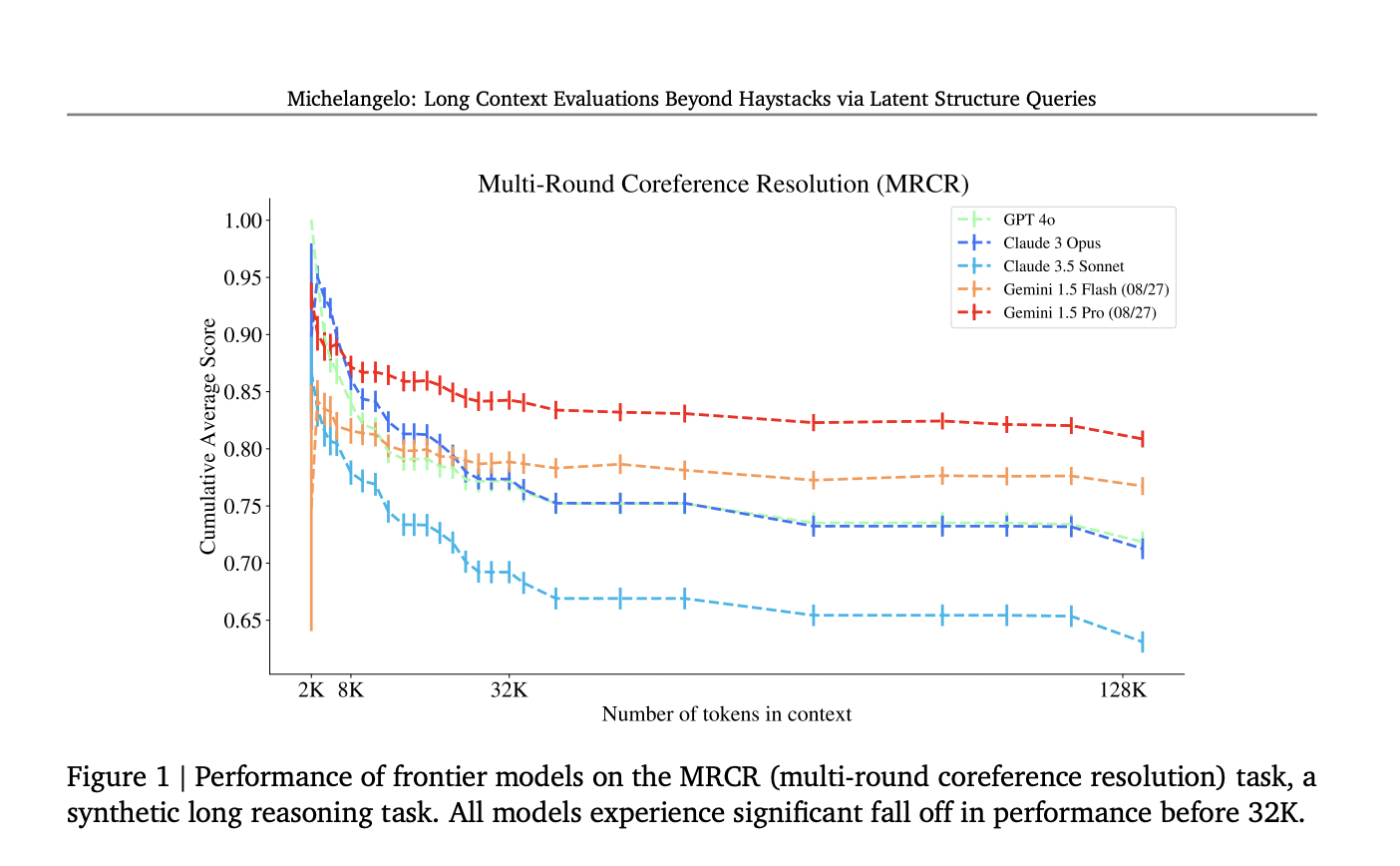
С точки зрения производительности фреймворк Michelangelo предоставляет подробные инсайты в то, насколько хорошо текущие модели на передовом крае справляются с долгосрочным рассуждением. Оценки моделей, таких как GPT-4, Claude 3 и Gemini, показывают значительные различия. Например, все модели испытывали значительное падение точности при выполнении задач, включающих более 32 000 токенов. На этом пороге модели, такие как GPT-4 и Claude 3, показали крутой спад, с накопительным средним баллом, упавшим с 0,95 до 0,80 для GPT-4 в задаче MRCR при увеличении числа токенов с 8K до 128K. Claude 3.5 Sonnet показало схожую производительность, снижая баллы с 0,85 до 0,70 в том же диапазоне токенов. Интересно, модели Gemini показали лучшие результаты в длинных контекстах, причем модель Gemini 1.5 Pro продемонстрировала неубывающую производительность до 1 миллиона токенов как в задаче MRCR, так и в задаче Latent List, превзойдя другие модели, поддерживая кумулятивный балл выше 0,80.
В заключение, фреймворк Michelangelo представляет долгожданное улучшение в оценке долгосрочного рассуждения в больших языковых моделях. Смещая фокус с простого поиска на более сложные задачи рассуждения, этот фреймворк ставит перед моделями более высокие требования, синтезируя информацию по всему обширному набору данных. Эта оценка показывает, что хотя текущие модели, такие как GPT-4 и Claude 3, испытывают трудности с долгосрочными задачами, модели, такие как Gemini, демонстрируют потенциал сохранения производительности даже с обширными данными. Введение исследовательской командой фреймворка Latent Structure Queries и детальные задачи в Michelangelo выдвигают границы измерения понимания долгих контекстов и подчеркивают вызовы и возможности в развитии способностей рассуждения в области ИИ.